This market predicts whether GPT-4 will be able to solve "easy" Sudoku puzzles by December 31, 2023.
Resolution Criteria
Resolves YES if:
A fixed prompt is found(and posted in the comments) that enables GPT-4 to reliably solve freshly-generated easy-rated Sudoku puzzles from Sudoku - Free daily Sudoku games from the Los Angeles Times (latimes.com), using only its language modeling capabilities and context as memory.
Resolves 50% if:
A fixed prompt is found(and posted in the comments) that enables GPT-4 to occasionally solve Sudoku puzzles.
Resolves NO if:
No fixed prompt that enables GPT-4 to even occasionally solve easy-rated Sudoku puzzles using the specified conditions is posted in the comments by December 31, 2023.
OpenAI permanently shuts down GPT-4 access before any solutions are posted in the comments.
Resolves as NA if:
This market does not resolve NA.
Resources
Discord server: https://discord.gg/Y6qvtB5xPD
Github repository with solution judging script: https://github.com/Mira-public/manifold-sudoku
Manifold category for related markets: https://manifold.markets/questions?topic=gpt4-sudoku-challenge-2023
Definitions
GPT-4 refers to either ChatGPT's GPT-4, or any model named like GPT-4 exposed in OpenAI's API. "gpt-4-base", "gpt-4", and "gpt-4-32k" are currently-known model ids, but anything labeled GPT-4 would count including the upcoming image support. The API is preferable since setting temperature to 0 will allow the judge to replicate your responses, but if your prompt has a high success rate ChatGPT could also be accepted. See the definitions of "reliably" and "occasionally" below for details on computing the success rate if more precision is needed. Model must be produced by OpenAI, so finetuned variants would not count.
See "Related markets" below for variants that allow GPT-3.5, finetuned models, and that only need to solve a single puzzle.
Easy-rated Sudoku puzzle means a puzzle classified as easy by any reputable Sudoku site or puzzle generator. This market plans to use the LA Times(Sudoku - Free daily Sudoku games from the Los Angeles Times (latimes.com)) for judging, but I maintain the option to use a different Sudoku generator.
Fixed-prompt means that everything except the Sudoku puzzle provided to GPT-4 remains the same. The prompt may provide GPT-4 with instructions, but these instructions must not change for each puzzle. A solution must be found within 50 turns. Multimodal support is allowed to be used. The operator cannot give information to GPT-4 beyond the initial puzzle, so their inputs must be static. (e.g. just saying "continue" if ChatGPT runs out of output space and stops).
Formal definition of Solution
A Sudoku Template is any string with exactly 81 substitution points. Such template can be combined with 81 digits 1-9 or a Placeholder value to produce a Rendered Sudoku. The placeholder can be any string - including "0", ".", or "_" - but must be a specific string and identical each time. The substitution points do not need to be in any specific order: An inverted or flipped puzzle would also be allowed by using a template with substitutions in inverted or flipped order.
An image rendering of the initial puzzle would also be a valid Rendered Sudoku .
Chat Completion API entry is a pair (tag, message), where tag is one of "system", "user", "assistant", and message is any UTF-8 string. When multimodal GPT-4 is released, message can also be an image.
A Turn is a pair (entries, response), where entries is a list of Chat Completion API entries and response is the UTF-8 encoded string that GPT-4 generates.
A Transition Rule maps one list of entries to another list of entries, using the primitive operations:
Remove entry at fixed index(from beginning or end)
Insert a fixed message at a fixed index(from beginning or end).
Insert a rendered Sudoku created from the initial Sudoku puzzle at a fixed index(from beginning or end). The fixed prompt is allowed to contain multiple renderings of the same puzzle.
Insert the GPT-4 response to the input entry list to any fixed index(from beginning or end). You can use either the default GPT-4 response length(i.e. whenever it emits an <|im_end|> token), or can specify an exact token count up to the native context size of the model. It is allowed to make multiple API requests, and to retry requests that respond with errors, as long as the successful requests are all unconditionally concatenated into a single response and the inputs + response fits within the model's context. You cannot apply any other transition rules until the entire response is generated. The "output tokens" of the OpenAI don't matter - only the context size; so the 128k GPT-4 Turbo can be chunked to produce either a fixed number of tokens or the model can choose to stop at any point up to 128k.
