
The OpenAI o1 / Strawberry model finally launched, to much praise and fanfare.
https://deepnewz.com/ai/openai-unveils-o1-ai-model-advanced-reasoning-fact-checking-phd-level

LMSys has announced the model is live for ranking, and will show up in the leaderboards soon.
https://x.com/lmsysorg/status/1834397197754118236

Currently the top model on LMSys is GPT-4o with 1316 ELO. Second place is Gemini with 1300 ELO and Grok is in a statistical tie with 1294 ELO.
https://lmarena.ai/?leaderboard

What will OpenAI's o1 ELO be -- on October 1st?
A few caveats since LMSys markets are tricky on the details
we will take the best OpenAI o1 model [or any other name from OpenAI]
we will adjudicate this on October 1st -- whatever checkpoint is live then [not the "last updated" date shown]
OR we will wait until the first checkpoint including the OpenAI o1 model if none is released by October 1st
if there are multiple updates on October 1st we will take the last one...
basically we will wait until the end of October 1st (early October 2nd) and judge based on whatever was posted by then -- unless there is no release yet in which case we will extend the market
Most likely this answer will be known before the Oct 1st release. Although the ELO score can change from more votes, after the initial posting.
We will use whatever number is posted. We will ignore the +- error bars.
Now go vote on LMSys :-)
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ2,797 | |
| 2 | Ṁ2,699 | |
| 3 | Ṁ749 | |
| 4 | Ṁ744 | |
| 5 | Ṁ603 |
People are also trading
"basically we will wait until the end of October 1st (early October 2nd) and judge based on whatever was posted by then -- unless there is no release yet in which case we will extend the market"
if there is no update today (October 1st) then the current LMSys score will resolve this market
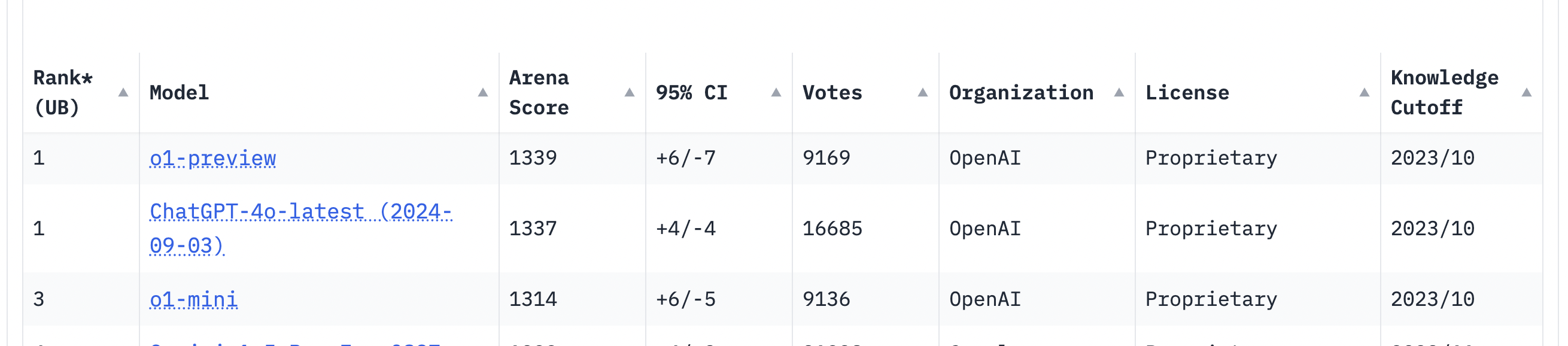
o1-preview sits at 1339 ELO
but there is a small chance there is another update today...
these guys do not keep a predictable schedule
This early report adds a lot of clarity. Usually the ELO doesn't change much from 4-5x more voting... but we are well within the margin of error between categories.
I should have published, but yesterday going into this announcement... the midpoint of this market was ~1360 ELO so another win for prediction markets. We had it right 👍
Now let's see where we settle between the two above/below 1355
I tend to think it's slightly more likely to go "over"

LMSYs published some early numbers
https://x.com/lmsysorg/status/1836443278033719631
Still big error bars but O1-preview enters the leaderboards at 1355 ELO. Right on the borderline for us... unfortunately -- we will see what updates post by end of day October 1st [Eastern Time]

LMSys put the newest GPT-4o model (09/03 version) as new #1 overall with 1336 ELO
https://x.com/lmsysorg/status/1835825082280902829
gotta figure O1 will be better!

@NeelNanda I still think LMSYS is the best benchmark for AI since it benches actual use cases and can adapt to future model ability. As the models get better, people's expectations rise. As expectations rise, intelligence matters more. You aren't going to get 100 ELO just from style.

Some say it's doing well on (never before seen) IQ tests...
https://x.com/maximlott/status/1834652893229859212

Separate market "will o1 reach number one on October 1st" is created
https://manifold.markets/Moscow25/will-openais-o1-reach-1-on-lmsys-on
cc @Bayesian
@Moscow25 also available as an arb given our "1315 or below" resolves to second place or possibly tie for first
Glad to see we have the usual suspects in this LMSys market. And I'm already down 15% so that's fun too.
My only in side info is that I tried o1-preview and it was good.
No idea what OpenAI will put on LMSys but I strongly suspect it will be o1-preview. You can use the service and see for yourself.
@Moscow25 I agree with you and would bet NO if I had enough mana.
The problem with this leaderboard is that the site intentionally limits the context windows of the prompts. Additionally, nobody is putting in actual useful work because they don't want their code used as training data.
The reason Claude 3.5 Sonnet, which is obviously better than GPT-4o, scores lower is because nobody is using these models for actual difficult work. Look at X, where people are burning through 30 prompts asking o1-preview stupid questions like the spelling of strawberry instead of how to design a new novel model.
Yes people ask easy questions, among other issues.
We tested O1 on a hard task. Given 10-30 tweets about a topic write a coherent news article. That’s what we do at DeepNewz.
O1 was better every time and sometimes much better. And that’s with a prompt optimized for Gpt-4
To be clear, if they only release o1-preview and o1-mini by october 1st, and have only those on the leaderboard, it resolves to their score? @Moscow25
@Bayesian yes -- that's right
we will take the max of whatever o1 stuff they have... be it mini, preview or otherwise
I expect this to be o1-preview
but if they post a stronger model so be it
@Moscow25 sounds good. i find it plausible that they wouldn't post it at all on lmsys, bc it's kind of expensive to run (a lot of internal reasoning can take minutes and dollars-worth of tokens). in which case we might wait for a bit. not sure though
@Moscow25 I'll take a YES order on the model not reaching current #1, at 8%, for a lot of mana, if you want
@Bayesian they will have at least mini -- I'm quite sure
I've also used o1-preview and it's quite good
@Moscow25 wdym? you mean on the other market? yeah but there's not much liquidity there, and by the time it enters the lb opus 3.5 might be out, and all that
@Bayesian I thought the ELO market would be fun for a change -- but sounds like lots of diverse interest for the number one market
one sec...