
Meaning an algorithm that can take an LLM as input and out a new language model with <=75% of the original model's parameters (and comparable performance, of course).
Must actually be demonstrated to work on a non-specialized language model with >=10B parameters (e.g. by downloading an open source foundation model and compressing that)
If there already is such an algorithm and I just don't know about it market will still resolve YES.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ423 | |
| 2 | Ṁ17 | |
| 3 | Ṁ9 | |
| 4 | Ṁ9 | |
| 5 | Ṁ9 |
People are also trading
Resolving YES based on SparseGPT. The 2:4 sparse version achieves the desired compression ratio and comparable accuracy to OPT-175B. The 50% sparsity version may also resolve it, but they do not actually evaluate it in terms of compression ratio (or GPU performance, which they should have). Thanks to @ampdot for linking the paper.
(Note for posterity that I am using the actual on-disk compression ratio to resolve the market, not the sparsity ratio which is generally going to be different).
@ampdot I will not resolve YES based solely on perplexity results, and I have not had time to review the other results yet.
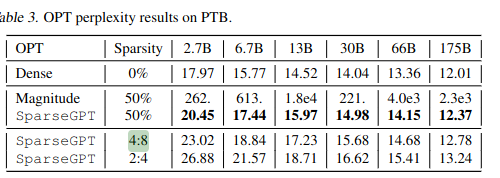
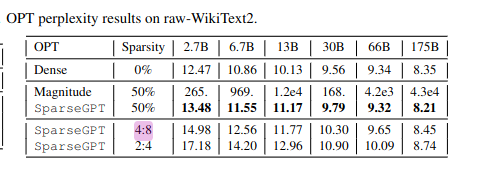
https://neuralmagic.com/blog/sparsegpt-remove-100-billion-parameters-for-free/ reduces parameters by 50%