Example: You have 2,000 tokens of input and are using the 32k model. If you specify "32,000" as your size here, you're allowed to keep querying the API sending the entire context + all previous responses until you get exactly 30,000 tokens of output. These should all be concatenated into a single entry.
Example: You're using GPT-4 Turbo which is a 128k context model, and have a 12k prompt. Using the "finish_reason" in the API response, the model would be allowed to generate up to 116k tokens using the maximum 4k output tokens each time.
The GPT-4 response can be tagged "user", "assistant", or "system" when later resent to GPT-4, as long as this choice doesn't depend on the message.
Truncate an entry at a fixed token index(index is from beginning or end, and truncation can start from beginning or end). You can use characters for testing, but judging will use "cl100k_base" tokens.
A Fixed-prompt is any sequence of transition rules.
The Operator is the human or program that is executing a fixed-prompt against the OpenAI API.
Then a Solution for the purposes of this market is a fixed-prompt satisfying all of:
"initial Sudoku puzzle" is bound to a specific rendered Sudoku.
The transition rules are applied for 50 turns to get a maximum of 50 GPT-4 responses.
The operator scanning for the first thing that subjectively looks like a solved Sudoku puzzle in those responses and then stopping, is able to input the solution into a Sudoku checking tool and confirms that it is a solution to the initial Sudoku puzzle.
"Subjectively looks like" refers to parsing a puzzle from a string into a normal form, and is approximately "turn number-dependent regular expression with named capture groups". I choose not to specify it because I'm not 100% sure what regex generalizations allow useful compute and want to retain the possibility of rejecting them, or of accepting isomorphic puzzle solves.
Examples
The simplest valid pattern is:
("User", <some initial prompt>)
("User", <provide puzzle>)
("Assistant", response 0)
("User", "continue") ;; or any other fixed input
("Assistant", response 1)
("User", "continue")
....
("User", "continue")
("Assistant", solution)
With at most 50 "Assistant" entries(50 turns). The only "dynamic" input here is entry #2 which has the puzzle, and the rest is ChatGPT's responses. So this counts as a "fixed prompt" solution. You're allowed to insert more prompts into the chain after the puzzle, as long as the decision to include them or their contents do not depend on the puzzle. For example, you might have a prompt that causes ChatGPT to expand the puzzle into a set of logical constraints. You're allowed to drop sections from the chain when sending context to GPT-4 , as long as the decision to drop does not depend on the contents of any section.
Candidate solutions will be converted to code and run using a script(Mira-public/manifold-sudoku (github.com)). You are not required to interact with this script when submitting a solution, but @Mira will attempt to use it to judge your solution so it may help in understanding the format.
Language modeling capabilities means that GPT-4 is not allowed to use any external tools, plugins, recursive invocations, or resources to aid in solving the Sudoku puzzle. It must rely solely on its language modeling capabilities and the context provided within the prompt. This is less relevant when using the API or Playground, and more relevant to using ChatGPT.
Reliably means the prompt succeeds at least 80% of the time, on freshly-generated puzzles. Occasionally means the prompt succeeds at least 20% of the time, on freshly-generated puzzles. I will run any proposed solution against 5 puzzles, with more testing to be done if it succeeds at least once or if there is disagreement in the comments about whether it meets a threshold(perhaps I got very unlucky). More testing means choosing a fixed pool of puzzles and calculating an exact percentage. I currently plan to choose "all easy-rated Sudoku puzzles in January 2024 from LA Times" as my pool. Since judging solutions requires me spending real money on API calls, I may optionally require collateral to be posted: $10 of mana(Ṁ1000) for quick validation, and $100 of mana(Ṁ10k) for extended validation. Collateral will be posted as a subsidy to an unlisted market that resolves NA if the candidate passes testing, or collected equal to Mira's API costs if not. Anyone can post collateral for a candidate, not just the submitter. Detailed testing will be done with the API set to temperature 0, not ChatGPT.
@Mira as market creator will trade in this market, but commits not to post any solution, or to provide prompts or detailed prompting techniques to other individuals. So if it resolves YES or 50%, it must be the work of somebody other than Mira.
