
I’m going to do my best to make this rigorous. This one is a bit fuzzy but it’s what I want to know the answer to.
This will resolve to yes if:
by the end of the day on 12/31/2024
a new class of ai model is released by anyone (not just OpenAI). The model must be in wide availability. Some gates are acceptable (e.g., paid users only, 10% of users), but it cannot be available to selected AI influencers.
that is a step change better in performance. For clarity: GPT-4 was a step change better than 3/3.5 and would qualify; Claude 3.5/GPT 4o are narrowly better than GPT-4 and would not. I will use my best judgement to resolve this honestly using all inputs available (benchmarks, test cases, user reports, reviews by expert users).
Names don’t matter here. It could be called GPT-1 but if it’s obviously way better than GPT-4/Claude 3.5, then the market resolves to yes.
Given the ambiguity here, I will not be betting on this market.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ4,067 | |
| 2 | Ṁ1,359 | |
| 3 | Ṁ1,008 | |
| 4 | Ṁ935 | |
| 5 | Ṁ643 |
Okay, here's where I've netted out on this:
o3 wasn't public by the end of the year, so impressive as it was, it doesn't count.
the o1 class of models is public enough to qualify
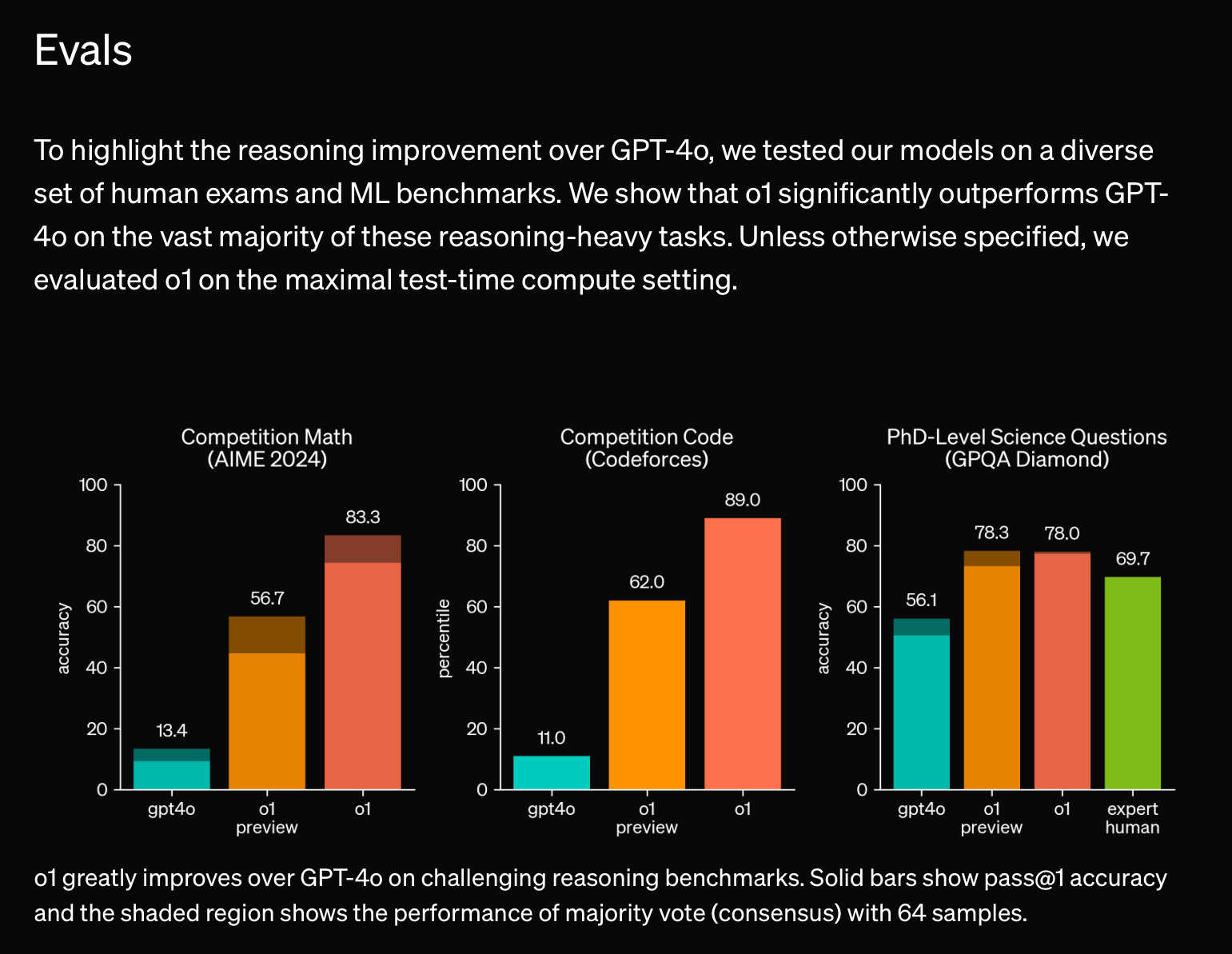
o1 and o1 pro do seem to be much better than the GPT4 class models at certain problems, but not all problems (see https://benediktstroebl.github.io/reasoning-model-evals/)
This is reflected in the usage of the "smart" AI users I see — a mixture of Claude / 4o and then periodically using o1 for problems where the GPT4 class models are failing
Based on this, I am resolving the market as "No"; the GPT4 class of models was so much better than the 3.5 models that you didn't have to qualify which problems they were and weren't good for, you should just use them if you could afford them.
