Consider the following market from Scott Alexander:
https://manifold.markets/ScottAlexander/in-2028-will-gary-marcus-still-be-a
I'm questioning whether we're already there. This market resolves YES if anyone can provide a pure-text request that o3 answers worse than a person off the street. But I have to be able to replicate it. It's possible that my own instance of ChatGPT is particularly good due to my chat history. I'm considering that part of the test. I believe that at least my instance of ChatGPT is uncannily smart. Not AGI but not unmaskable as not-AGI with any single prompt.
Will someone prove me wrong?
FAQ
1. Can the prompt include ascii art?
No, I don't think that's in the spirt of the question.
2. Does it have to commit the egregious error in response to one single prompt?
Yes, I did say that in the initial description and people have been trading based on that. But let's continue to discuss in the comments what best gets at the spirit of this question. I'd like to mirror Scott Alexander's 2028 version so maybe we can get clarification from him on this.
3. What about letter-counting questions?
In my testing, o3 gets those correct by writing and running Python code. Since it does that seamlessly and of its own accord behind the scenes, I'm counting that as o3 answering correctly. It even evinces perfect self-awareness about its difficulty with sub-token perception and why it needs to execute code to get a definitive answer.
4. What about other questions humans would find tedious and time-consuming?
I think o3 can typically write code that solves such problems, but for simplicity for this market we'll restrict ourselves to questions that can, for humans, be posed and answered out loud.
5. What if o3 errs but corrects itself when questioned?
That's far better than digging itself in ever deeper, but this question is about single prompts. However, if o3 is just misreading the question, in a way that humans commonly do as well, and if o3 understands and corrects the error when it's pointed out, I would not call that an egregious error.
6. What if the error only happens with a certain phrasing of the question?
As long as rephrasings don't count as clarifications or otherwise change the question being asked or how difficult the question is for humans to answer, then we'll consider it in the same category as the SolidGoldMagikarp exception if the failure depends on a certain exact phrasing.
(I didn't settle on this clarification until later but it turns out to be moot for this market because we've now found a prompt o3 fails at regardless of the exact phrasing. So we're looking at a YES resolution regardless.)
7. What if o3 overlooks a detail in the question?
If it's a human-like error and it understands and corrects when the oversight is pointed out, that's not an egregious error.
8. What if there's high variance on how well people off the street perform?
Basically, if we're having to nitpick or agonize on this then it's not an egregious error. Of course, humans do sometimes make egregious errors themselves so there's some confusing circularity in the definition here. If we did end up having to pin this down, I think tentatively we'd pick a threshold like "9 out of 10 people sampled literally on the street give a better answer than the AI".
9. Can this market resolve-to-PROB?
In principle, yes. Namely, if we can identify a principle by which to do so.
[Ignore AI-generated clarifications below. Ask me to update the FAQ if in doubt.]
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ1,425 | |
| 2 | Ṁ448 | |
| 3 | Ṁ308 | |
| 4 | Ṁ239 | |
| 5 | Ṁ226 |
People are also trading
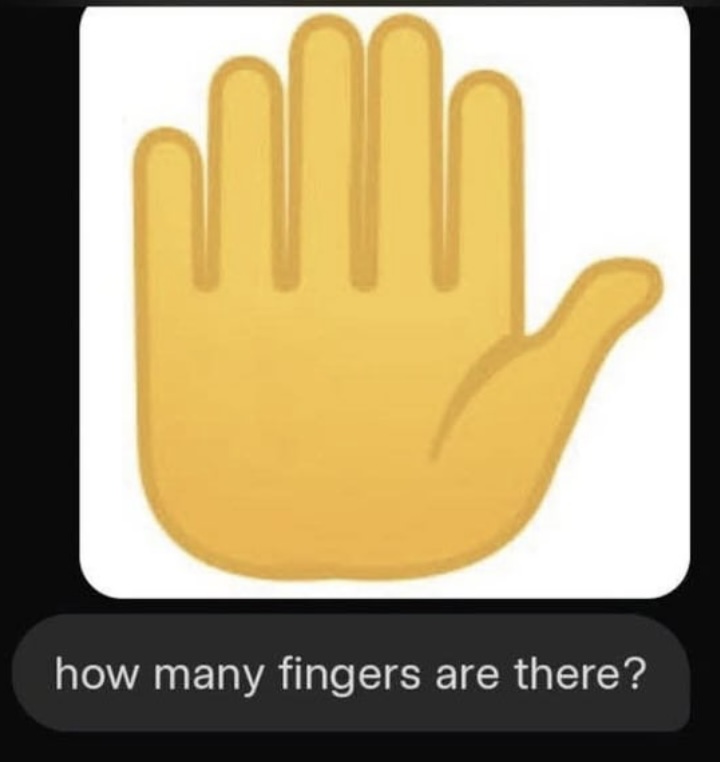
@AlanTuring Whaddya know, GPT-5 is utterly blind to the actual digit count on that hand. Worse, it lies its ass off about what it's able to perceive.
