
MoE
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ1,317 | |
| 2 | Ṁ721 | |
| 3 | Ṁ551 | |
| 4 | Ṁ550 | |
| 5 | Ṁ265 |
People are also trading
@MP Hasn't been confirmed by OpenAI yet. It could be a psy-op to mislead the other AI labs into pursuing dead-end research.
@ShadowyZephyr per SemiAnalysis
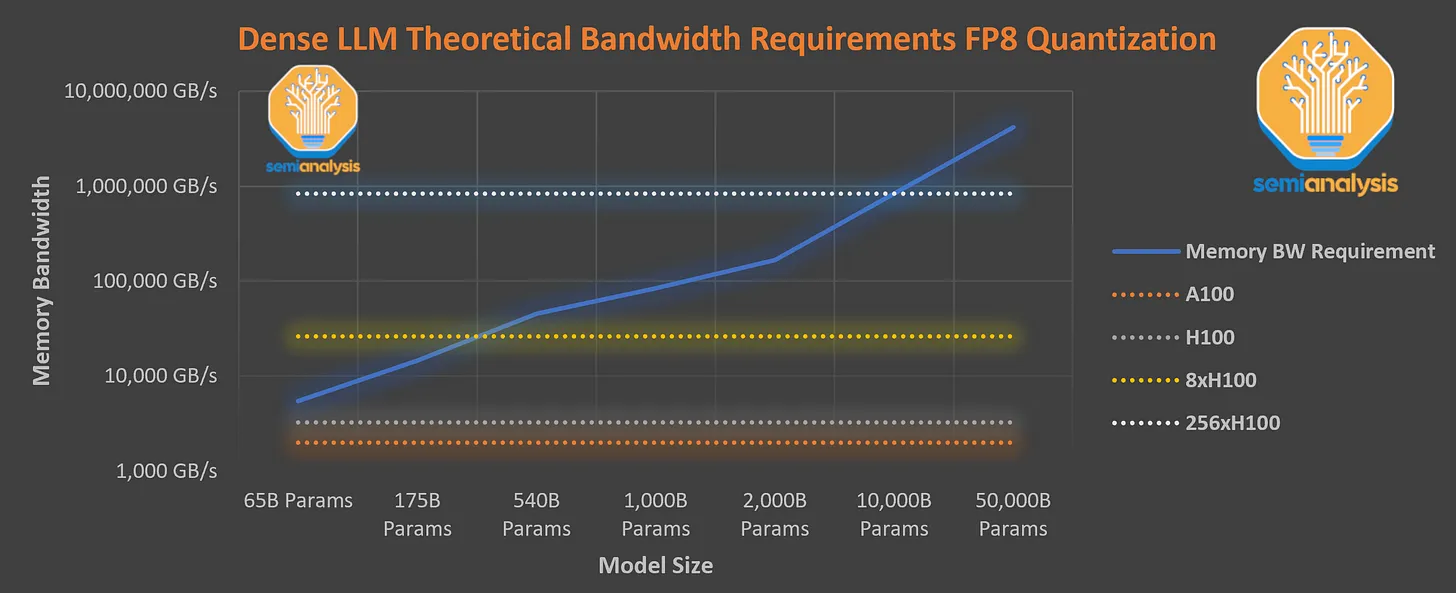
LLM inference in most current use cases is to operate as a live assistant, meaning it must achieve throughput that is high enough that users can actually use it. Humans on average read at ~250 words per minute but some reach as high as ~1,000 words per minute. This means you need to output at least 8.33 tokens per second, but more like 33.33 tokens per second to cover all corner cases.
A trillion-parameter dense model mathematically cannot achieve this throughput on even the newest Nvidia H100 GPU servers due to memory bandwidth requirements. Every generated token requires every parameter to be loaded onto the chip from memory. That generated token is then fed into the prompt and the next token is generated. Furthermore, additional bandwidth is required for streaming in the KV cache for the attention mechanism.
The chart above demonstrates the memory bandwidth required to inference an LLM at high enough throughput to serve an individual user. It shows that even 8x H100 cannot serve a 1 trillion parameter dense model at 33.33 tokens per second. Furthermore, the FLOPS utilization rate of the 8xH100’s at 20 tokens per second would still be under 5%, resulting is horribly high inference costs. Effectively there is an inference constraint around ~300 billion feed-forward parameters for an 8-way tensor parallel H100 system today.
Yet OpenAI is achieving human reading speed, with A100s, with a model larger than 1 trillion parameters, and they are offering it broadly at a low price of only $0.06 per 1,000 tokens. That’s because it is sparse, IE not every parameter is used.
SemiAnalysis is a very reputable source and if they are saying it's impossible to have a 1T dense model (they say they talked with many people in many labs, including OAI), it's safe to say it's a MoE
@DavidChee IMO, there's plenty of evidence. This also released today with a lot more extensive details, also saying that it's MoE: https://www.semianalysis.com/p/gpt-4-architecture-infrastructure

George Hotz claims GPT-4 is an 8-way mixture of experts model.
Symbolic bet, because I don't think GPT-4 is MoE, but I think it's likely this will not resolve for a long time if ever.
Edit: People are saying it's MoE, interesting that OpenAI is still having issues with scaling lol
Yes appears overvalued here. The GPT-4 dense model (which has 3x the volume of this market) is at 33% right now. MoE models are not dense, so these are mutually exclusive. However, there are more sparse model types than just Mixture of Experts. I don't believe this warrants a 91% (61/67) certainty that his sparse model turns out to be MoE, especially given the poor performance of these types of models in the past.
@NoaNabeshima Notably ChatGPT inference seems a lot slower than Bing inference. That could just be because Bing uses smaller models sometimes.
Someone at Anthropic mentioned that OpenAI might be throtting gpt-3.5-turbo.
Once you get the prompt hidden states, you want to use those for generation as quickly as possibly on the same GPU/cluster of GPUs, right? Then if too many people are trying to generate simultaneously, I'm imagining that would just lend itself to longer lag at the start of generation but not lag in next-token streaming. It's possible OpenAI actually generates the next tokens quickly and then sends them to the user slowly (so that the user queries the API at a slower rate).