
Resolves as YES if OpenAI releases a model which performs chain-of-thought on image tokens or which uses a visual scratchpad before January 1st 2026
Update 2025-04-18 (PST) (AI summary of creator comment): Tool use for chain-of-thought is valid.
If the model produces chain-of-thought on image tokens using external tools, it meets the criteria.
The model does not need to generate the tokens directly; using its built-in tool capabilities is sufficient.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ26 | |
| 2 | Ṁ24 | |
| 3 | Ṁ23 | |
| 4 | Ṁ20 | |
| 5 | Ṁ3 |
People are also trading
@MalachiteEagle Probably the best reason not to resolve is that the images are generated/modified using tools rather than by the model directly. But you didn't mention this in the resolution criteria, so resolving as YES seems reasonable
@CDBiddulph yeah I was thinking of the model producing these tokens directly, but tool use does count. Especially since the model can do all of this out of the box.
@traders I'm inclined to resolve this as YES Edit: no this isn't chain-of-thought. This is just in-context-learning.
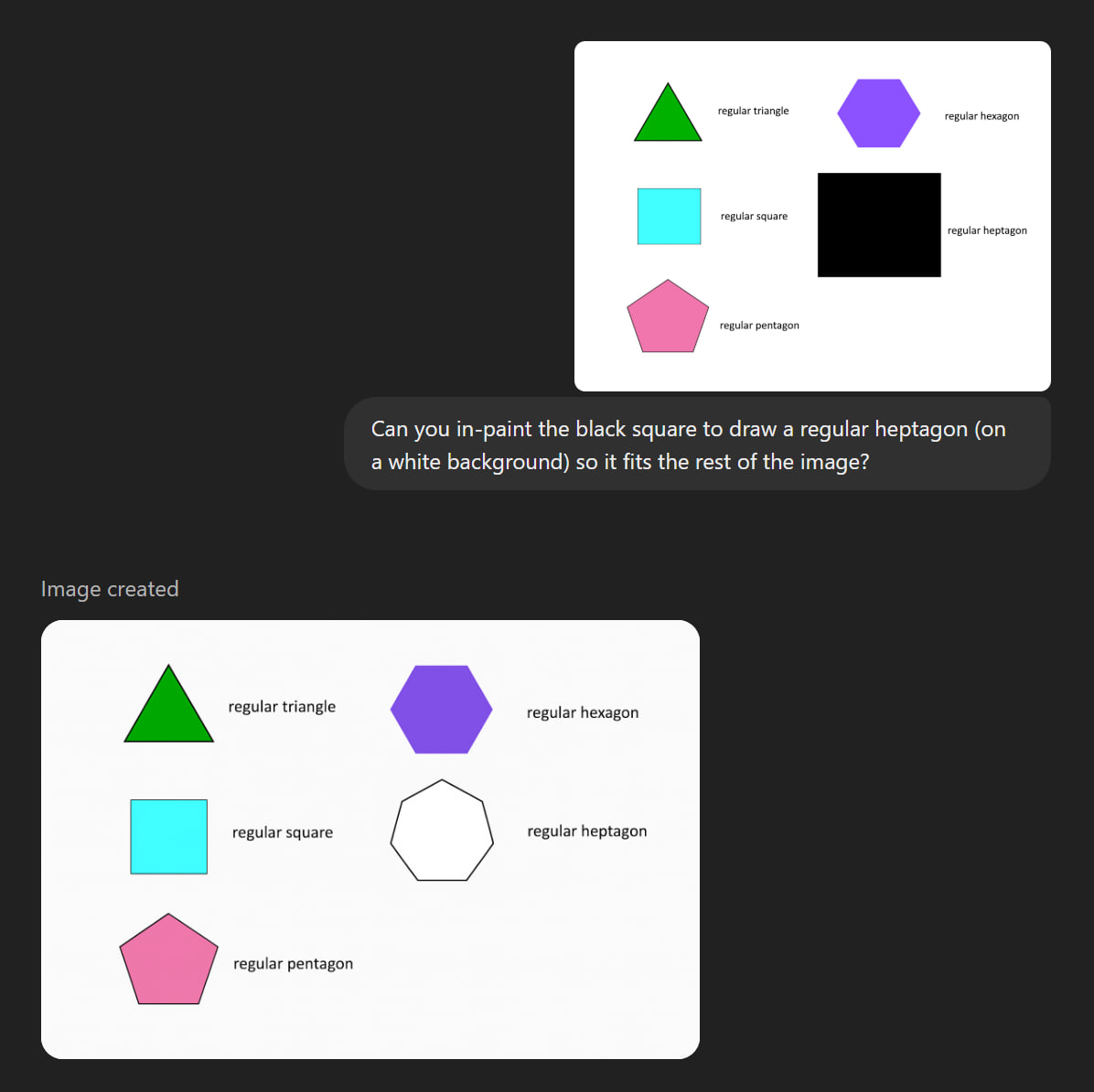
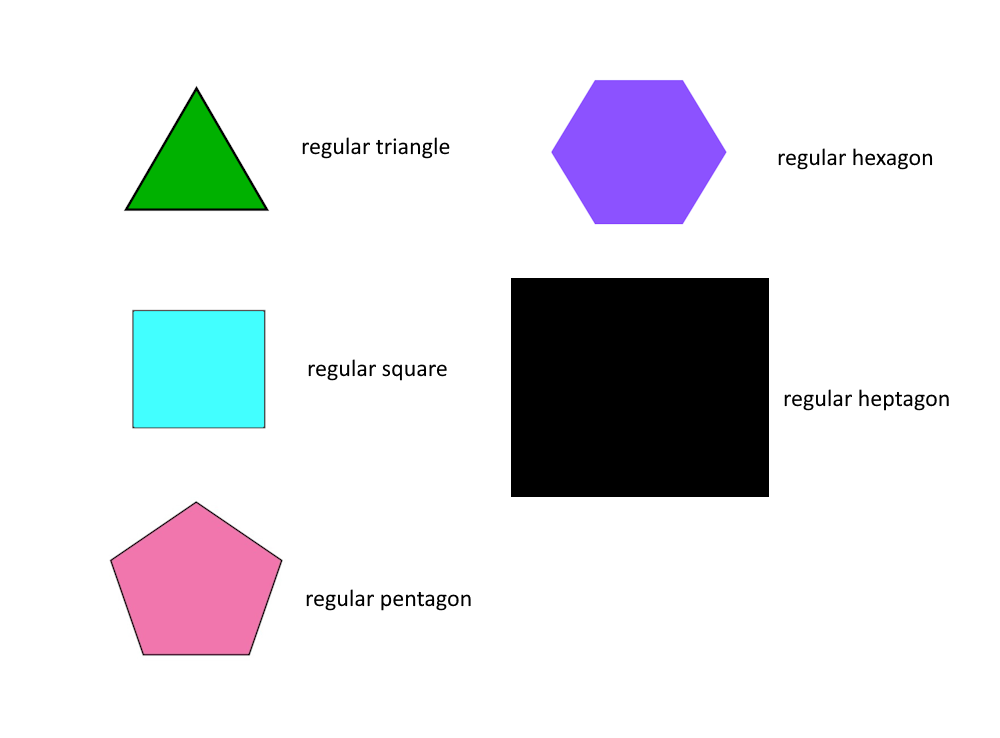
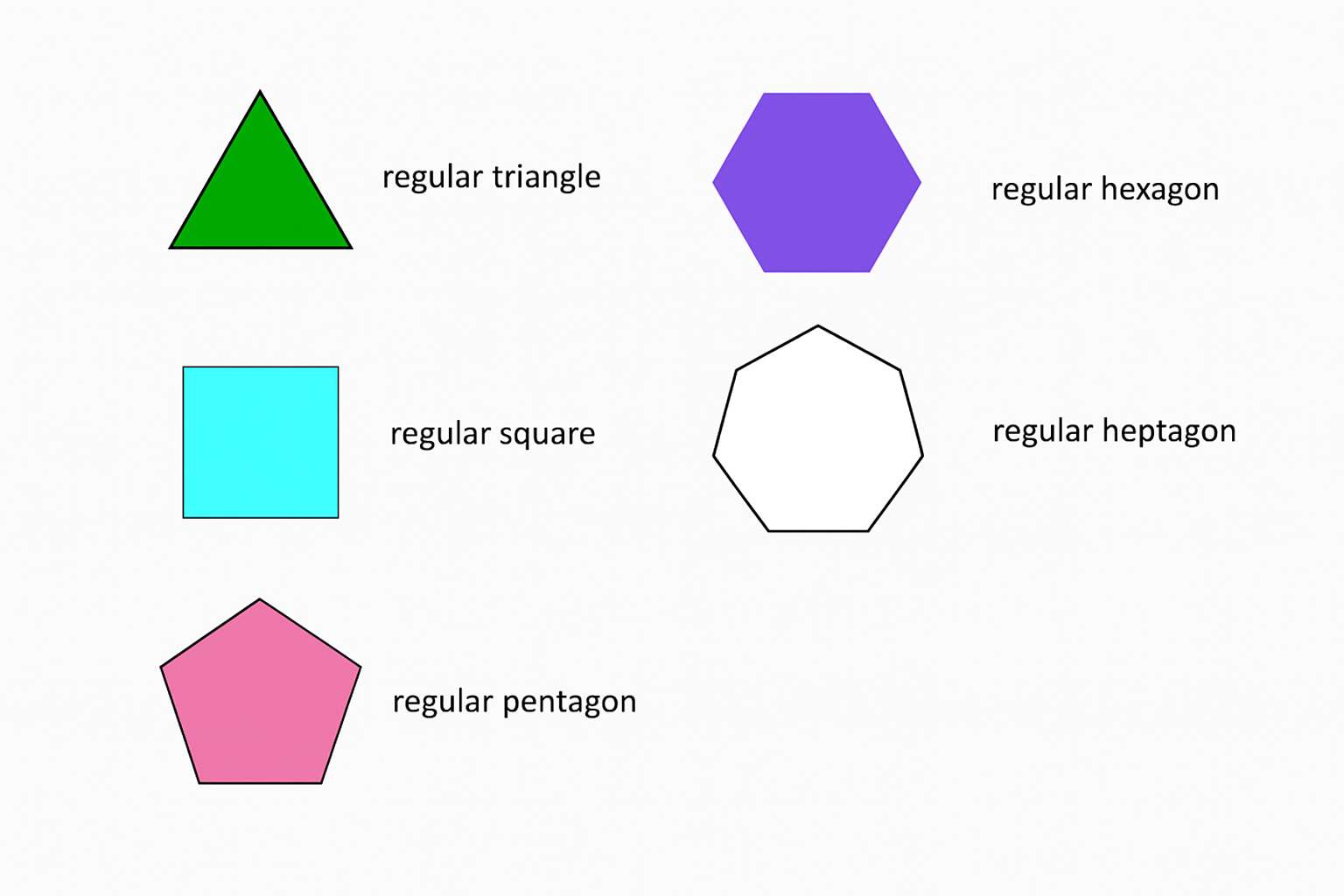
It's in-context-learning the regular polygon drawing task
Like it's not writing its thoughts down. But I think someone might get gpt-4o to express reasoning steps in the image domain but just coming up with a simple image-based prompt to elicit it.
Human language is a linear, and isn't well suited to exploring multiple lines of reasoning in parallel. We have parentheticals and footnotes, but they're weak tools for it.
I don't know that images will be used, but I do think that at some point, there will be a format that:
Is in a "language" that an LLM created, expressly for the purpose of communicating with other AI that were not trained on the same datasets as itself. A machine Esperanto.
Uses more explicit context, and uses far fewer implicit contextual clues. Machines aren't limited in reading/writing speed like humans are, they don't need to lean on unstated assumptions in their writing.
Is 2D in nature. The language will support branching and exploring multiple ideas in parallel while all the "threads" of thought/communication use a shared context. Possibly 3D or higher. This threaded communication (and thought-process) can be authored in parallel.
For images in particular, sure, I think there will be a video-generation product that outputs a "storyboard". The storyboard gets refined with user input, and only then does the process start doing low-res preview renders for futher iteration. A product that works more like a movie production workflow, rather than only operating off of a script.
@DanHomerick seems reasonable. I think there are many different modalities that can be described, and it might make sense to define reasoning tokens for each modality. These can coexist with some universal token representation.
Guess we'll find out what works!
I think also a lot of this will change as the topology of the reasoning process itself stops being a linear sequence, and as the field moves away from discrete tokens. Things may look wildly different a decade from now.