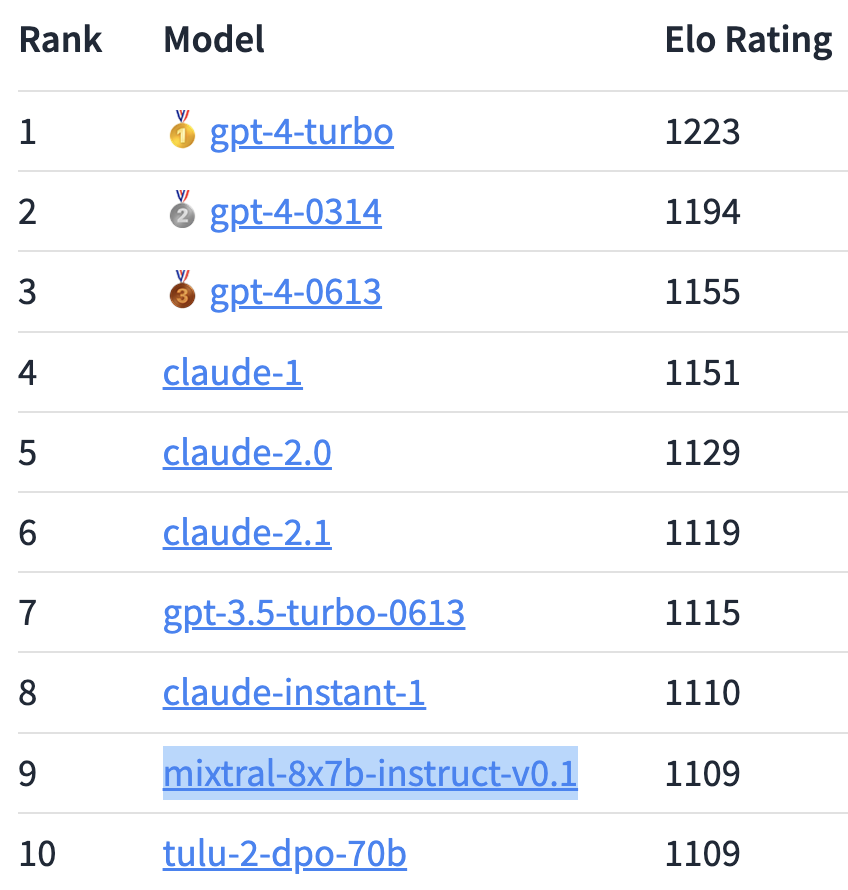
I was browsing Twitter, and I saw a post by Karpathy positively talking about ChatBot Arena, which is a platform for ranking LLMs based on human ratings. As expected, OpenAI is holding positions 1, 2, and 3. I wonder which company will be #1 at the end of 2024.
Screenshot of the rankings table taken on the 13th of December:
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ50,453 | |
| 2 | Ṁ25,754 | |
| 3 | Ṁ16,236 | |
| 4 | Ṁ8,806 | |
| 5 | Ṁ7,608 |
People are also trading
@traders Based on the comments below, I think it makes sense to resolve this question based on the ELO rating in case of a tie in "rank." When I created this question, a tie was not an option, so I doubt anyone even traded based on this assumption.
I created a similar question that only uses the rank. Feel free to trade on it.
