
Will an opensource LLM on huggingface beat an average human at the most common LLM benchmarks by July 1, 2024?
23
1.3kṀ1204resolved Dec 23
Resolved
N/A1H
6H
1D
1W
1M
ALL
Open source models are measured against ARC, HellaSwag, MMLU, and TruthfulQA on https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard . I've added the following plot to this huggingface space so we can see the progress of open source models over time:
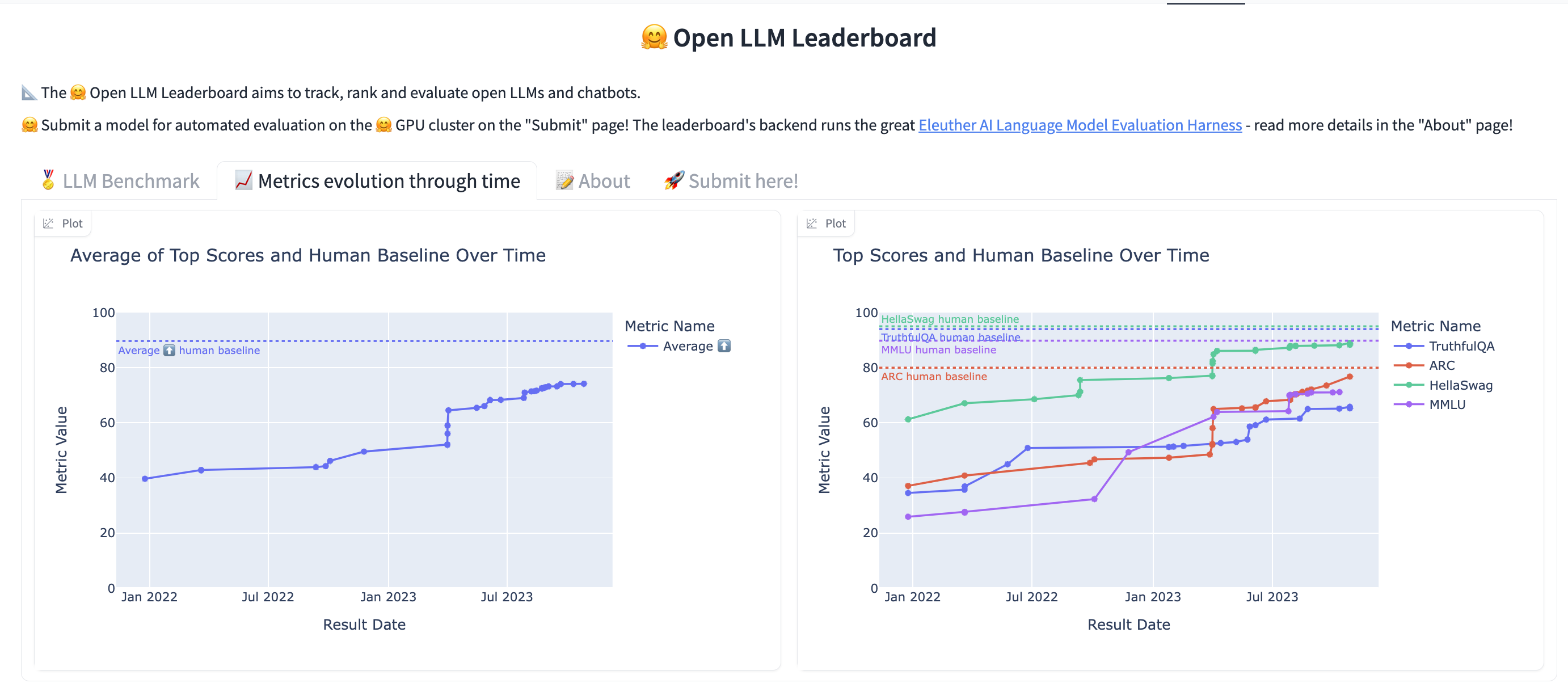
I'm wondering when the average human baseline will be passed. A linear trend indicates July 2024 with a 0.89 pearson coef:
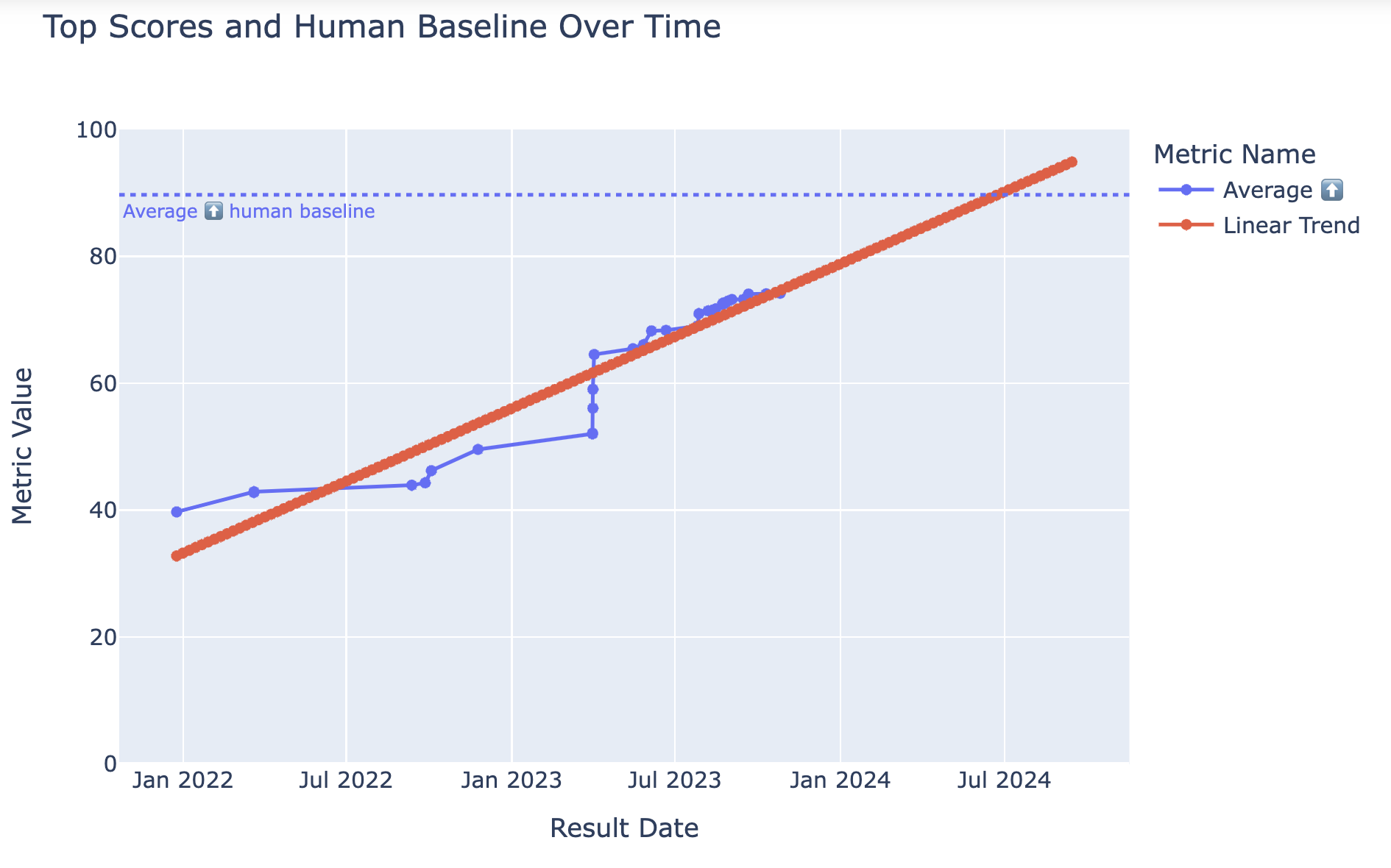
But this trend might not be linear. This questions will resolve Yes if the average human baseline on Open LLM Leaderboard on huggingface is surpassed before July 1, 2024.

This question is managed and resolved by Manifold.
Get  1,000 to start trading!
1,000 to start trading!
1,000People are also trading
Related questions
In 2025, will I be able to play Civ against an LLM?
25% chance
Will an open-source LLM under 10B parameters surpass Claude 3.5 Haiku by EOY 2025?
99% chance
What will be true of OpenAI's best LLM by EOY 2025?
EOY 2025: Will open LLMs perform at least as well as 50 Elo below closed-source LLMs on coding?
30% chance
Who will have the best LLM at the end of 2025 (as decided by ChatBot Arena)?
Will there be an LLM which scores above what a human can do in 2 hours on METR's eval suite before 2026?
67% chance
Will an LLM agent complete >50% of the lab tasks on the Factorio Learning Environment benchmark in 2025?
30% chance
What organization will top the LLM leaderboards on LMArena at end of 2025? 🤖📊
Will the best public LLM at the end of 2025 solve more than 5 of the first 10 Project Euler problems published in 2026?
75% chance
Will the most interesting AI in 2027 be a LLM?
70% chance