
https://www.safe.ai/blog/forecasting
Some kind of way it is not true in a common sense way. Things that would resolve this yes (draft):
We look at the data and it turns out that information was leaked to the LLM somehow
The questions were selected in a way that chose easy questions
The date of forecast was somehow chosen so as to benefit the LLM
This doesn't continue working over the next year of questions (more accurately than last year of metaculus crowd, ie the crowd can't win because it gets more accurate)
The AI was just accessing forecasts and parroting them.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ410 | |
| 2 | Ṁ253 | |
| 3 | Ṁ231 | |
| 4 | Ṁ223 | |
| 5 | Ṁ214 |
People are also trading
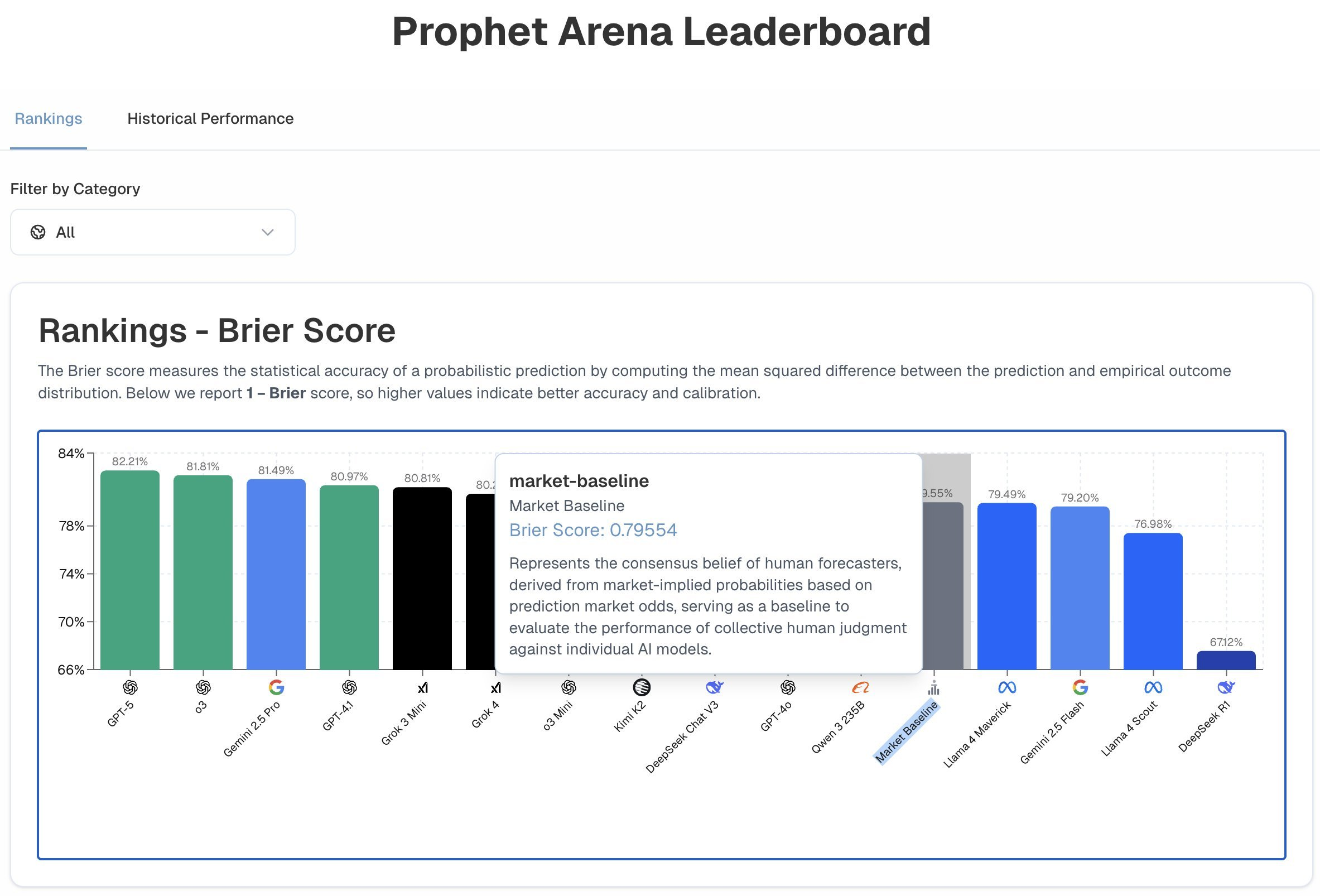
https://x.com/ProphetArena/status/1956928877106004430
Notice that even older models are doing better than prediction markets.
