
11am Monday (oct 14th) state of affairs:
Things started to deteriorate the night of oct 9th (PST)
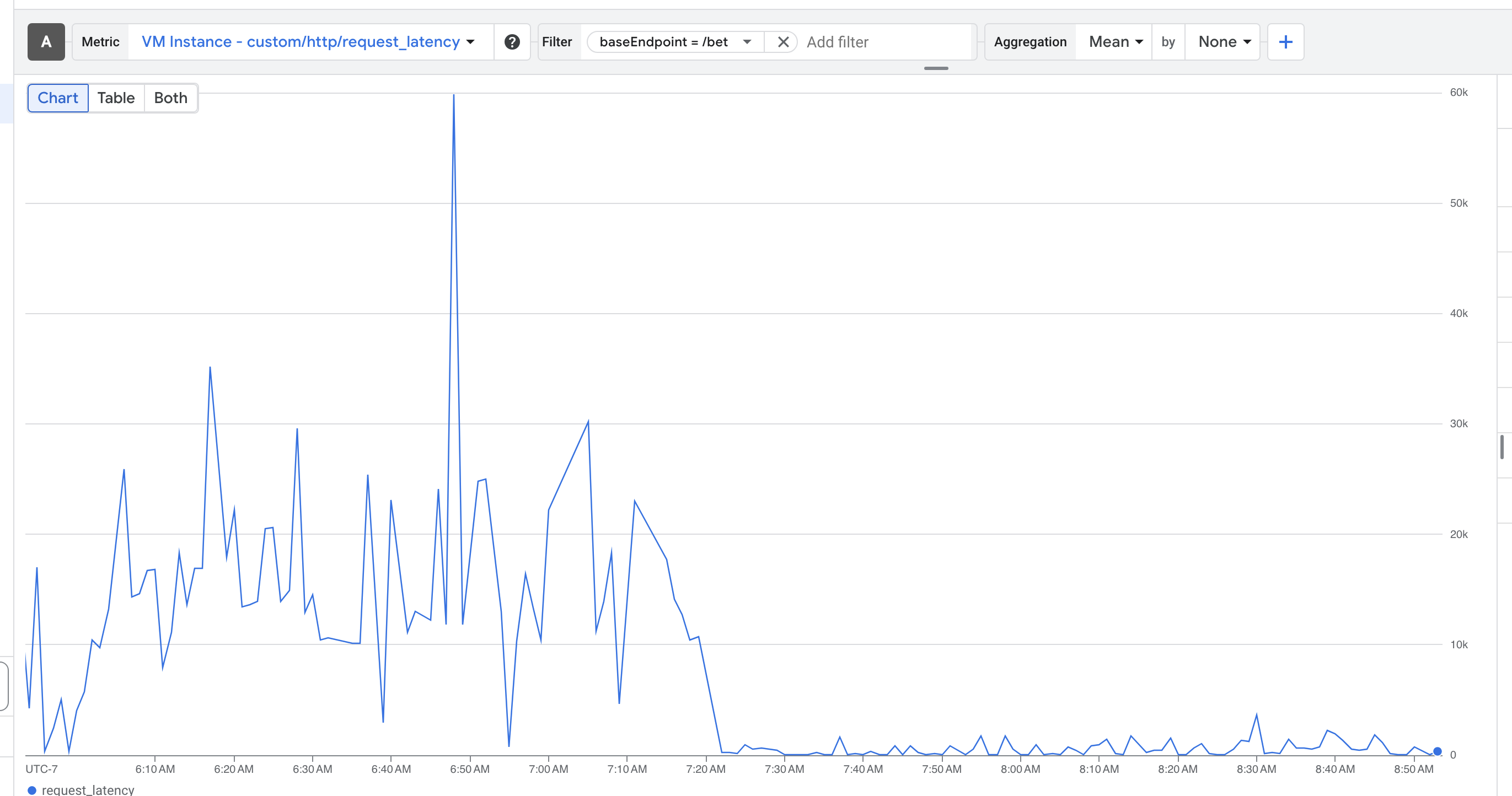
api latency slowly builds, leading to site outages every few hours
redeploying the api fixes things for a time
Local host works fine during the outage
simple queries start to take forever, filling up the connection pool
So far we've :
Set up a read replica that the front end uses when querying directly from the db with the supabase js library
updated our backend pg promise version
checked open connections on api (1.3k), total ingress/egress bytes, total api query numbers, memory usage (10%), all are normal.
