
By Nov 12 2025, will there be a model that meets all of these criteria:
>84.6% on the Artificial Analysis Quality Index
ie the average of benchmark scores on
MMLU
GPQA
MATH
HumanEval
MGSM
with no regressions on any individual benchmark
Note:
does not need to be an OpenAI model
open weights or free models will count as cheaper
quantized/distilled versions count, as long as they also beat the same accuracy thresholds
Update 2025-11-05 (PST) (AI summary of creator comment): Creator has indicated they are ready to resolve YES based on Gemini 2.5 Flash-Lite (September 2025 Preview) meeting the criteria, unless there are strong objections. See linked comment for details.
Update 2025-11-14 (PST) (AI summary of creator comment): Creator has stated they are uncertain whether the criteria are met and has delegated the resolution decision to moderators.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ281 | |
| 2 | Ṁ238 | |
| 3 | Ṁ148 | |
| 4 | Ṁ67 | |
| 5 | Ṁ56 |
People are also trading
Looked a bit more closely, it’s not clear to me this is a yes. too busy atm to dive into this properly - @mods can you decide?
We're definitely getting closer to the range that's >10x faster than o1-mini and more powerful than o1-preview. But that threshold is very clearly not met yet. Therefore this question resolves NO.
I think if you'd put the resolution date 18 months into the future instead of 12 then there'd be a model to point to meeting this critera. But that model does not exist today.
@nosuch I can't read these charts this is all gibberish to me, but from what little I can parse and the evidence presented by Dulaman I'm resolving NO.
updated analysis with @moozooh suggestion about MMLU vs Global MMLU Lite: https://imgur.com/a/stG68ew
note to @traders: this question resolves NO but the creator has a very large YES position. So beware we may have to call in the mods to adjudicate if there are shenanigans
although the creator's track record indicates authentic question resolutions 🤣

https://manifold.markets/nosuch/a-major-ml-paper-demonstrates-symbo#6qfratfb7in
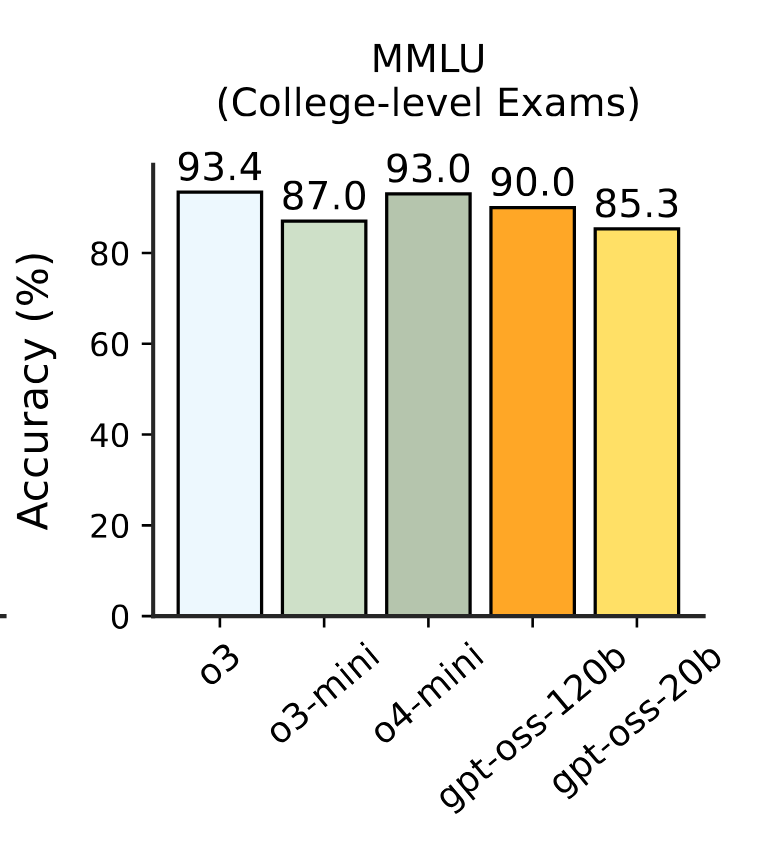
@Dulaman I think there is enough direct and/or circumstantial evidence that GPT-OSS-120B sufficiently clears the criteria (I'd initially overlooked it because I didn't know there were providers that were sufficiently fast); it's not the creator's fault the question was asked when the landscape was completely different so that models released closer to the market's deadline aren't tested on the exact same benchmarks. This probably needs more discussion, though. (I sold my positions before the market was locked so I don't have a stake in this no matter how it resolves anymore.)
@moozooh GPT-OSS-120B does not qualify: it gets 90.0 on MMLU per OpenAI's own evals
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
O1-preview gets 90.8 on MMLU: https://github.com/openai/simple-evals
@Dulaman That's not a meaningful distinction. Besides, MMLU contains a non-insignificant percentage of wrong answers so it's impossible to max it out in principle or even tell which model is better if it's too close to another.

@Jasonb Not sure, never tried there Api. But it is certain that they are fast, I have used their inference through mistral.ai chat and it is amazingly fast.
Also, they say that hey are able to infer at 3000 token per second. But 1000 would be largely enough to resolve this market, so I am confident it will be a yes
@Valchap According to https://artificialanalysis.ai/models/gpt-oss-120b, this fits the criteria (there are at least three API providers listed with >720 tok/s inference, and the price and intelligence index thresholds are also hit).
@Jasonb I think their rating is some sort of an aggregate figure but they do show exact measurements for each API provider which is certainly very helpful.


There's a model that fits your criteria: Gemini 2.5 Flash-Lite (September 2025 Preview).
https://artificialanalysis.ai/models/gemini-2-5-flash-lite-preview-09-2025-reasoning/
1. 756 tok/s per ArtificialAnalysis.
2. $0.1/Mtok input, $0.4/Mtok output.
3. As of the AAII v3 suite, its score is 48 vs o1-preview's 45 (old index used benchmarks that have been saturated since, so aggregate scores have lowered across the board). Individually, as far as I can tell, there are no statistically significant regressions; 71% vs. 73% on GPQA Diamond probably shouldn't be considered one in the spirit of the question.
@moozooh nice catch - I’m ok with resolving with yes at this point unless folks have strong objections they want to discuss
@Jasonb It's true, they seem to have revised the numbers; it was 756 tok/s when I checked a week ago. :( Oh well.
@Jasonb No idea what's going on but it's too risky to rely on the numbers stabilizing on >720 when the time comes.

@Dulaman Reminder to never go full GPT: the research-grade intelligence™ happily conflated MMLU (raw knowledge of scientific facts) and Global MMLU Lite (cultural/linguistic biases applied to scientific facts), two separate benchmarks.
https://www.kaggle.com/benchmarks/cohere-labs/global-mmlu-lite

