
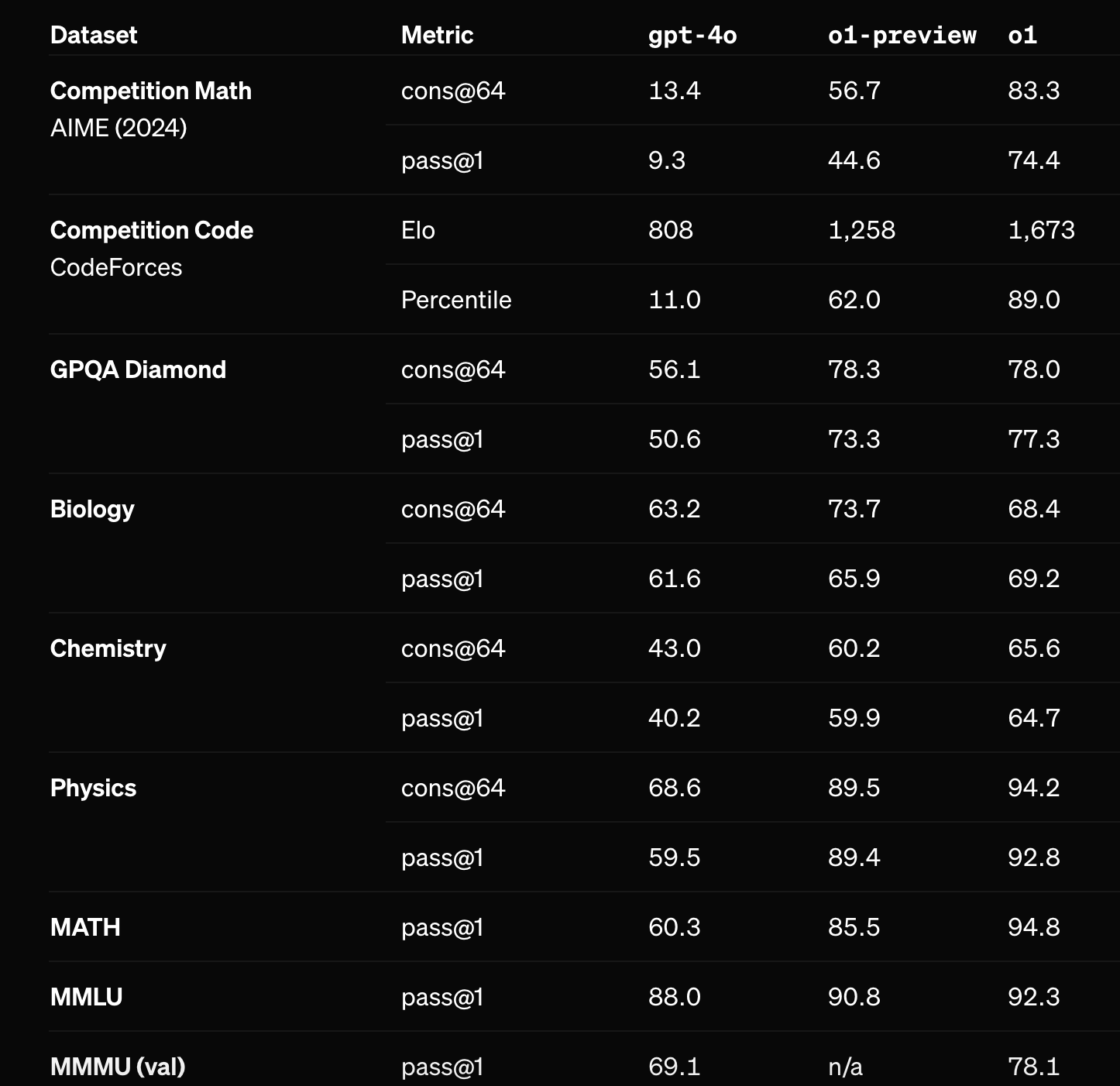
The creators of the ARC prize already tested OpenAI's new o1-preview and o1-mini models on the prize. The non-preview version of o1 performed substantially better (see below) on OpenAI's math benchmarks and will seemingly be released before EOY. Assuming it's tested on the ARC prize, how well will the full version of o1 perform?
Note 1: I usually don't participate in my own markets, but in this case I am participating since the resolution criteria are especially clear.
Note 2: The ideal case is if the ARC prize tests o1 in the same conditions. If they don't, I'll try to make a fair call on whether unofficial testing matches the conditions closely enough to count. If there's uncertainty, I'll err on the side of resolving N/A.
Update 2024-18-12 (PST): When evaluating ARC prize results, if there are multiple scores based on different thinking time settings, the creator will likely use the High thinking time score for resolution, but will consider community feedback before finalizing this decision. (AI summary of creator comment)
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ5,140 | |
| 2 | Ṁ2,423 | |
| 3 | Ṁ435 | |
| 4 | Ṁ390 | |
| 5 | Ṁ226 |
People are also trading
So I didn't plan for the option to use more thinking time and now I have a dilemma about which of these to take: https://x.com/arcprize/status/1869551373848908029. I'm leaning towards the "High", but please speak up in the next day or two if you disagree.