Example Puzzles
From Sudoku - New York Times Number Puzzles - The New York Times (nytimes.com) on March 28. 2023, "Easy"
210000487
800302091
905071000
007590610
560003002
401600700
039007000
700100026
100065009
Solution:
213956487
876342591
945871263
327594618
568713942
491628735
639287154
754139826
182465379
Related Markets
Main market: /Mira/will-a-prompt-that-enables-gpt4-to
GPT-4 any puzzle: /Mira/m100-subsidy-will-gpt4-solve-any-fr-c5b090d547d1
GPT-3.5 any puzzle, no finetuning: /Mira/will-gpt35-solve-any-freshlygenerat
GPT-3.5 any puzzle, finetuning allowed: /Mira/will-finetuned-gpt35-solve-any-fres
Group including other related markets: https://manifold.markets/questions?topic=gpt4-sudoku-challenge-2023
Edit History
Mar 26, 2:53pm:
Will a prompt that enables GPT-4 to solve easy Sudoku puzzles be found? (2023)→ (M1000 subsidy!) Will a prompt that enables GPT-4 to solve easy Sudoku puzzles be found? (2023)Mar 27 - Clarified that judging will use freshly-generated puzzles.
Mar 29 - Added example with Chat Completions API to help specify allowed prompts.
Apr 3 - Clarified that dropping Chat Completion API turns is allowed.
Apr 20 - Added a more formal description of the solution format.
Apr 21 - Candidate solutions must be posted in the comments before market close.
Apr 27, 6:43am:
(M1000 subsidy!) Will a prompt that enables GPT-4 to solve easy Sudoku puzzles be found? (2023)→ (M11000 subsidy!) Will a prompt that enables GPT-4 to solve easy Sudoku puzzles be found? (2023)Apr 30, 1:57am:
(M11000 subsidy!) Will a prompt that enables GPT-4 to solve easy Sudoku puzzles be found? (2023)→ (M20000 subsidy!) Will a prompt that enables GPT-4 to solve easy Sudoku puzzles be found? (2023)April 30, 2:57 am: Added that the percentage is defined against a fixed pool of puzzles, if it solves at least one in a preliminary test of 5.
April 30, 5:37 am: Judging will be done with the API. ChatGPT may be accepted if it has a high success rate, but if there's any debate I will use the API with temperature 0. New York Times is chosen as the presumptive source of Sudoku puzzles.
May 5, 2 pm: Link to script on Github, changed puzzle provider to LA Times.
May 7, 3 pm: Details on posting collateral for API costs.
July 16, 7:38 AM: @Mira conflict of interest commitment.
August 8, 2:45 PM: Input representation can be any 81-slot substitution string.
August 15: NO clause for if OpenAI shuts down.
August 23: Truncating a message is allowed.
August 28: You're allowed to make multiple OpenAI API calls to generate a single logical response, to work around limitations of their API.
September 22: Related markets; finetuning and GPT-3.5 aren't allowed.
November 13: "finish_reason" in the API allows the model to stop chunked outputs, so the 128k context GPT-4 is allowed to have a single chunked 128k output, not 4k like you might assume. Also added countdown timer by popular request.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ13,830 | |
| 2 | Ṁ9,655 | |
| 3 | Ṁ8,542 | |
| 4 | Ṁ6,951 | |
| 5 | Ṁ6,889 |
People are also trading
Update from the future:
I tried the latest LA Times Sudoku puzzle (29 March 2025):
<sudoku_grid>
008 000 090
006 800 003
109 000 560
040 000 601
037 100 080
912 600 000
760 320 900
004 910 000
000 407 002
</sudoku_grid>
I then gave Gemini 2.0 Flash Thinking + Gemini 2.5 Pro an AI-crafted prompt (made with Anthropic's meta-prompt) to solve the Sudoku, where they are instructed to use scanning + candidate elimination + hidden single recursively. Flash Thinking failed, but 2.5 Pro solved it!
Single-turn zero-shot pass@1.
<answer>
328 576 194
456 891 273
179 243 568
845 739 621
637 152 489
912 684 357
761 328 945
284 915 736
593 467 812
</answer>
Logs for Gemini 2.5 Pro are here, 2.0 Flash Thinking's logs are here.
Maybe this can be a benchmark?