Reverted suspicious-looking commits over the past few days
Increased, then decreased pg pool size
Moved some requests from api to the supabase js client that talked directly to the db's load balancer
Discovered that our server's CPU usage increases until it hits 100% of the single core running node's capabilty, and this coincides with our server's latency spikes.
Opened a PR to integrate datadog into our server to get some visibility into what is causing the cpu spikes.
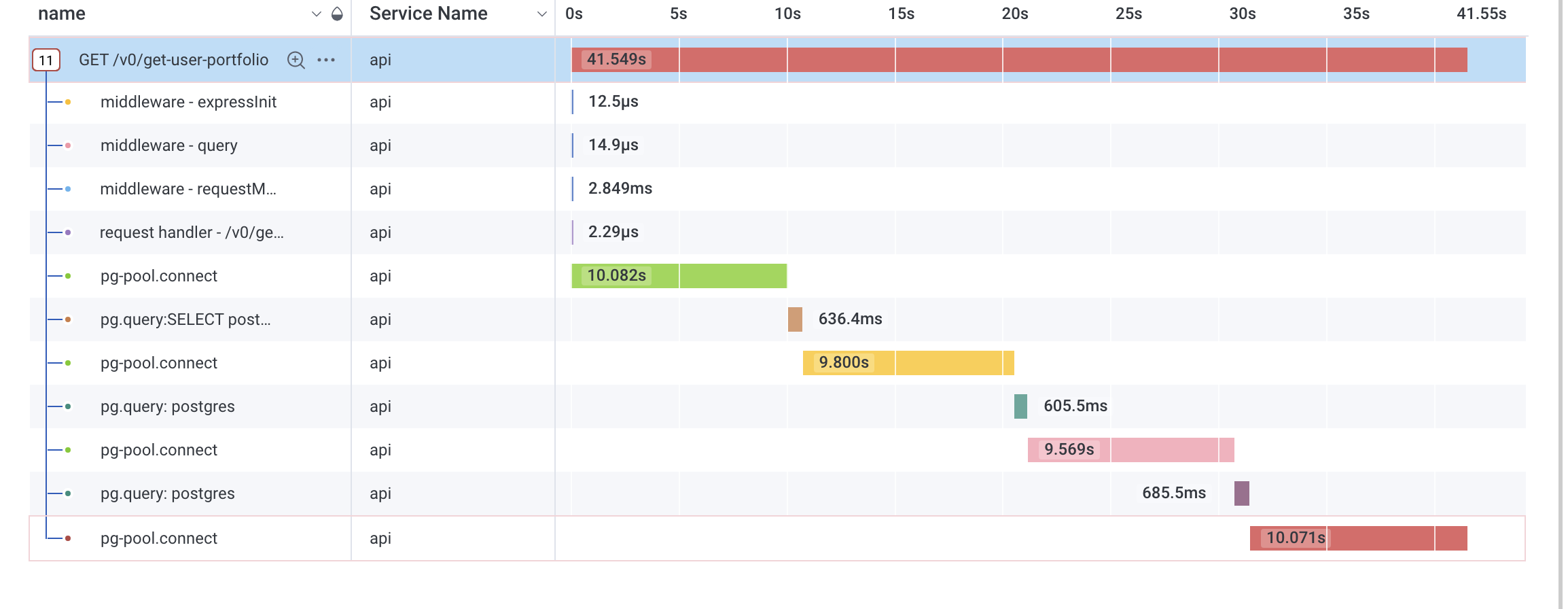