@dreev yeah it’s mildly amusing that IIUC, GPT5 is way more liable to be tripped up by the simple questions in this thread than e.g. o3, since it tries not to do reasoning by default and these questions present as ones where reasoning shouldn’t be necessary.
It’s a superficial difference, you could add “think really hard about this!!!” to each prompt and (I assume?) close much of that gap, but it’s not what I would have originally assumed
@Ziddletwix No amount of thinking seems to help for this one. Even when I told it it's a trick and to please count carefully, it pretended to do so and confidently doubled down on "4 fingers plus a thumb".
Can we pls resolve this
I've asked the duct tape ham sandwich question to a few more people out loud, including nontechnical folks, and it seems to be pretty overwhelmingly obvious to people. The one error a human made was less bad than the o3: they hypothesized or rationalized the ham and bread congealing in order to justify the "4 and 1" answer.
So I'm feeling reasonably comfortable resolving to YES. @traders, speak now or forever hold your peace?
Found the prompt. Not the chat log, though.
1. Stack of sandwiches:
> Alice has a stack of 5 ham sandwiches with no condiments. She takes her walking stick and uses duct tape to attach the bottom of her walking stick to the top surface (note: just the top surface!) of the top sandwich. She then carefully lifts up her walking stick and leaves the room with it, going into a new room. How many complete sandwiches are in the original room and how many in the new room?
I think I'm still satisfied that YES is, by far, the most correct resolution, given your reports.
@dreev I'm not sure your sample is representative of the general population. Did you try asking a random person off the street?
Also, is this wrong?
https://chatgpt.com/share/68508bd3-7704-8012-98b4-9daa7c97b4e3
I am observing sensitivity to whether the “note” is included:
https://chatgpt.com/share/68508edc-a238-8007-83f0-6cfb98db5002
https://chatgpt.com/share/68508f22-3f6c-8007-9887-17aca132c33f
Funnily a temporary chat without history yields some hilariously bad reasoning about the situation but still lands on the correct solution after searching the web for coefficient of friction of mayo lmao


@wearmysailorsuit if that’s from mine, my custom prompt tells it to generate the three follow-up questions. I have that so I can often just reply with a number and get more info.
@3721126 Yeah, with the parenthetical note emphasizing just the the top surface, o3 seems to get it right!
@dreev without the note it is possible to push the stick through the sandwich while attaching so it would be carried away in it's entirety
It can land on the correct answer without the note https://chatgpt.com/share/685152af-300c-8007-8a9d-bc700af894dc
@dreev are we asking questions to o3 that it actually gets right? Isn't the criteria that o3 should get them wrong?
@Quroe I don't know. Frankly, in most of these questions I'm not sure what the exact question OR right answer is, no idea how they could train o3
My version of o3, with access to my whole history, now gets the duct-taped ham sandwich problem right, but of course that doesn't count. It got it pretty egregiously wrong originally -- https://chatgpt.com/share/683b2cfd-3314-800d-a7b0-81d989bb833d -- and gets it wrong still today in a temporary chat. Some uncertainty remains about what a thorough and literal person-on-the-street test would yield, but even the one failure I observed from a literal person on the street wasn't as bad as o3's failures.
Note that, when posing the question, if you emphasize explicitly that the duct tape is only attached to the top surface of the top sandwich, that's enough to nudge o3 into understanding what would actually happen. But the original prompt (including rephrasings) do yield the egregious failure, which I currently believe suffices for a YES resolution.