@DanHendrycks Is it surprising to you that when Metaculus runs actual AI forecasting competitions, (1) AIs are still behind the top human forecasters, & (2) the successful bots are not just soliciting probabilities from a simple prompt (the Q2 winner is OS, and it's a fairly sophisticated strategy—hopefully in Metaculus' full write-up they include the performance of those simpler systems, but it seems unlikely that any are in serious contention).
Do you believe that soliciting probabilities from older models and betting on the outputs would be consistently profitable on Polymarket, and people just haven't shown enough initiative to do that?
it seems unlikely that any are in serious contention
@Ziddletwix to be fair, metac-o3+asknews did almost as well as the Q2 winner (it scored 5131.072 vs 5898.984, so 87% as well), and its strategy is not particularly complex (it's a one shot prompt plus an asknews lookup): https://github.com/Metaculus/metac-bot-template/blob/main/main.py#L173-L203
There is also a bot performing well in the quarterly cup, at time of writing ranked 9th overall, so roughly behind the strong forecasters but above the amateurs (hit 'advanced' on the leaderboard to see it): https://www.metaculus.com/tournament/metaculus-cup/ - not sure how sophisticated its strategy is though
@NathanpmYoung one hypothesis that I don't see discussed much yet is re: forecasting freshness effects (as distinct from information leakage):
The Metaculus community forecast is a (recency weighted) average of a set of forecasts with varying ages; depending on the question activity level, there can be substantial lag. If the benchmark compared a set of forecasts by the model at time T with the community forecast at time T, assuming no information leakage, the model has an advantage from this alone.
From experience, it's very possible to beat the community forecast with this advantage, particularly if the question isn't "in focus" (e.g. not part of a tournament or top-of-mind as a topic in current events). This is true even with n(forecasters) above the cutoff SafeAI used here (20)
For example, in the acx tournament due to the scoring cutoff, there's many questions with hundreds of forecasters that have no real reason to return to update their forecasts
This hypothesis is consistent with other observations about the system's performance (e.g. that it underperforms on shorter questions where this effect might be less to its advantage)
In order to validate or disprove this hypothesis, one could:
with Safe AI and Metaculus's support, review the questions forecast against and break down performance by freshness of community forecast
something like, for the subset of questions with at least X% of forecasts made within T time of the cutoff chosen for the benchmark community forecast, do the results still hold?
Run the experiment again, controlling for community forecast freshness
e.g. constrain the questions chosen to ones where the gain in num forecasters over the preceding week is at least X
enter the bot into the Metaculus AI Benchmarking contest, which mostly controls for this (the benchmark forecasts are at most a couple days stale vs the bot forecasts)
@NathanpmYoung The frustrating thing here is that a question like this depends heavily on the judgement of the person making the resolution, and your previous comments suggested that you were leaning pretty heavily toward yes. Has something changed, or did I misinterpret you?
From what I can tell, no one is discussing this anymore, and their demo was taken down pretty quickly. So, I doubt there will be any new evidence. They also seem to have no interest in their own forecaster or providing evidence e.g., by entering it into competitions. I think all signs point to their claim being debunked/exaggerated, and most implicitly not believing their claim, but no one has cared enough to try to rigorously disprove the claim further than what has been done.
@DanM FWIW I'm confident our claims were correct. I haven't seen any response to our response to Halawi yet, which fully addresses all of the concerns that have been raised imo. The demo was taken down because of budget constraints, since a lot of people were using it. The blog post is still up.
> They also seem to have no interest in their own forecaster or providing evidence e.g., by entering it into competitions.