Typical API stats during an outage:
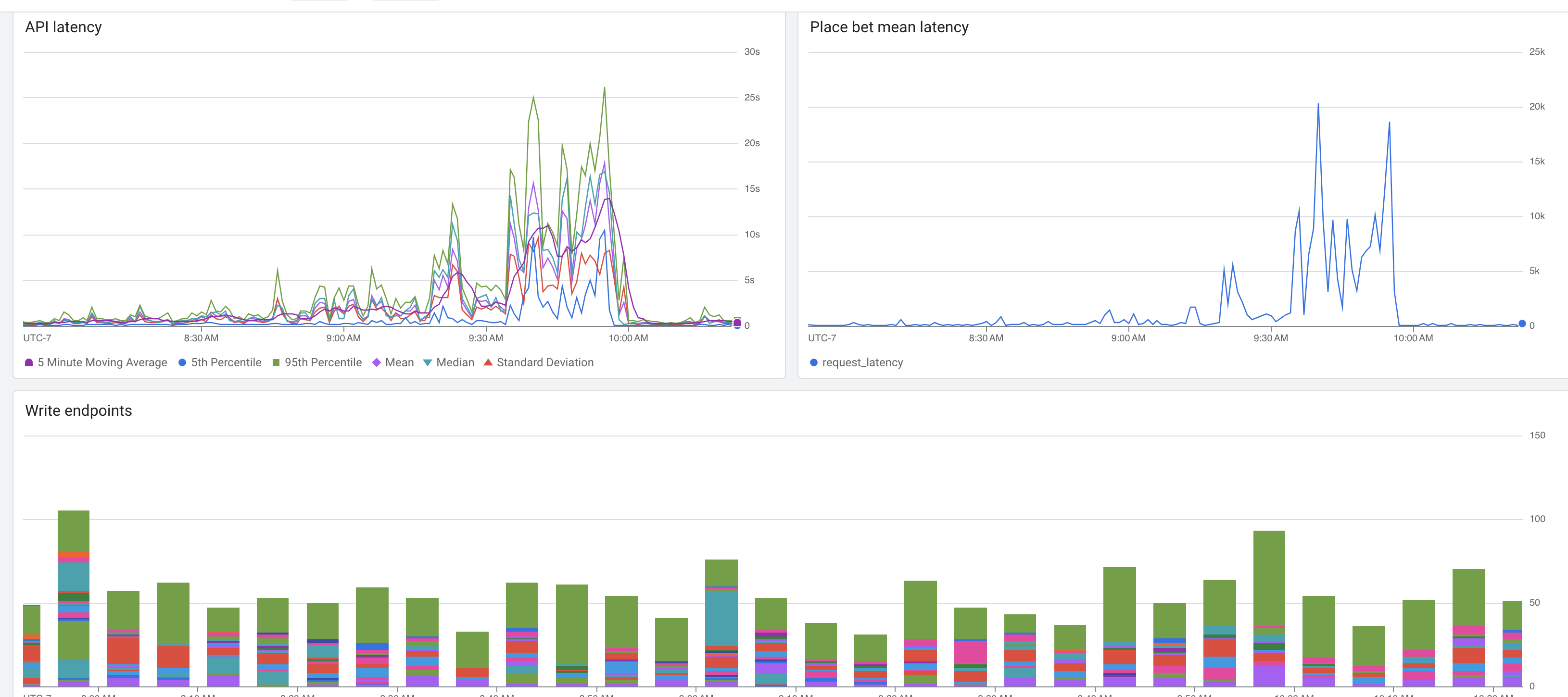
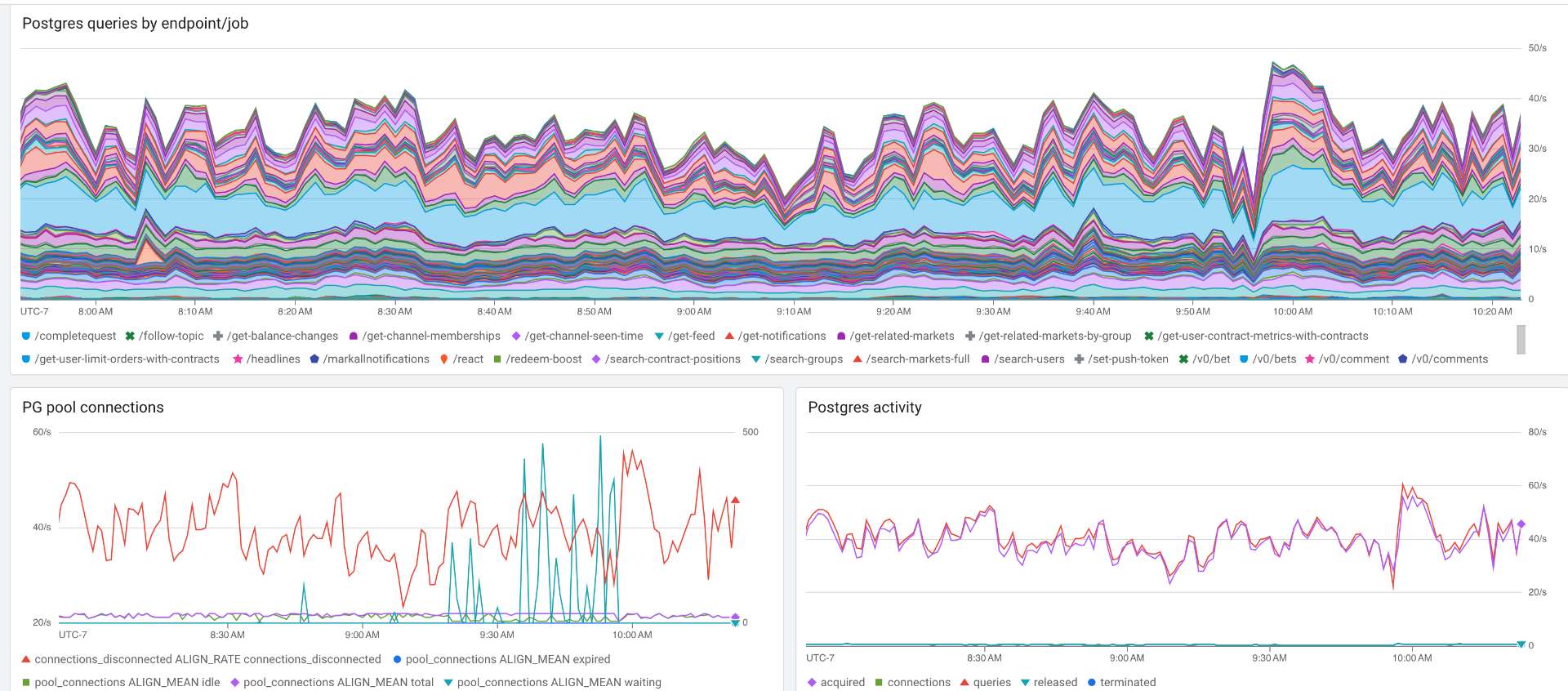
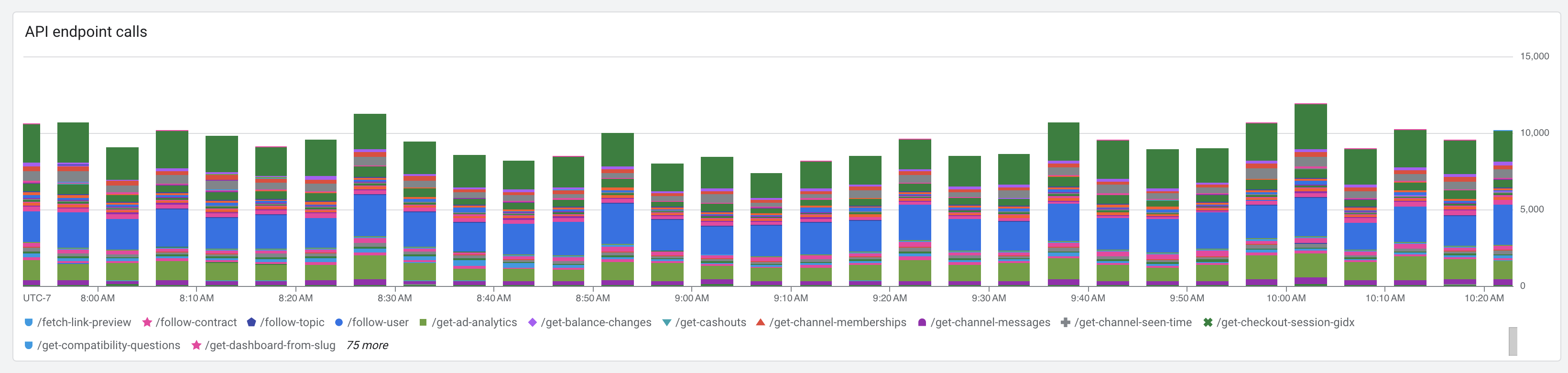