While the ham sandwich prompt, if it were an always-fail prompt, would be a compelling case to resolve YES if it were always repeatable, it seems like there is some debate on it.
However, given the plethora of other examples of prompts that can trigger absurd responses, I think the case for YES is still compelling.
@dreev these are all stastical models so it's entirely possible your history is irrelevant. It should be expected there will be variation in responses to any question which is not super common in the training data because the models don’t “know” anything, you are interacting with probabilities and “known” solutions are just higher weighted in the probability distributions.
Explictly: You might be seeing it getting things wrong initially and right now purely by chance.
@Quroe before we decide how to resolve, can we agree on what the right answer to this question is and prove that a majority of the people on the street (out of 10) would answer in that way?
@JasonQ Also, there is some random "salt" thrown in to slightly perturb the initial conditions of the prompt, effectively randomizing the response you get, right? Is my understanding correct?
If so, it may be near impossible to perfectly replicate anything here.
@Quroe it doesn't make sense for the bar to be “always fail.” There’s always some chance of generating correct information or incorrect information. It's just smaller variance for well known or common problems.
There’s always “salt” in interacting with LLMs, you can turn up the temperature. They used to let you explicitly play with temperature back in the old webUI pre-chatGPT.
Re:
before we decide how to resolve, can we agree on what the right answer to this question is and prove that a majority of the people on the street (out of 10) would answer in that way?
I think you're right. I agree.
8. What if there's high variance on how well people off the street perform?
Basically, if we're having to nitpick or agonize on this then it's not an egregious error. Of course, humans do sometimes make egregious errors themselves so there's some confusing circularity in the definition here. If we did end up having to pin this down, I think tentatively we'd pick a threshold like "9 out of 10 people sampled literally on the street give a better answer than the AI".
-Market Description
@SimoneRomeo There's a spectrum of answers of increasing correctness and it's a bit of a judgment call where the "egregiously wrong" line is but here's a sampling:
4 and 1 because blah blah coefficients of friction and normal forces
4 and 1 because the ham and bread congeal
4 1/2 and 1/2
4 2/3 and 1/3
4 and 0
here’s a nice write up: https://medium.com/@1511425435311/understanding-openais-temperature-and-top-p-parameters-in-language-models-d2066504684f
My point is the idea that the response will always be right or wrong to any questions is fundamentally not how these models work. It should never be assumed that either all humans or all calls to probabilistic models of humans’ language will return responses at a 100% correct rate.
What makes an error “egregious” or “unmasked as AI” is whether it looks inhuman and has a significantly lower probability of being returned by a person than a model.
@dreev you should ask someone off the street instead of just asking people selected for being your acquaintance.
@dreev why in the most correct answer the total of sandwiches is 4 and not 5? Where does the last sandwich go?
@jack got it. Can we agreed now on:
How @dreev is going to run the control test with humans?
Eg. Talking to 10 people on the street (no people he knows). Separately (not everyone together). Giving them absolutely no additional information/clarifications/time to debate. Recording (even just writing down) their exact answers.
@SimoneRomeo I've now asked enough non-technical people that I'm satisfied this is easy enough for a person on the street. I don't feel compelled to literally ask more people on a literal street. If anyone thinks I should, please first create a market to predict the outcome.

I've made an online survey posing this, along with a sanity-check question, to filter for average-intelligence people who are at least reading the question carefully: https://surveyswap.io/surveys/c1958537-382e-4394-810f-dc46d9c09ef6/take-a-survey
I think it's overkill at this point and there isn't much remaining doubt that people on the street can answer the ham sandwich question fine (I've asked a lot of people at this point, mostly metaphorically and one literally off the street). By contrast, o3 talking about normal forces to try to justify the 4-1 answer counts as egregiously wrong. It's very close and a bit of a judgment call so I'm nervous about officially resolving but I think YES is what's fairest. Note that I didn't bet in this market myself and was biased towards NO.
@JasonQ Astute point, but it shows me which people answered via that link so if it's suspicious in either direction I'll remove those responses. Or, ok, now that I say that, lemme just precommit to only counting the organic responses from SurveySwap.