Resolves as YES if there is strong evidence that OpenAI has released true multimodal image generation features for GPT-4.5 before January 1st 2026.
The GPT-4.5 model needs to be used to produce the image tokens in order for this question to resolve as YES. Using the GPT-4.5 model to produce an intermediate text representation does not qualify. Dispatching to a surrogate model such as GPT-4o also does not qualify.
 1,000
1,000People are also trading

https://openai.com/index/introducing-4o-image-generation/
OpenAI just released 4o multimodal image generation (distinct from the previous Dalle-3 image gen) yesterday and isn't even done rolling it out.
https://openai.com/index/hello-gpt-4o/
Since 4o is innately multimodal (the o stands for omni) they've had some form of it for many months and just released it now to make sure google gets no hype.
---
https://x.com/sama/status/1889755723078443244
On the other hand 4.5 (notice the lack of o) is not a multimodal model. They probably could tack it on if they tried hard and spent a bunch of time and effort doing so, but it feels very unlikely when 5 (which will also be multimodal, and who knows if it will have a o because OpenAI is trash at naming) should be out in a few months and will natively support it.
@lemon10 I think you've got a few things confused there. GPT-4.5 was probably pre-trained as a multimodal model, just like gpt-4o. They just haven't released the image generation features yet. OpenAI haven't said yet either way if it supports output image tokens, but the likelihood that it does is pretty high. Furthermore, it appears that the GPT-5 release will use the GPT-4.5 base model initially. But again, they haven't been all that clear on this point.
@Bayesian Ok, now I'm confused. Is it possible that GPT-4.5 is calling the image generation capabilities from the GPT-4o model?
@Bayesian they said they released gpt-4o multimodal generation and silently released gpt-4.5 image generation as well???
@Bayesian this is the release blog: https://openai.com/index/introducing-4o-image-generation/
I'm so confused now. It doesn't say anything about 4.5
Models as early as bing called Dall-e when you asked them for an image, plenty of precedent for using different models for image generation and text generation
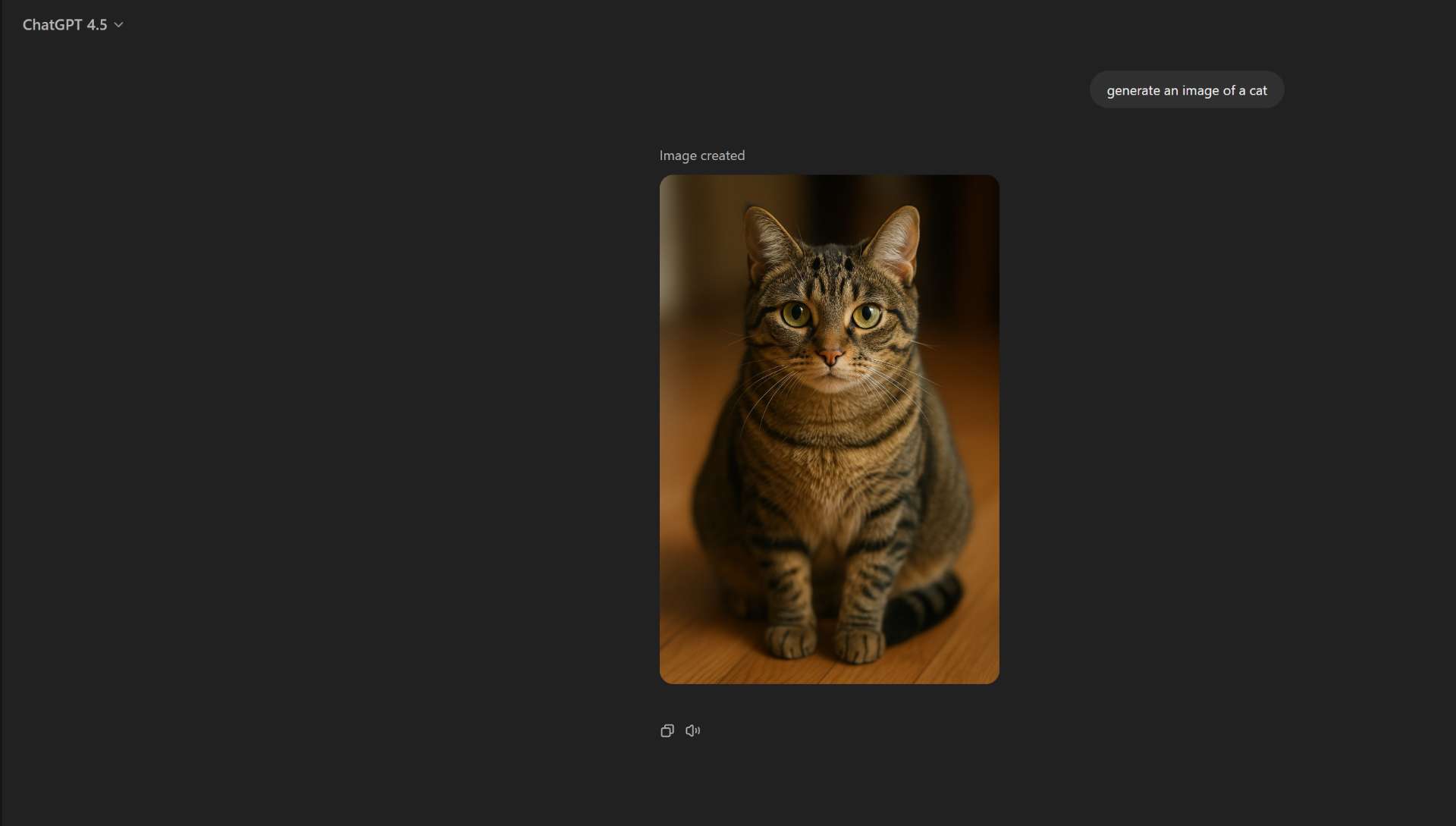
Anyway you should be able to check by seeing if you get very different image results from 4o and 4.5
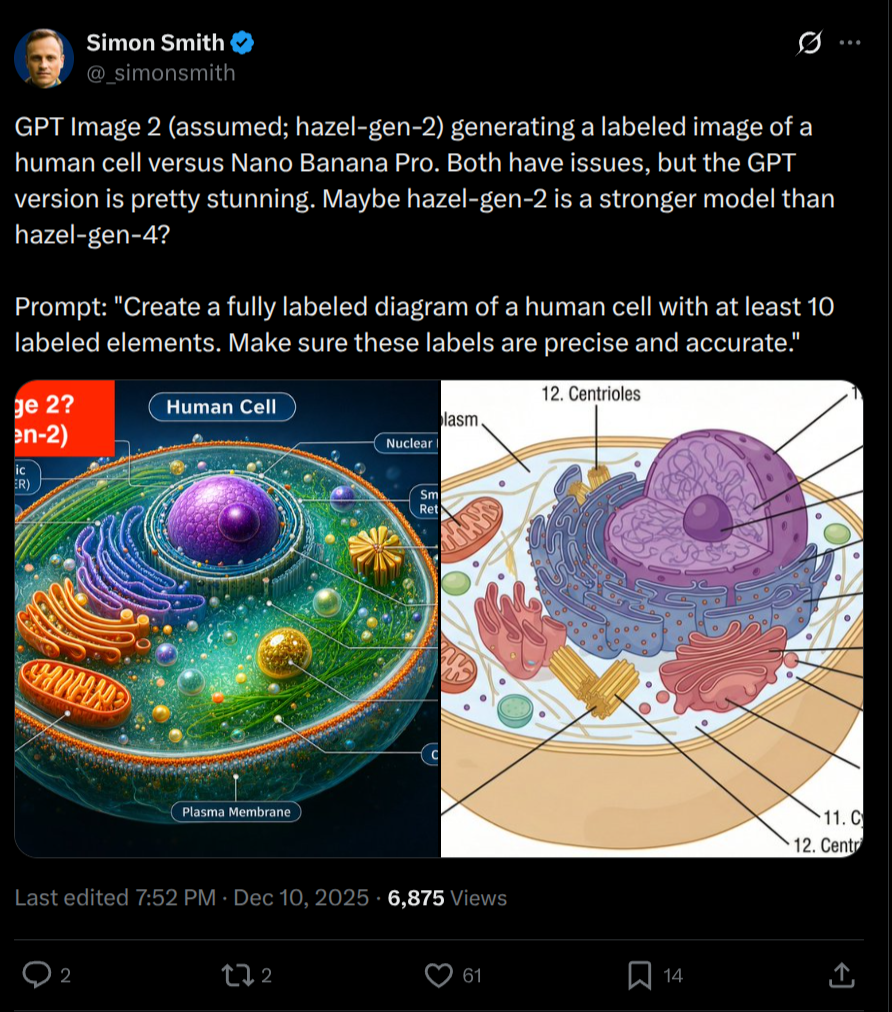
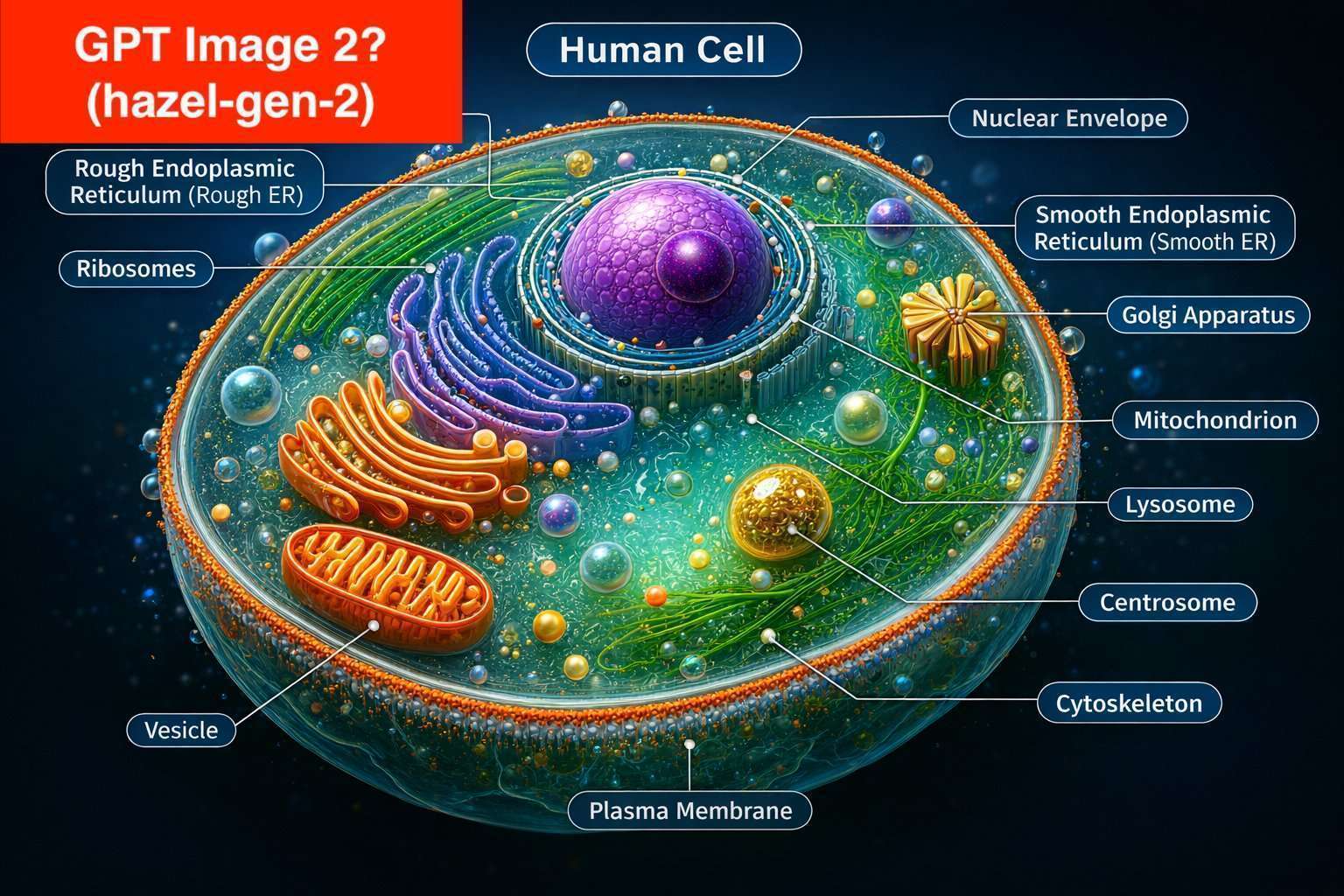
@SaviorofPlant yeah that's what I thought initially when it generated the cat, but @Bayesian is right there are people on twitter claiming that 4.5 image generation is better...
@MalachiteEagle a multimodal 4.5 would be the single biggest image generation model ever created and it wouldn't even be close, you'd expect some pretty stunning quality