It was a quick demo, meant to raise awareness that superhuman forecasting is already here by at least one meaningful definition. We don't have bandwidth to run the additional experiments that people have requested, although someone else could run them if they want as our code is public; I'm just replying here because I'm personally interesting in clearing things up. I guess I can say that we've worked in this area before (see the Autocast paper from NeurIPS 2022, which was one of the first academic papers on LLM judgmental forecasting), and we followed standard academic practice for retrodictive evaluations, which are also followed by Halawi and others who have done work in this area. This isn't as good as a prospective evaluation, which is a good thing for future work to look into (and which Tetlock's recent paper did indeed study).
I think a lot of opinions expressed here are maybe anchoring on the initial criticisms from before our response. Even the Metaculus and ACX posts that came out after our response was posted were just repeating points that we already addressed, so they probably weren't aware of our response.
@MantasMazeika Do you currently think that your system would perform anywhere close to your advertised performance when performing e.g. in something like the Metaculus AI forecasting tournament (which multiple people at Metaculus have offered to enroll your system in)?
That seems like the obvious way to resolve this question, and also to dispel any claims about shoddy work. I currently would take bets at reasonably large odds (4:1) that your system would perform much worse in a prospective Metaculus tournament, and it doesn't seem like that much work to enroll. It will take a few months until we have an answer, but still seems better than nothing.
@OliverHabryka See above for my comments about not having bandwidth to do this. If people want to enroll the system, they are welcome to do so and nothing is stopping them; the full codebase is available on GitHub. As for my thoughts on what the results would be, I wouldn't be surprised if our system performs less well in a tournament with a different question distribution. It performs less well on short-fuse polymarket questions, for instance, as we pointed out in our blog post and our response to Halawi. People who have read our response will know that Halawi's independent evaluation of our system was dominated by short-fuse polymarket questions; when removing those questions from their independent evaluation, their results match ours. This is effectively an independent replication in the retrodictive setting.
ETA: I do think our retrodictive evaluation was performed properly and that there wasn't data contamination, so modulo distribution shifts I would expect our system's performance to reflect how well it performs in a prospective setting, because that is very nearly what proper retrodictive evaluations measure. If it seems surprising that AI systems can do well at judgmental forecasting, then I would say you don't have to just take our word for it; the recent Tetlock paper that I shared below has similar quantitative results, albeit presented differently.
@MantasMazeika Why would your system perform much worse on a different distribution of questions? It seems extremely suspicious if your claims about reaching human-level or superhuman performance on forecasting, a claim that was not marketed as only applying to a narrow-ish distribution of questions, would end up performing much worse on the one testing setup that we have that is actually capable of confidently measuring its performance.
The retrodiction issues are the most concerning issues, so removing questions that resolved quickly from Halawi's dataset gets rid of most of the unbiased data we have. Your mitigations for retrodiction do not seem remotely adequate, though I am glad you tried (I think allowing websearch for retrodictions is a lost cause even with filtering, there is just far too much data leakage).
when removing those questions from their independent evaluation, their results match ours.
You claim this, do you actually have any writeup or public code-trace for this? This would be at least a mild update for me, but I am not particularly tempted to take you at your word.
@OliverHabryka We clearly describe the limitations of the system in the blog post, including distributions that it performs less well on. It's actually fairly common in ML research that a system may perform at or beyond human-level on one distribution but not solve the task in a fully general sense. We have been clear about this since the release of the demo.
It's odd to describe the distribution we tested on as narrow. You can read for yourself the specific types of questions that we list in the limitations section. Here is the relevant text:
> If something is not in the pretraining distribution and if no articles are written about it, it doesn't know about it. That is, if it's a forecast about something that's only on the X platform, it won't know about it, even if a human could. For forecasts for very soon-to-resolve or recent events, it does poorly. That's because it finished pretraining a while ago so by default thinks Joe Biden is in the race and need to see articles to appreciate the change in facts.
Regarding data contamination, I disagree that the mitigations were inadequate. If one ensures that retrieved articles are from before the cutoff date and takes several overlapping measures to prevent knowledge leakage, then I would think that is a fairly strong set of mitigations. We did these things, and you can read about the specifics in our response to Halawi and the blog post. Again, we have published work in this area at a top ML conference. We know what we are doing.