@bohaska clarification: the initial prompt was mostly made by Flash Thinking but after seeing that AI flounder a bit, I added the hidden singles technique to the instructions and called it "number filling" because I didn't know what it was called before I looked it up
@NicoleWilson Do you believe that it was resolved incorrectly? If the resolution criteria are sufficiently objective and comprehensive then I don't think there's a conflict of interest in betting on one's own market. (Sometimes even with criteria that seemed objective and comprehensive you do end up with a weird edge case, and in that situation a creator who's bet on their own market should probably get some outside opinions. But this resolution seems straightforward enough.)
@NicoleWilson The only market you ever bet in on this platform was one you resolved, with you being #1 in profit.
Where did the 0.5 come from?
Not even sure if I knew that was possible when I went short at 40% or whatever last August, seemed like a binary at the time...
Looks like market moved after the link was posted and then everyone got jazzed. But the solution only works like 40% of the time and you have to do engineering to use it(?).
To me that's a 0 / fail / halt but idk.
https://github.com/iamthemathgirlnow/sudoku-challenge-solution/tree/main
@BenjaminCosman my question is less was it resolved according to the criteria and more, did the criteria change along the way?
My memory sucks, but I don't remember a 0.5 being an option for 'it kinda gets some of them.'
Maybe there was and I should have read closer but the question is more did the criteria change as people got hyped and then wanted a compromise (which wasn't really a compromise).
@AlexanderLeCampbell The 0.5 option is very clear in the currently-visible resolution criteria (if you can't be bothered to read all of it, then Ctrl-F for "Resolves 50% if:" and then for "Occasionally means the prompt succeeds at least 20% of the time". You can review the market history from the three-dots menu followed by the History button; I'm not going to check every version for you but I can confirm that the 0.5 option existed both in the very first version and in the version during which I personally first bought in.
(And if you're wondering about my potential bias here: I was actually one of the top 20 NO holders, so 50% resolution instead of NO hurt. But it was the obviously-correct answer based on the stated criteria, sorry.)
@8 I outperformed 3135 people. That is odd. My behavior in this market was very stupid and irrational. I am happy I did not go bankrupt. I bought a lot of NO when it was really super high saving me. Its funny no one won that much money on this market. And both people in YES and NO camp ended up top profiteers and losers.
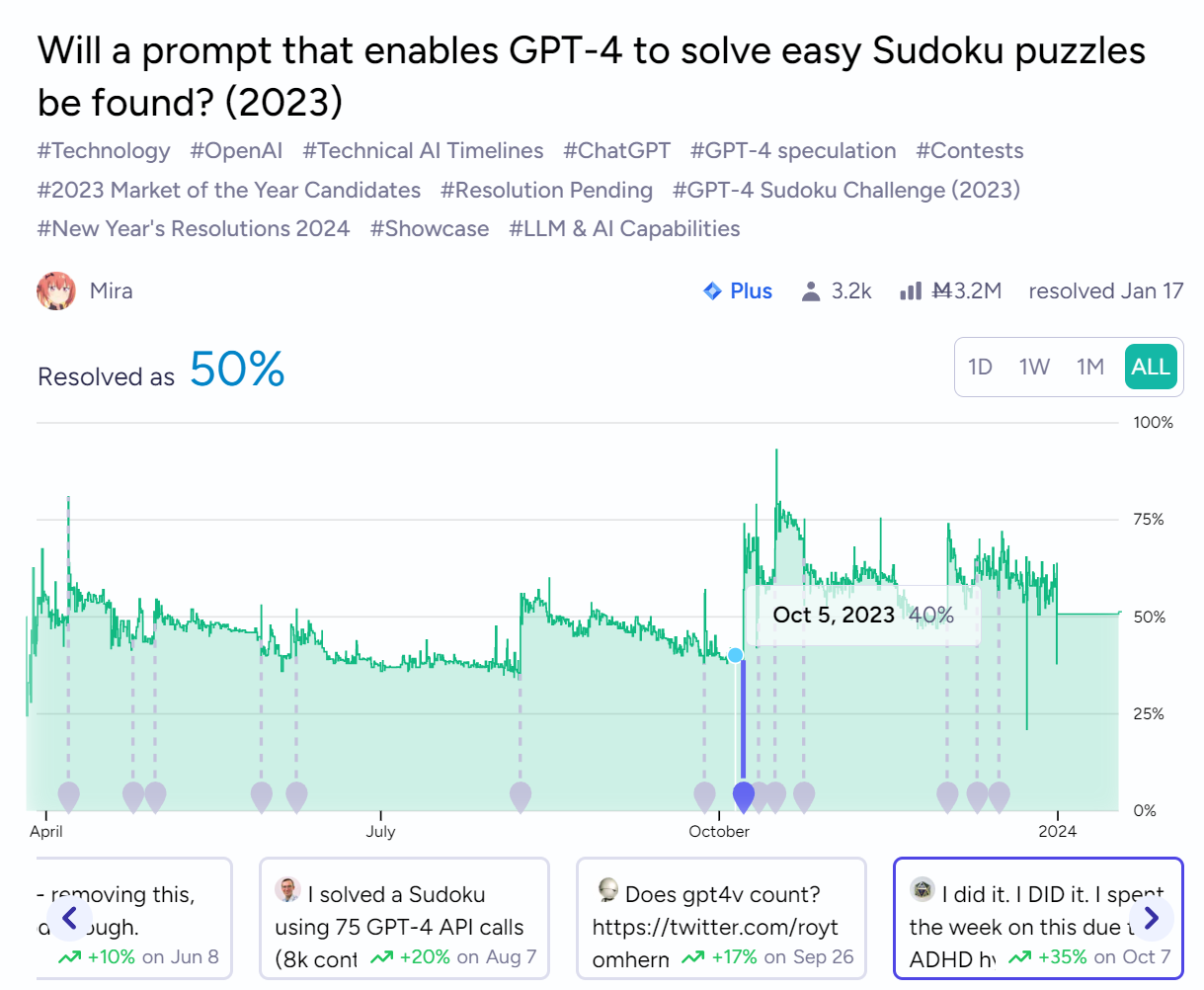
