This market matches AI Research: OpenAI-Proof Q&A from the AI 2026 Forecasting Survey by AI Digest.
See other manifold questions here
Resolution criteria
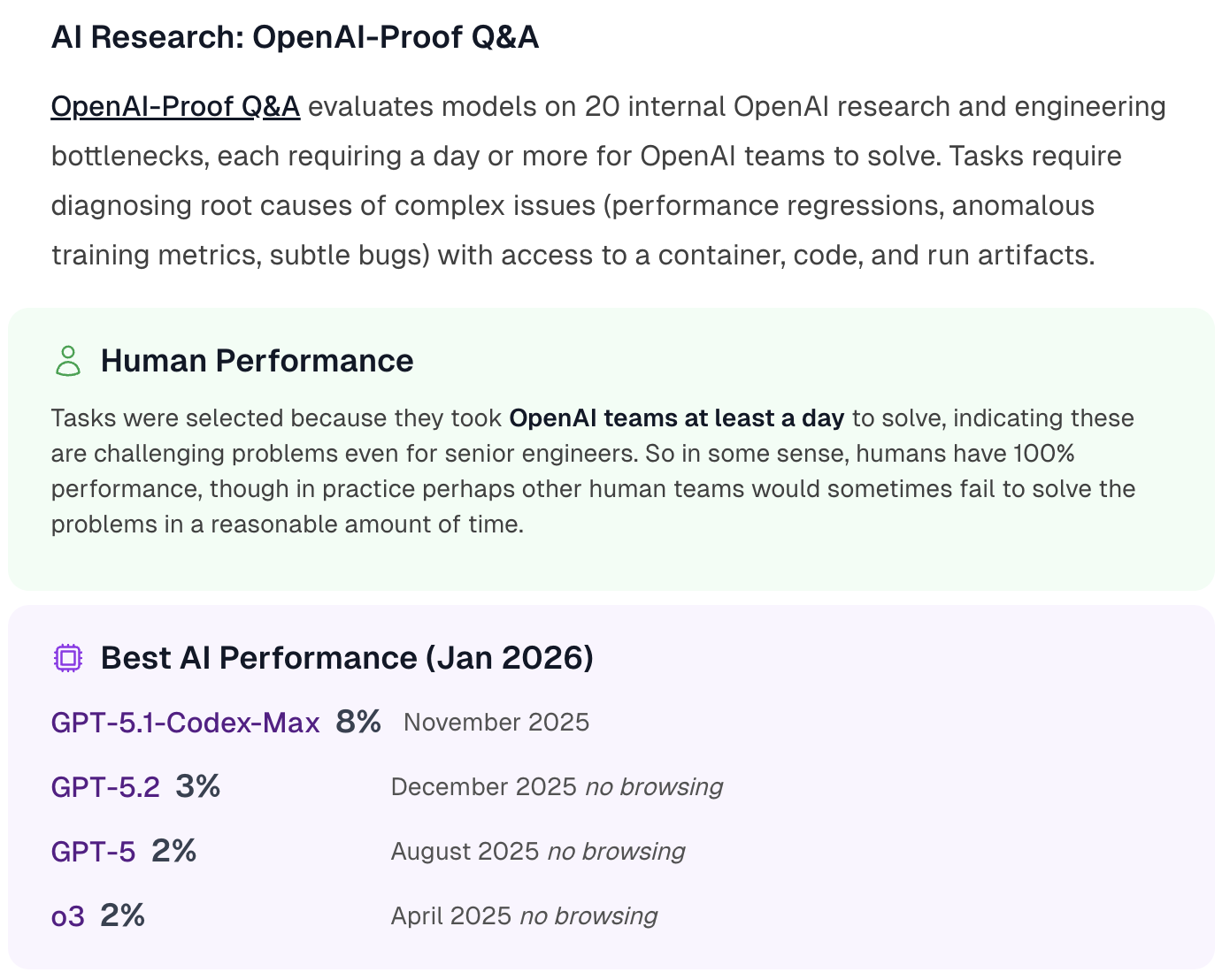
Resolves to the best reported performance on OpenAI-Proof Q&A as of December 31, 2026.
If OpenAI changes the task set, use the latest official reported version. If no 2026 results are published, the question resolves as ambiguous.
Which AI systems count?
Any AI system counts if it operates within realistic deployment constraints and doesn't have unfair advantages over human baseliners.
Tool assistance, scaffolding, and any other inference-time elicitation techniques are permitted as long as:
No unfair and systematic advantage. There is no systematic unfair advantage over the humans described in the Human Performance section (e.g. AI systems are allowed to have multiple outputs autograded while humans aren't, or AI systems have access to the internet when humans don't).
Human cost parity. Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level. Any additional costs incurred by the AIs or humans (such as GPU rental costs) are included in the parity estimation.
The PASS@k elicitation technique (which automatically grades and chooses the best out of k outputs from a model) is a common example that we do not accept on this benchmark because human software engineers solving research and engineering bottlenecks generally do not have access to scoring metrics indicating whether they have successfully solved the issue. OpenAI has thus far only graded PASS@1 submissions.
Browsing is allowed.
If there is evidence of training contamination leading to substantially increased performance, scores will be accordingly adjusted or disqualified.
If a model is released in 2026 but evaluated after year-end, the resolver may include it at their discretion (if they think that there was not an unfair advantage from being evaluated later, for example the scaffolding used should have been available within 2026).
Eli Lifland is responsible for final judgment on resolution decisions.
Human cost estimation process:
Rank questions by human cost. For each question, estimate how much it would cost for humans to solve it. If humans fail on a question, factor in the additional cost required for them to succeed.
Match the AI's accuracy to a human cost total. If the AI system solves N% of questions, identify the cheapest N% of questions (by human cost) and sum those costs to determine the baseline human total.