I'm disappointed that this conversation has devolved into assertions of academic dishonesty, since it signals that it isn't being held in good faith. I don't have all the code for filtering out Halawi's short-fuse polymarket questions and recomputing the metrics. I think some of it might be in Long's folder, and the stuff I have is a bit messy right now. I might dig it up later. In the meantime, you are welcome to download Halawi's questions and run the evaluation yourself using our public code.
> I'm disappointed that this conversation has devolved into assertions of academic dishonesty, since it signals that it isn't being held in good faith.
This whole post is about academic dishonesty! What do you think "substantive issues" means? Yes, I do think your announcements and posts at present appear basically fradulent to me, and I would defend that accusation. I am definitely not engaging in good faith, meaning that I am assuming that you are telling the truth and are accurately reporting your intentions (and I think that's fine, I don't see an alternative to what to do when I think someone is engaging in academic fraud or otherwise acting dishonestly).
@MantasMazeika
> We did these things, and you can read about the specifics in our response to Halawi and the blog post. Again, we have published work in this area at a top ML conference. We know what we are doing.
Academic fraud is widespread and publishing in top conferences is not a strong sign of not engaging with fraud. I have probably engaged more closely with your work here than reviewers of your past papers. I saw your response to Halawi and find them uncompelling.
To be clear, I am not totally confident here, and I can't rule out that somehow your prompt + system outperformed all other systems that we have data on despite doing nothing that seems to me like it would explain that, but I am highly skeptical. My best guess is you fooled yourself by not being sufficiently paranoid about retrodiction and are now trying to avoid falsification of that.
@OliverHabryka Substantive issues doesn't mean academic dishonesty; it usually means a mistake. Also, our system doesn't outperform all other systems, and we never claimed that it did. Probably some of the methods in the Tetlock paper would have similar performance to ours on the data that we evaluated on.
I don't think you are literally engaging in bad faith Oliver, and in the holiday spirit I take that comment back. I do think you have misinterpreted our main claims, though, which I have tried to clarify multiple times. If you actually think we are lying to everyone, then I guess I just don't feel that compelled to respond directly to that comment. I think other people probably disagree and would sooner attribute any error we made to incompetence than to dishonesty. But I think we did things fairly by the book and took good care to ensure our results were valid. Moreover, they are consistent with other similar results in the area and were semi-independently replicated. Finally, all our code is public and anyone can check our claims for themselves. We're not really hiding anything here.
@MantasMazeika I would also like to defend my colleagues in ML and point out that academic dishonesty is far less of an issue in ML than in other fields, largely because there is so much legitimate research to be done. In the dozens of papers I've seen people work on in this field, I don't think I've seen a single instance of academic dishonesty.
@OliverHabryka Also, just a quick point about your statement earlier (tagging @NathanpmYoung since idk if this point was raised before)
> I think allowing websearch for retrodictions is a lost cause even with filtering, there is just far too much data leakage
We are not the only people to do this. Halawi/Steinhardt's paper does exactly the same thing. Their leakage mitigation is described as:
> First, we maintain a whitelist of news websites that publish timestamped articles and only retrieve from the whitelist. Second, our system checks the publish date of each article and discard it if the date is not available or outside the retrieval range.
These mitigations are standard practice in the retrodiction literature. We went even further than this, checking for updated articles and running an LLM over each article to ensure no information was leaked. If you think our mitigations were insufficient, then you would also have to conclude that many results in Halawi's paper are invalid, which I disagree with. I would hope that others also agree that the mitigations deemed sufficient by people who do professional work in this area are in fact sufficient. Certainly prospective evaluations are better, but claiming that by-the-book retrodictive evaluations must all be thrown away is just not a position that anyone in this area holds.
@MantasMazeika
> Certainly prospective evaluations are better, but claiming that by-the-book retrodictive evaluations must all be thrown away is just not a position that anyone in this area holds.
They should be thrown away in as much as they do not also correspond to performance on an equal distribution of future predictions. Unless someone demonstrates that validity, I am highly skeptical, based on my own experiences looking through the actual data that the present mitigation efforts produce, in which I can clearly identify bits of information about future events leaking through. Lots of people hold the position that retrodiction is too hard, indeed it is the default position I encounter from people working in AI forecasting, which is why they create things like the Metaculus AI forecasting tournament.