@SaviorofPlant One thing I can think might be happening is that the LLM is tasked with generating a more complex prompt for the image generation. So maybe if you give a simple prompt to GPT-4o vs GPT-4.5, the expanded prompt may be of better quality when it's coming from GPT-4.5. But I have doubts that this is what's happening.
@MalachiteEagle i don't know if the criteria makes it clear that GPT-4.5 needs to be the model doing the image generation
Yeah ig i got deceived by openai but i agree model likely switches to 4o when generating image output. They can swap them no problem. I might be misunderstanding what ur saying but with the image output model there’s no like subprompting the image step by the text model or something, the omni model takes user prompt and creates the image directly, and i strongly suspect 4.5 just doesnt participate in the interaction when they detect ur asking for an image
I could easily be wrong about some stuff. Hard to say given how tight lipped they are about a bunch of the technical details.
Re: Using 4.5 for 5
https://i.imgur.com/GqZTv93.png
It sounds like 5 is going to work pretty differently. I think they are going to do a whole new training run. But shrugs, I don't work at OpenAI.
---
Yeah, 4.5 almost certainly just sends the instructions to 4o the same way that it used to just send the instructions to Dalle.
@SaviorofPlant one explanation that fits what they seem to have said so far, would be for them to have multiple unified models of different sizes. Then a router model to switch between different unified model sizes dynamically.