
Feb 19, 7:42pm: Will a different machine learning architecture that is much faster (at least 5x) than current SOTA (Transformers) be released in 2023? → Will a different machine learning architecture that is much faster or much cheaper (at least 5x) than current SOTA (Transformers), for both inference and training, be released in 2023?
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ80 | |
| 2 | Ṁ70 | |
| 3 | Ṁ39 | |
| 4 | Ṁ30 | |
| 5 | Ṁ27 |
People are also trading
Note that Mamba doesn't even come close to approaching this in terms of training costs, see the scaling laws graph on page 12 of the paper: https://arxiv.org/pdf/2312.00752.pdf
Are modifications like FlashAttention in the SOTA Transformer for comparison?
https://arxiv.org/pdf/2205.14135.pdf
@NoaNabeshima If they are this seems tricky to compare, but doable I imagine.
One way to resolve is to just compare to the fastest to train and infer implementation that's transformer-based with publicly-available statistics at the time the non-transformer architecture is announced.
Another way to interpret this question is referring to some base transformer implementation (GPT-2?) and then not including newer architectures that seem transformer-based (or else it might resolve YES already I think?).
A third way is to just consider architectures as a series of einsums and nonlinearities and then see which one is faster in vanilla pytorch w/o modifications like lower FP precision or GPU-optimized operations.
I like the idea of this market, but how are you operationalizing "transformer" (e.g., what parts of the attached blueprint can be removed for it to no longer count), and what accuracy or other performance measure is required (e.g., as currently worded, I can train a stack of linear regressions at least 5x faster than a transformer)?
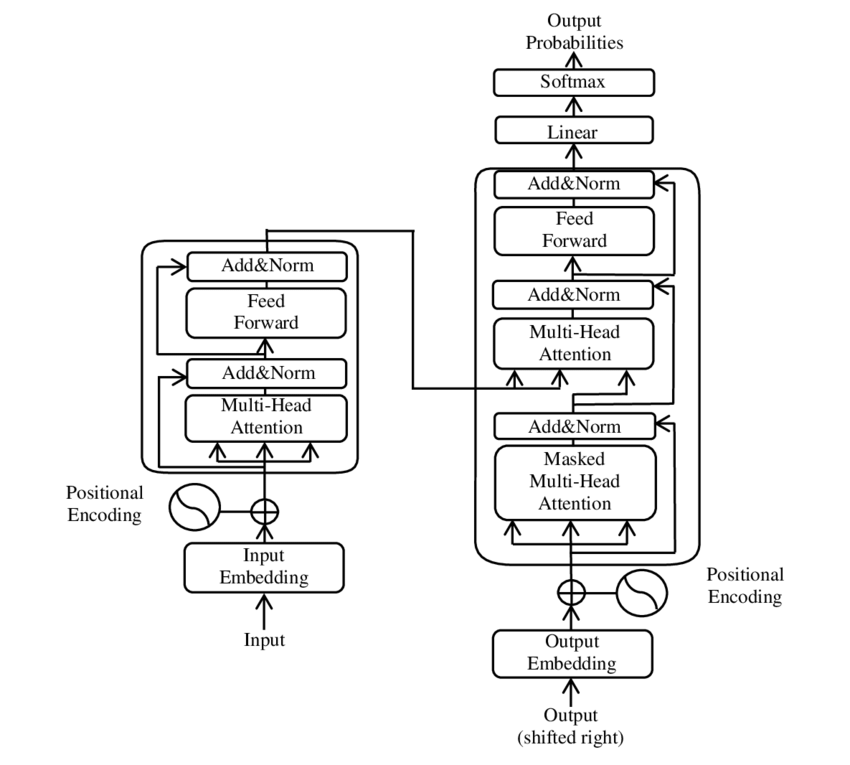
@vluzko Good question, I'm going to specify it should be either much faster or much cheaper in both inference and training