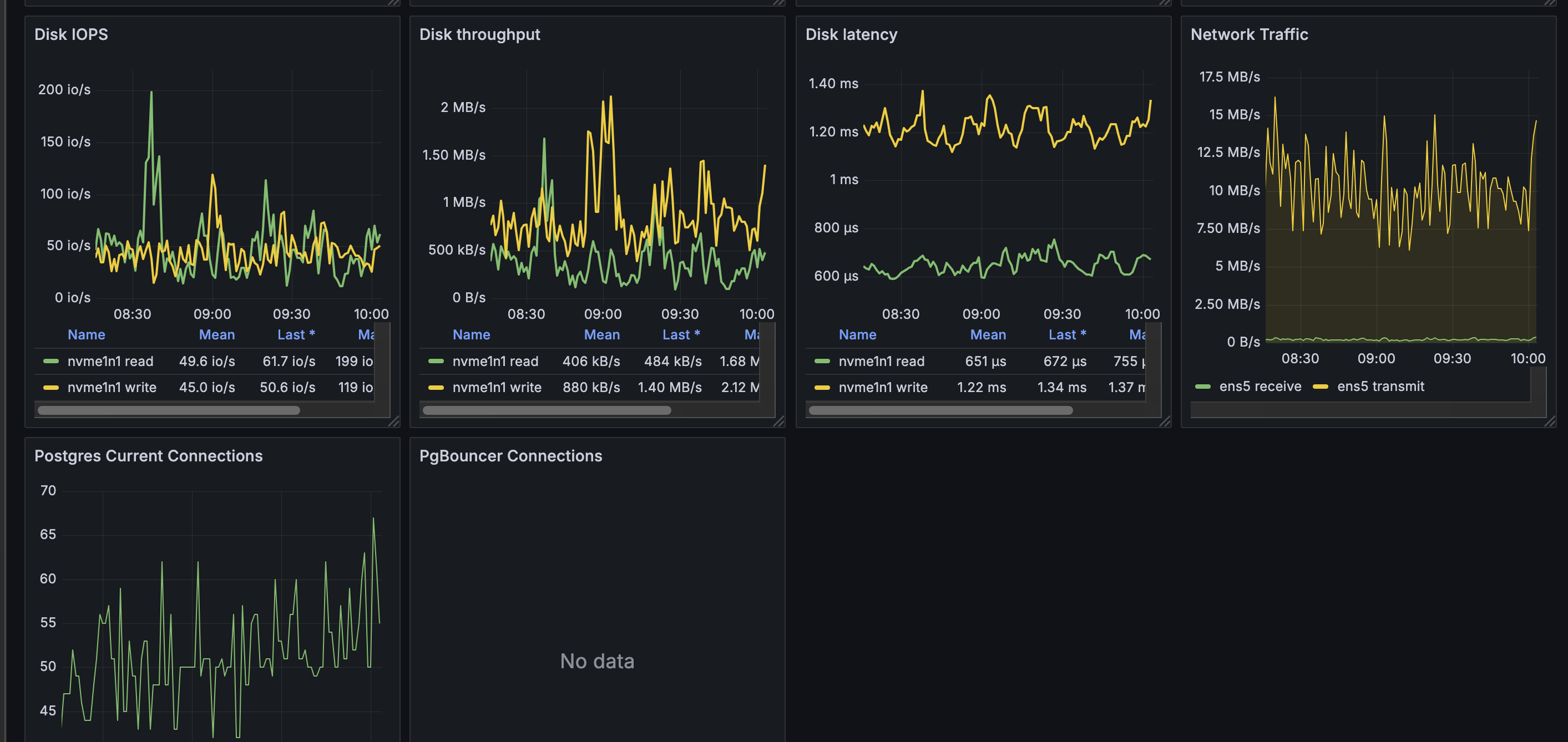
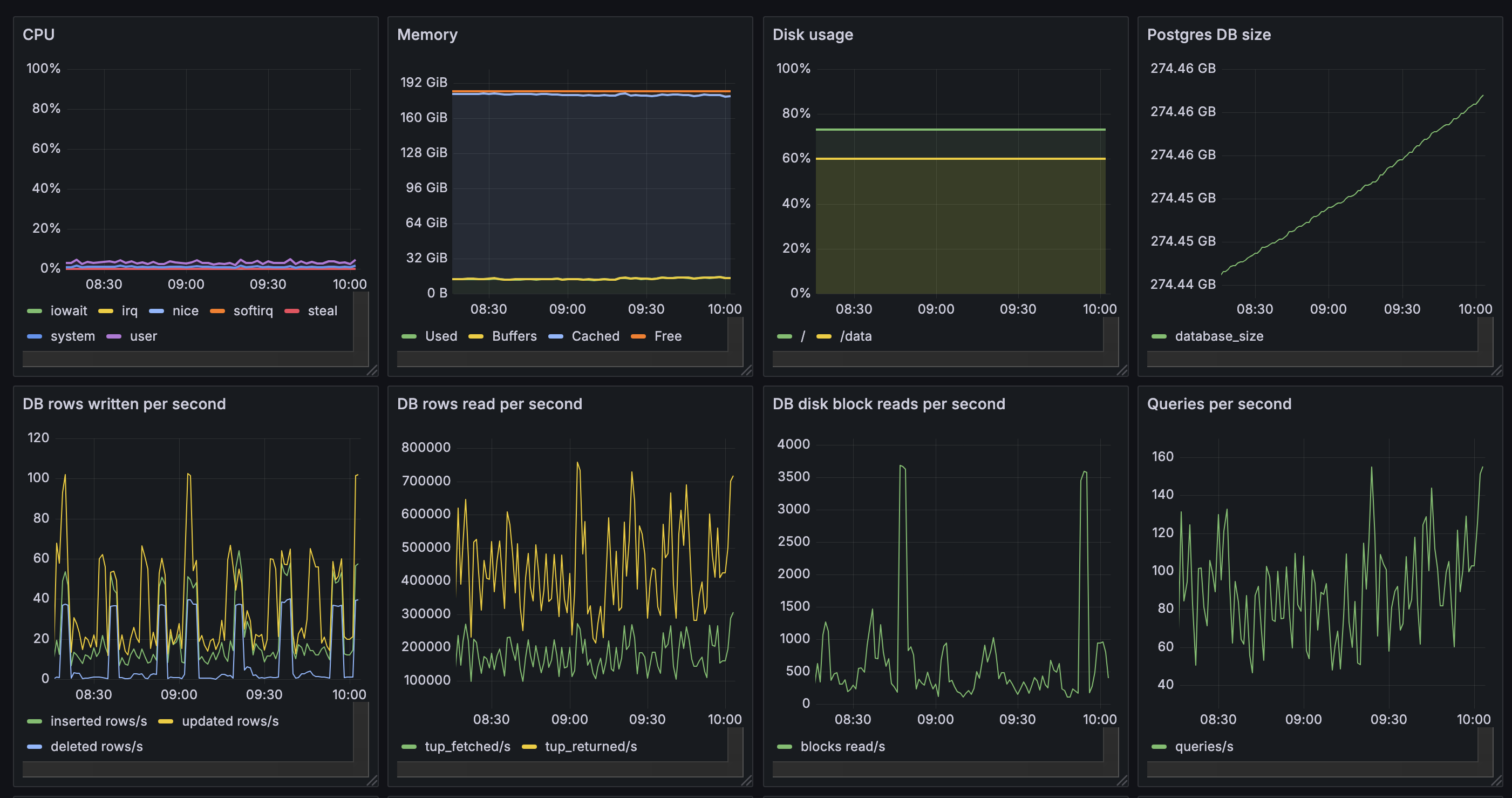
DB stats during an example outage:
I'm happy to provide more info, stats, etc.