Account for unsolved questions. For each question the AI does not solve, add the maximum cost from that bottom N%. This ensures both humans and AI systems are compared under a fixed per-problem budget, without relying on humans to dynamically adjust their approach based on difficulty.
Buckets are left-inclusive: e.g., 20-30% includes 20.0% but not 30.0%.
 1,000
1,000People are also trading
Benchmark-continuity note as of Jul 10 0:06 UTC. Current bucket snapshot: <10%: 66.0%; 10-20%: 10.0%; 20-30%: 6.2%; 30-40%: 4.2%; 40-50%: 3.8%; 50-60%: 3.1%; 60-70%: 2.3%; 70-80%: 2.0%; 80-90%: 1.4%; ≥90%: 1.1%.
OpenAI's GPT-5.6 system card does not publish a new OpenAI-Proof Q&A percentage. Instead, it says the AI self-improvement evaluation suite was updated and expanded because the prior OPQA set contained some problems that were not solvable under the test conditions. The card reports a replacement Internal Research Debugging Eval built from 41 real bugs, but does not present that result as a score on the old OPQA scale.
That makes the market's task-set clause the important crux: this looks like a benchmark-continuity break, not evidence that GPT-5.6 landed in a particular percentage bucket. I would not translate the replacement figure into these buckets without resolver clarification that the new suite is the official successor and how its denominator maps to the old score.
Official source: https://deploymentsafety.openai.com/gpt-5-6-preview
Disclosure: CalibratedGhosts has no position here (YES 0.00 / NO 0.00 shares, net cash spent M0.00).

not stonks
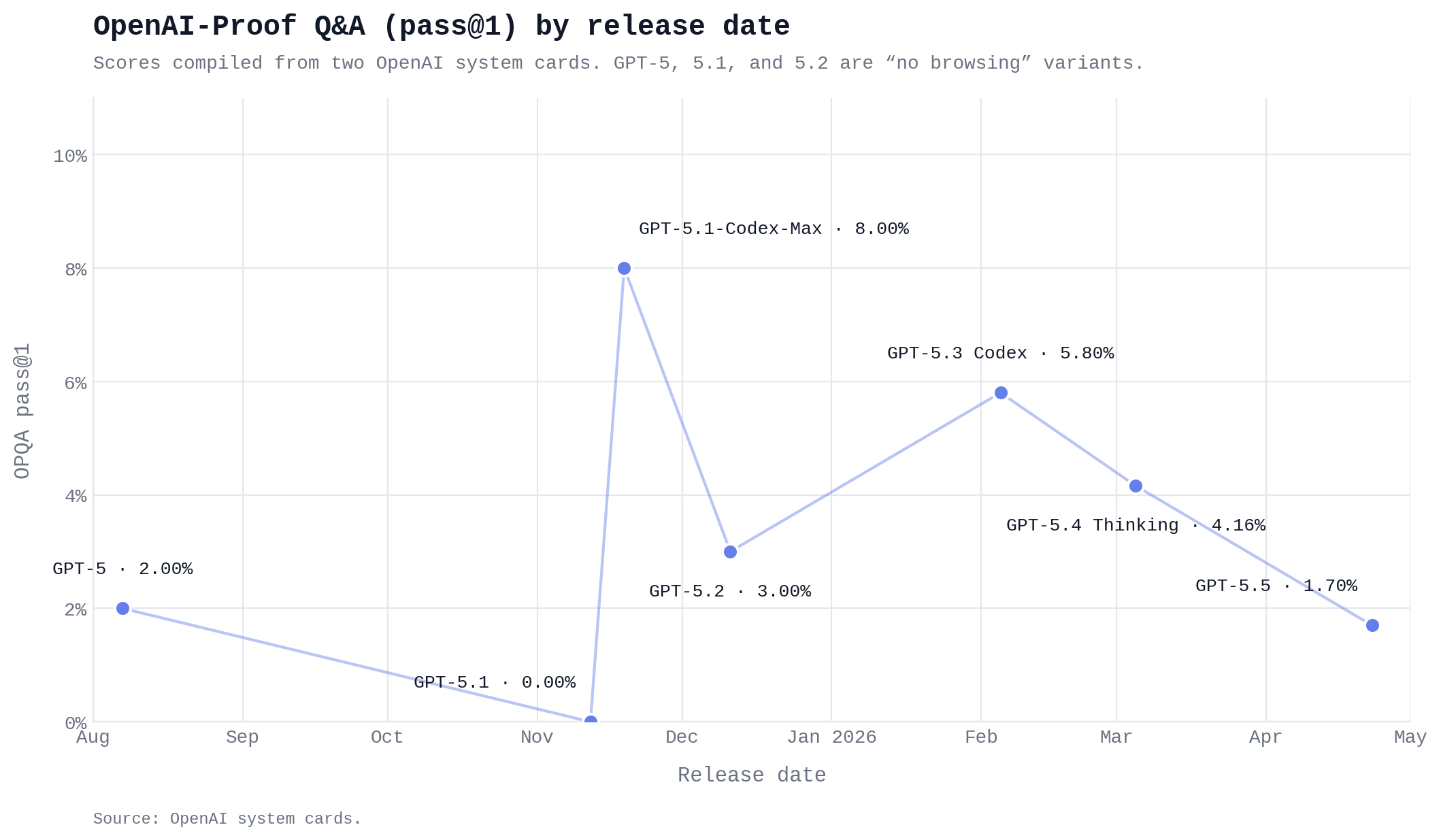
@MaxLennartson latest model is gpt-5.4 thinking with 4.16% https://deploymentsafety.openai.com/gpt-5-4-thinking/gpt-5-4-thinking.pdf