
I asked ChatGPT, "I need you to do the following for me: Generate a random binary string 100 bits long." ChatGPT almost did this for me, except that the result was only 97 bits long. I then generated my own 97 bit random string with numpy.random. The beginning of both strings is below. I put them in a randomized order, based on numpy.random.randint(2). I will reveal more of the strings over time, at my discretion (e.g., I might reveal it more quickly if people seem to have exhausted everything they can do to analyze the current strings, or if the market already seems certain of the result). The close date is subject to change, depending on how long it takes to reveal the full string and how confident the market is, but I will not close it unless the full string has been revealed for at least 48 hours.
A: 1100001010000100010101010110001010101101101000001101101110000111100010000011101100110100010010010
B: 1101101010010101110100111101011100100011101011011100100110110111110101110010000101101111100110001
This market resolves YES if A is the ChatGPT-generated string, and NO if B is. I will not bet.
Inspired by /Loppukilpailija/which-random-bit-string-is-humangen
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ663 | |
| 2 | Ṁ332 | |
| 3 | Ṁ199 | |
| 4 | Ṁ160 | |
| 5 | Ṁ25 |
People are also trading
The seed I used to generate the random number was actually just the first few bits of the GPT number (though treated as base ten digits):
import numpy as np
np.random.seed(110110)
rand = ""
for i in range(97):
rand += str(np.random.randint(2))
print(rand)
1100001010000100010101010110001010101101101000001101101110000111100010000011101100110100010010010After that, I used one more call to randint to determine if the GPT string would be A or B.
Certainly A is real.
Entropy for A: 0.9905577004075261
Entropy for B: 0.9709505944546686
@JosephNoonan I again think that it would be nice to have more bits. Overall, there doesn't seem to be much action here anymore - people seem to have mostly made up their minds, so unless something surprising happens there won't be much movement anymore. (I personally would like a resolution sometime soon, as I have a lot of mana in here, but others may disagree.)
@Loppukilpailija In short, why I believe what I believe:
See my earlier comment at https://manifold.markets/JosephNoonan/which-random-bit-string-is-gptgener#pPIBHigKFw6MIQADRDGc
I haven't really looked at the market after the first 10 or 15 bits or so - it didn't seem like there was much low-hanging evidence then
I'm not particularly impressed with the gzip result, though I do admit that it's evidence for A. (EDIT: though it seems that the length difference in the zips has decreased from 5 to 4 - I consider this a slight advance prediction of my model.)
I have taken over 100 samples from ChatGPT with the given prompt. I have not gotten a single output that starts with "11000", but have got at least 8 that start with "11011".
The substring "0000" is around three times less frequent in those outputs than "1111". This statistic points strongly towards B, even more so given the new 00000 in A.
I didn't particularly look at any other statistics (except checked basic "frequencies of blocks of length 2?"), but rather the only obvious ones where I see a difference between A and B.
Quantitatively the 8 vs. 0 samples that start with 11011 vs. 11000 seems like at least a factor of 8 : 1 evidence for B over A. The substring thing is, I don't know, maybe a bit or two on top of that? My within-model-probability is even smaller due to harder-to-communicate reasons about the sampling process. Don't have much model-uncertainty either, so I'm comfortable pushing the market very down.

@ManifoldMarketsUser Interesting, so the idea is that B has more entropy and is therefore more likely to be random. Though it's also possible that fake random strings would actually be harder to compress than real random ones, since a real random string may by chance have some segments that can be compressed a little, while a fake one could be designed to be as hard as possible to compress (though obviously I didn't specifically ask ChatGPT to make a string that's impossible to compress with gzip).
@ManifoldMarketsUser This is how uncommon this is:
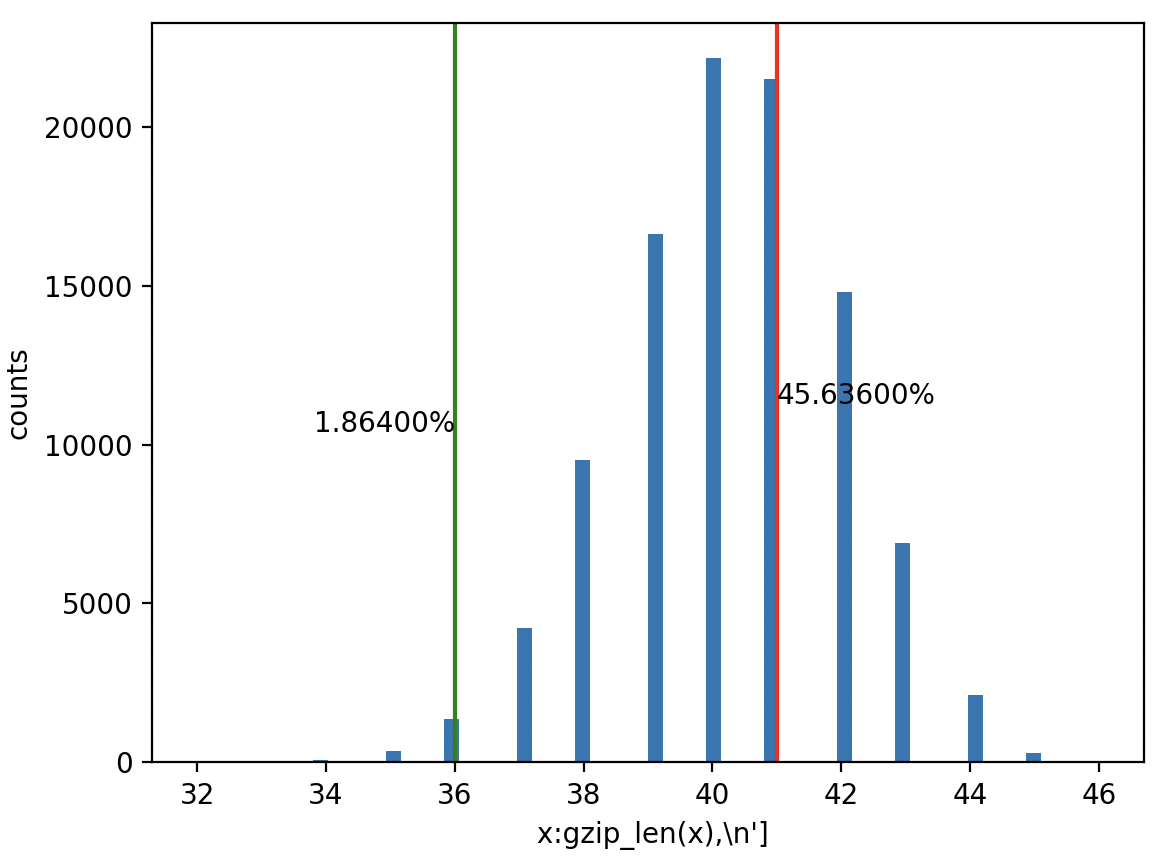
Blue are the gzip lengths of randomly generated numbers. Only ~1.9% of random numbers have a gzip length of 36 or less.
We could need some help over here: https://manifold.markets/Loppukilpailija/which-of-these-random-bit-strings-a