repo: https://github.com/manifoldmarkets/manifold
previous market: https://manifold.markets/ian/will-we-fix-our-database-problems-b?play=true
This resolves as NO if we haven't fixed the underlying problem, i.e. even if we have a cron job restarting the server every hour
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ5,754 | |
| 2 | Ṁ4,343 | |
| 3 | Ṁ3,295 | |
| 4 | Ṁ1,748 | |
| 5 | Ṁ1,340 |
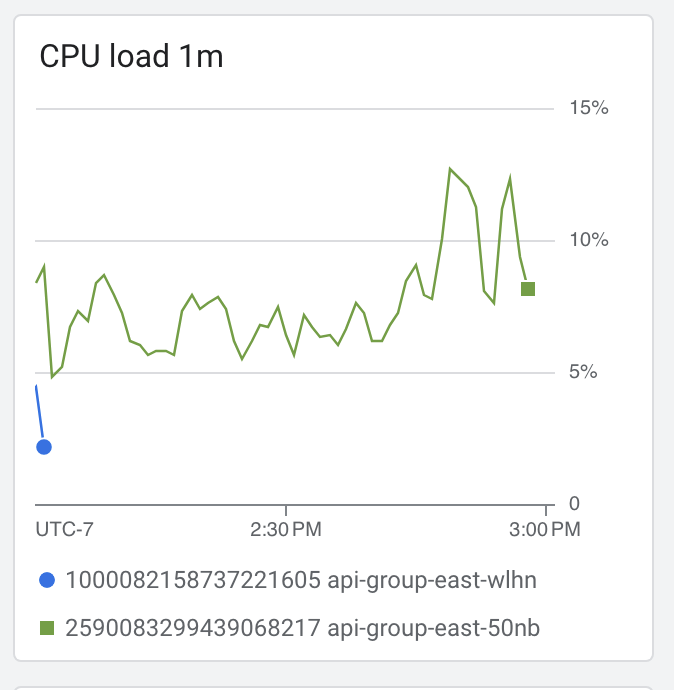
We're rolling back main (on main3) to a point in time on oct 7th to see if the problems are from commits made since then. I've pretty high confidence (50-60%) this will work.
@ian my money on this one lol https://github.com/manifoldmarkets/manifold/commit/74fec095eeb200156d7adbc60b41d780cac83d6b
@ian After an hour (when the server used to crash by now), it looks like things are still normal. So, using binary search we should only have a few more rollbacks to do before we find the culprit.
@ian How are things now, at the end of the day? Did you determine that the first attempted commit was 'good' and now you're trying another round?
@Eliza The cpu is not spiking quite as wildly as I was hoping, but the latency is up suspiciously. I'm pretty sure the commit is within this final batch of 18 commits, with 3 of them actually looking mildly suspicious.
@ian Put the commits into o1-mini along with a really long thorough description of the problem. Copy what you posted in this market stating what you tried.
Don't tell it to output code to fix the problem; it's not good at that. Instead, tell it to "take as much time as it needs" to "reason" through what could be the cause of the problem. I've found that it's exceptional at pointing out the cause of extremely hard to find bugs, and then you can use other models to write the code to fix them.
As long as I believe Manifold is unlikely to fix the problem within the specified timeframe without my input, I have incentive to cause the opposite outcome of whatever this market predicts, because I can deploy my liquidity most efficiently by betting for the minority position.
@ian How much memory is the database instance on? What kind of disk are you using? Have you tried increasing its memory to 64GB or more and upgrading the disk to one with more IOPS?
The memory "usage" of an instance in GCP likely does not reflect the size of the in-memory operating system level disk cache, which databases heavily rely on for performance.
@ampdot hey, the DB is fine, read here (and you have the graphs a couple posts up): https://manifold.markets/ian/will-we-fix-our-database-problems-b#rmrphy681w

Also, @Sinclair is having trouble integrating datadog, so we'd appreciate any advice anyone has there.
@ian @Sinclair hey, checked the PR, given you are using it as default, maybe just do import 'dd-trace/init'; instead before any other requires (or CLI? https://docs.datadoghq.com/tracing/trace_collection/automatic_instrumentation/dd_libraries/nodejs/#typescript-and-bundlers), if the issue is building the agent container or something else lmk
@Choms yeah i was following those setup instructions. I think the current way of doing it follows what they're asking for. My issue is that the Dockerfile doesn't work and I'm not really sure what it should be. the setup examples all just run the docker command directly. maybe I need to deploy two seperate containers for datadog and the api? but will it still be able to profile nodejs in a separate container?
(for those following along here's the pr)
@ampdot yeah I am open to a much more hand-managed simple solution rather than this enterprise saas-shit
@Sinclair you can spin a separate container or just install the agent on the host and get most host metrics by default, and it is enterprise saas (which is itself cringe) but I disagree on the shit part, it's actually the best thing you can get for monitoring, the downside as I told Ian is that the pricing is nuts and it goes expensive fast. With more time you probably want to look into something else (new relic is more reasonable or something open telemetry like amp said that you can host), the datadog idea was just a quick suggestion to get some telemetry going :)