If you think this is wrong, let me know why in the comments. I'm going to wait a couple of days to resolve this to see if there's an angle I'm missing here.
@jdilla oh. Obviously I disagree and bet as such, but defining "step change better" as "better in every use case" is a reasonable way to resolve the ambiguity in the market that was hit by the new architecture, even if I don't agree that "step change" needs to require "and no worse anywhere".
@JamesBaker3 appreciate the generosity of spirit here.
This one was tricky! Especially as I personally get a most of benefit from o1
This updates me higher on "step change" of capability: https://x.com/DeryaTR_/status/1865111388374601806
https://x.com/kimmonismus/status/1865118512764612958
This is absolutely not a dramatic improvement and may not be an improvement at all compared to Claude.
@ismellpillows I’m trying to figure out what to do with this
This more or less matches my experience - sometimes it’s way way better but other times it isn’t. I don’t recall having to qualify the step from 3.5 to 4 in the same way. 4 was just always better.
However I’m still thinking it over and I think with o1 being fully out I’ll get more information.
I see, some people’s experiences is that is it not always better than models like sonnet, whereas gpt-4 was always better than gpt-3.5. I’m curious which specific areas it is worse at.
The main way I judge models is on reasoning capability, which is what o1 class models are better at. People agree that o1 is much better at harder science and engineering problems for this reason. This is why I think it’s a “step change better”.
The main criticism I’ve seen is on the style of responses, writing, or code. I think when people compare models’ responses for easier problems, the main point of comparison is style. Style is dependent on reasoning capability up to a point, but after that point it is more dependent on the defaults of the model. And people prefer claude’s defaults over o1’s. But that doesn’t mean o1 is more incapable, and users can change style to their preference with a few sentences of prompting. (In fact, a model’s ability to change style from default is a sign of capability.)
Keep in mind sonnet is not gpt-4. On LLM arena leaderboard, gpt-4-0314 (the original gpt-4) is ~75 points above gpt-3.5. sonnet is already ~100 above gpt-4-0314, and o1-preview is ~50 above sonnet.
Also, afaik, the model they are offering as o1 is sometimes worse than o1-preview (similar to how gpt-4-0613 is ~25 points below gpt-4-0314). o1-pro is the real deal.
@ismellpillows I have been using it all day today alongside Claude for coding at my day job, and Claude has been better the whole time.
This is not some dramatic improvement for real world purposes (for my job, it is not an improvement at all.)
@DavidBolin could you give an example of a prompt and a comparison models’ responses? are you using o1-pro? are you using memory or a system prompt? trying to understand your general use case.
@ismellpillows
"How do I revise this React fragment so that the tooltip does not show up when you hover on "Add to Scratch Pad"? followed by React jsx.
Claude gives exact modifications.
o1 (no I have not paid $200 and won't although if they ever give a test period I'll try it) gave a generic description of how one would do it, although the code was right there.
Other cases were similar.
I see, so there’s a coding problem and you’d like the model to respond by writing code, which claude does and o1 doesn’t, right?
the way i see it, this is an example of what i previously called default “styles” of responses. claude defaults to writing code, o1 defaults to explanations instead, and you prefer claude’s default. (right?)
the reason i don’t think style the best way to compare models is that users can change the style from default to what they prefer, for example in this case by prompting “write code”. this applies to not preferring o1’s default writing style (eg listicles) or coding style. the user can change the style from default. having a certain default style doesn’t mean the model isn’t capable of other styles.
“capability” is what i think separates models. consider for example if we were to test models with the prompt “avoid writing code”. more capable models would follow this instruction better (but that may mean the style is actually less preferable). the best way to test capability is harder problems, which people agree o1 is much better at.
@ismellpillows Similar case today.
"Revise this calendar component so that rightmost segment of the calendar cell does not push the middle segment out of the way, and if there is not enough space for the full numbers to be shown, make sure the leftmost digits show with ellipsis on the right, while keeping the numbers generally right-aligned."
Full component is given to the model.
o1-pro gives generic advice, mostly ignoring the component.
Claude gives exact modifications to the code presented.
@JamesBaker3 Whew it's out now - feeling much more confident, doubled my position.
Here's Ethan Mollick, prolific AI reviewer and tester, today: https://x.com/emollick/status/1864871107095912767
@jdilla indeed. Given the inevitably of "the future never quite looks exactly as we envision it" I'm open to a resolve-to-percentage that aims to represent "mostly but not quite"
Okay folks, I'm starting to get back into a rhythm post baby and going to take a close look at o1 (at least this is what I tell myself).
Over the next several weeks, I'm going to make an assessment of o1 against the criteria above.
If you have reviews or analyses of it that you think are particularly persuasive, point me to them (I'll be looking at the ones in the comments as well).
Thanks for understanding on the delay. Timing could not have been worse!
@ismellpillows No.
I use it for work, and it is not substantially better than the others.
i.e. even if you can set up technical benchmarks where it is better, it is not much better for real world use cases. And that is absolutely not because there isn't a meaningful way to be substantially better for those cases; there certainly is, and I would recognize it if it happened.
@DavidBolin @ismellpillows fwiw, this is why I haven’t resolved the market yet.
On one hand the benchmarks look compelling but on the other hand I don’t see people flocking to it the way they did 4 (vs 3.5 and Claude).
I notice this both in my behavior and in the smart people I observe. So at the moment I’m trying to gather more information to make this more definitive and less of a pure judgement call.