Gemini flash 2.0 strawberry in the api
https://ai.google.dev/gemini-api/docs/thinking-mode
10k limit order @75% for anyone feeling brave
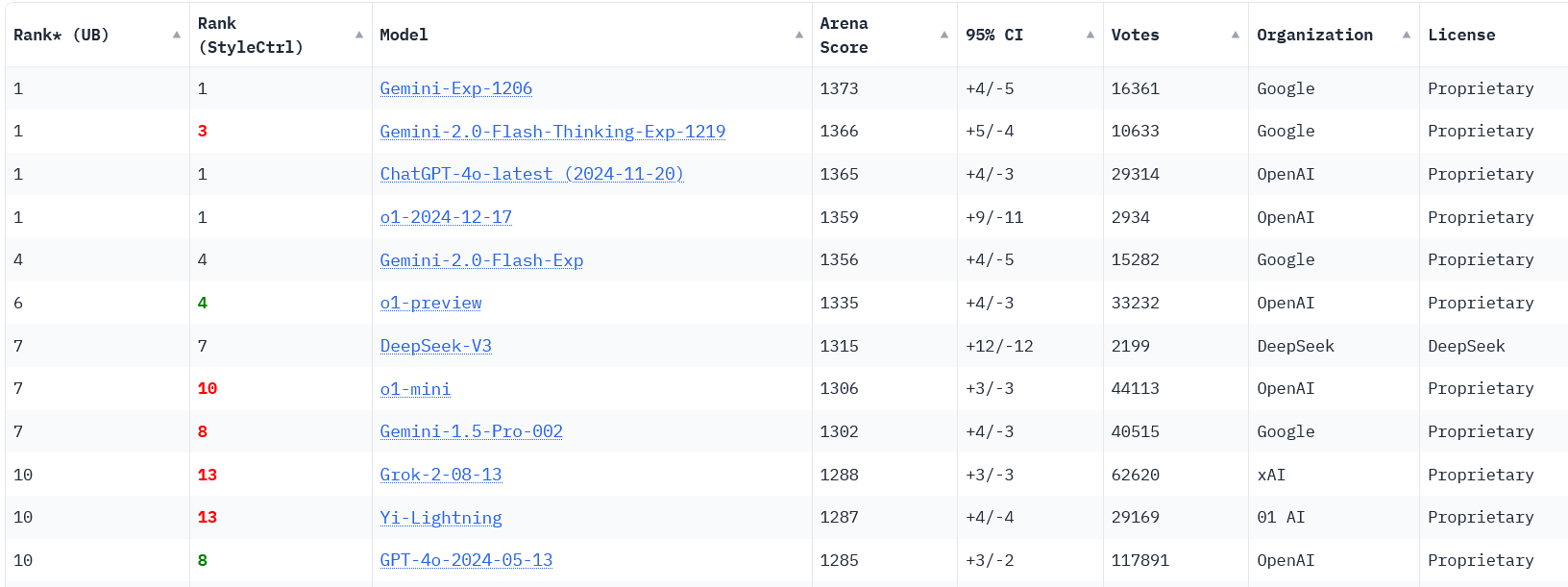
@WillSorenson it is slightly short of exp 1206. Are you assuming a thinking 1206 will be added?
@Usaar33 It appears more pleasant than o1 to me so it makes it unlikely o1 will top the charts. The following all have to go right for OAI to win:
1. They have to release a new model today
2. It has to actually be better in the dimensions that chatbot arena evaluates
3. Chatbot arena has to update it in time.
Possible! Not more than a 20% chance.
@jim I’m also the second biggest xAi yes holder! Until December I was v bearish against google and thought the relative lack of censorship of grok would win out when chatbots were broadly good enough to answer most questions. I changed my mind when events turned against me
@NeuralBets i would give it a 80/90% that OpenAI releases a new model as part of their 12 day of christmas but I am not sure they will make it available to LMSYS before end of the year - i am too deep at this point anyways so 🤷♂️
@Bayesian right now this position represents ~80% of my mana net worth but i am doubling down and put a large limit order at 40% on openai
@Soli it should be said that new model doesn’t mean that it will become N1. Reason 1: google may have fine tuned to perform way better on lmsys. Reason 2: google may have another fine tuned ready to answer any score release from OAI. Maybe google ceo and PM have their compensation tied to end-year perfomance on LMSYS
@mathvc true, openai released the new preview model over the api yesterday (which is still not ranked in LMSYS) and I expect another major announcement sooon so we shalll seee how it goes
@mathvc I think it's more a question of how often the leader board is updated.
I agree with your stance, I just don't know if I want more exposure to this market with my novice level of understanding of the subject.