Put your system in something like the Metaculus forecasting tournament. If it doesn't perform as well there as you advertised you should concede that your work was shoddy. Yes, you can quibble a bit about whether the distribution of questions is truly the same, and some of that will be a valid critique, but the way you advertised your results in a headline grabbing way did not include such quibbles, and I would also gladly take bets that we will not see performance line up with the advertised claims as the distribution of questions gets closer to the distribution on which you estimated your scores.
@OliverHabryka I think we're coming at this from two different sets of community expectations, then, and I'm not yet convinced that your concerns about standard retrodictive evaluations are warranted. Among academics that work on judgmental forecasting, retrodictive evaluations are perfectly acceptable, since they provide considerable value, and the mitigations we used are widely deemed sufficient. Would you please be able to provide an example of data leaking through despite these sorts of mitigations? There were some examples provided in Halawi's post, but I assume you're not talking about those since we debunked them.
> the way you advertised your results in a headline grabbing way did not include such quibbles
This is objectively false, and I'm getting a bit tired of pointing this out in our discussion. As I mentioned before, it's common for ML systems to perform less well on certain distributions, and we were fully transparent about this in our messaging. The blog post and X thread both clearly discuss the limitations of the system, which you can easily check. We were actually quite careful with our messaging. For instance, we did not claim that our system is the best AI forecaster in the world, since we were acutely aware of the simplicity of the system. We were primarily aiming to raise awareness that these systems are superhuman now in a specific sense, subject to certain limitations. The recent Tetlock paper shows that this is possibly the case in a prospective setting using similar AI systems. These kinds of milestones are often pointed out in ML research; we just saw an opportunity to point out that the milestone had been crossed in a sense that we thought was fairly meaningful, and did so.
@OliverHabryka
> based on my own experiences looking through the actual data that the present mitigation efforts produce, in which I can clearly identify bits of information about future events leaking through
If you could convincingly demonstrate this, then that would actually be a meaningful research contribution.
@MantasMazeika Just for reference, here was the public Twitter thread:
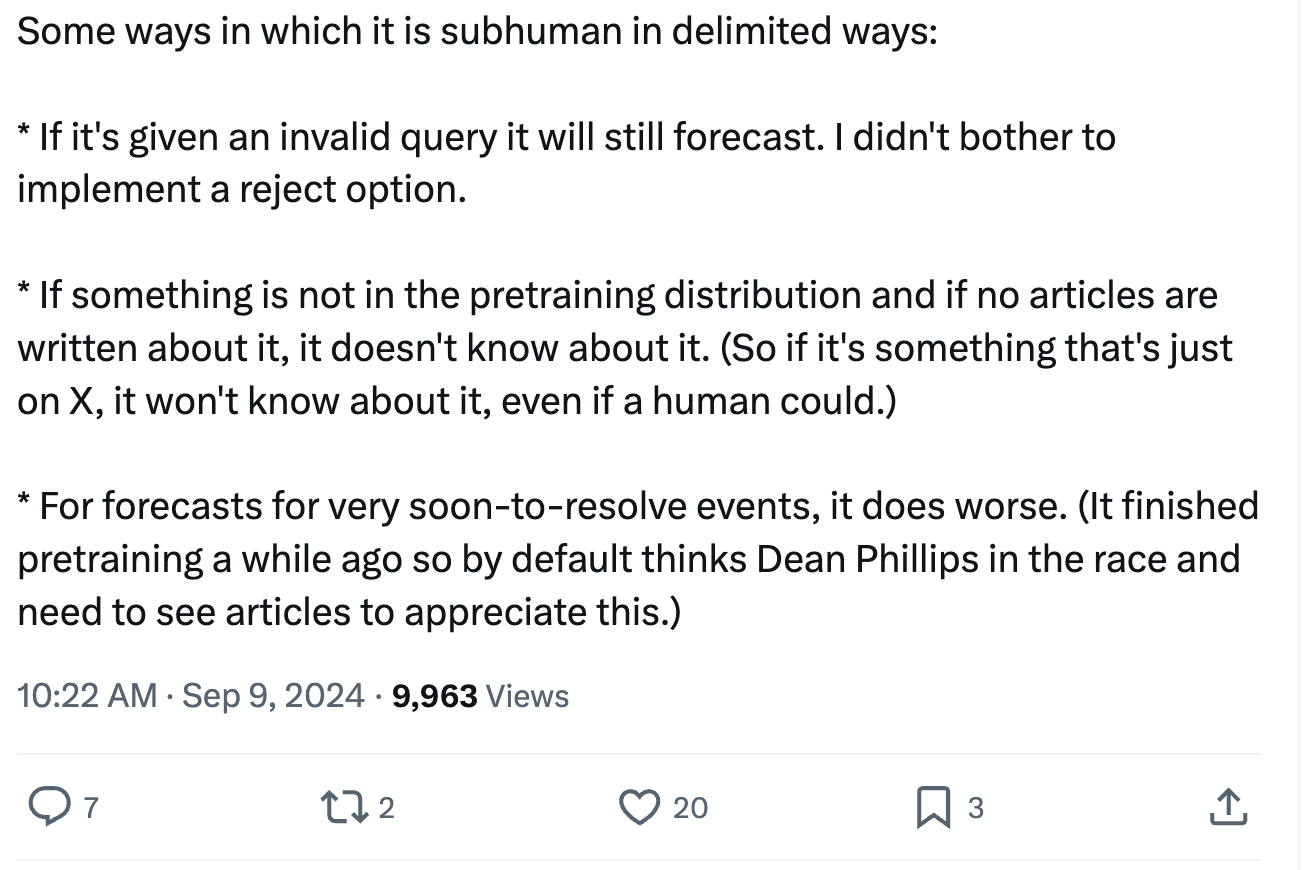

I see none of the relevant caveats in these most prominent paragraphs and sections. You only disclaim "very soon-to-resolve events".