I've finished testing @EmilyThomas ' December 1 solution. It successfully solved 10/17 puzzles in the January pool of easy LA Times Sudoku puzzles before resolution was guaranteed, making the final solve percentage 59%. The other 14 days in January will not be run to save on API costs, since they cannot reach 80% solve rate.
Resources:
Emily's Prompt Submission on December 1, 2023, which was tested on the January pool
List of puzzles in the January pool
@EmilyThomas may be writing an article about the design of her Sudoku-solving prompt, and I may be writing one about this contest, the original motivations for setting it up, and the useful implications of prompts that can execute arbitrary algorithms.
I also plan to give this a challenge a try, though my own attempts won't count for this contest.
Thanks everyone for participating!
@traders This market is now guaranteed to resolve 50% or YES. A NO resolution is no longer possible.
Please review my testing summary table and let me know if you find any errors in the test transcripts on Github that could change the result.
We are at 5 failures currently. 7 failures precludes a YES resolution, so Emily's prompt must solve every puzzle remaining in January with at most 1 failure to get a YES resolution. I will stop testing early and resolve to 50% when I see 2 more failures.
@bfdc End of 2023 is when the market closes for trading and the deadline for submissions. Any submissions still need to be tested, which in the description is specified to use the January pool of puzzles from the LA times.
Otherwise, how did you imagine a solution submitted on December 31 would have its solve percentage calculated, given the requirement for freshly-generated puzzles?
@EmilyThomas Interesting. Is there a reason to believe that the 73/92 success rate in October, November, December is maybe just a lucky fluke? I place the 85% confidence interval at 13%. I am more optimistic than 1 in 120 for a YES resolution possibility, so I have been hedging quite a bit against it since I hold so much NO in this market.
well 3 auto fail in a row seems good reason to be long on any possibility of a YES resolution.
Oh yeah, I check the puzzle as soon as it comes out on the LA times site, giving me a few hours heads up on the derivative markets. I don't even have to use the simulation script, I just solve it using the same method as the prompt, and it either works or gets stuck.
...But apparently I posted the 1 in 120 value before today's puzzle came out?
Yeah, I have no idea how I came up with that number. You can get a lot of variability by using slightly different values for both the rate of eligible puzzles, and the rate of success on the eligible puzzles. I do not remember what values I used to get 1 in 120.
Even now the odds of a yes range from 1 in 200, to 1 in 7, depending on what assumptions are made about the success rate on eligible puzzles. So I have no idea what the actual value is.