You just repeatedly say that you have built a superhuman forecaster. This obviously means you expect it to outperform the best forecasters at forecasting. Your system does not outperform the best forecasters at forecasting, indeed it is very substantially worse at it. Therefore, you misrepresented your evidence and results.
You have a "limitations section", but the limitations section is very clear that you expect broadly in the domain of forecasting, for your system to outperform the best forecasters, or at the very least reasonable ways of aggregating the crowd:

Your limitations do not apply as far as I can tell to the Metaculus forecasting tournament, so seeing your system perform sub-crowd or sub-top-forecasters would clearly contradict your claimed results.
You just repeatedly say that you have built a superhuman forecaster. This obviously means you expect it to outperform the best forecasters at forecasting.
Actually, in the limitations section you just posted a screenshot of, you can see that we say, "In claiming the bot is superhuman (around crowd level accuracy), we're not claiming it is superhuman in every possible respect".
You seem to really want to believe that was our claim, though, despite my repeated attempts to clarify. E.g., if this is your main argument...
Your system does not outperform the best forecasters at forecasting, indeed it is very substantially worse at it. Therefore, you misrepresented your evidence and results.
...then I'm not even sure what we're discussing. We clearly do not represent our system as outperforming the best forecasters in every possible way, so if this is what you're asserting (as it seems to be) then your argument rests on false premises.
We go on to describe these limitations, some of which likely would likely reduce performance in a random Metaculus tournament, as I mentioned above and as I believe you agreed with. Does this mean that there were "substantive issues" with our claim or that we've "misrepresented ... evidence and results"? Obviously not, because our claim is moderated by the limitations we discuss! Now, I think a reasonable point to argue is whether the limitations we discuss are too restrictive for the claim to be meaningful. Personally, I think the distribution we tested on was fairly meaningful, and the result we got of matching crowd accuracy does indeed show that these systems are superhuman in a certain sense, subject to those limitations. This is why we close the paragraph by saying, "we do not believe AI forecasting is overall subhuman".
The lack of entering into contests looks real bad IMO. They have time to argue in the comments here but not to have their code do the thing it was purportedly designed to do
@DanSchwarz doesn’t even claim to have superhuman forecasting and he took the time to enter into competitions!