I'll have a poll a week after the first "flagship" version of Gemini 3.0 is released Flagship excludes lower compute versions, that have historically had names like "flash" or "flash lite".
The poll will ask: "Is Gemini 3.0 basically state of the art at everything?"
I will let market participants interpret this question as they see fit / to their preferred level of pedantry.
I reserve the right to close the market right before the Gemini 3.0 release or in the week leading to the creation of the poll, but the market will definitely close before the poll is created to avoid particularly bad incentives.
 1,000
1,000People are also trading
@Usaar33 I think there's to some extent similar token rationing with Gemini 3.0, depending on how you're interfacing with it, where it does a similar thing to GPT-5 where if your prompt is simple, it'll give you the Fast version
Trying it out for Lean 4 theorem proving through GitHub copilot, I had it attempt a set of problems I had Claude 4.5 do last night.
Looks like it proved the same theorems. It also proved one additional theorem by changing the definition, but it also looks like the definition might have been wrong to begin with, so I guess I chalk it up as a win for Gemini 3.0.
Gemini 3.0 is very far from being SOTA in the most important category: hallucinations. Models have gotten pretty smart nowadays in pretty much every test. It's not intelligence they lack anymore, but reliability. Gemini 3.0 is almost unusable compared to Claude or GPT-5.1 (high) for any serious work because it's so darn unreliable. If it doesn't know the answer or doesn't have the token budget to find it, it simply makes shit up. I don't think it's because Google benchmaxed it, but they certainly didn’t really penalize it for wrong answers. OpenAI and Anthropic have taken a hit in the benchmarks to make their AIs much more reliable. Google did not, which artificially inflates their benchmark scores.
Source: https://artificialanalysis.ai/?omniscience=omniscience-hallucination-rate
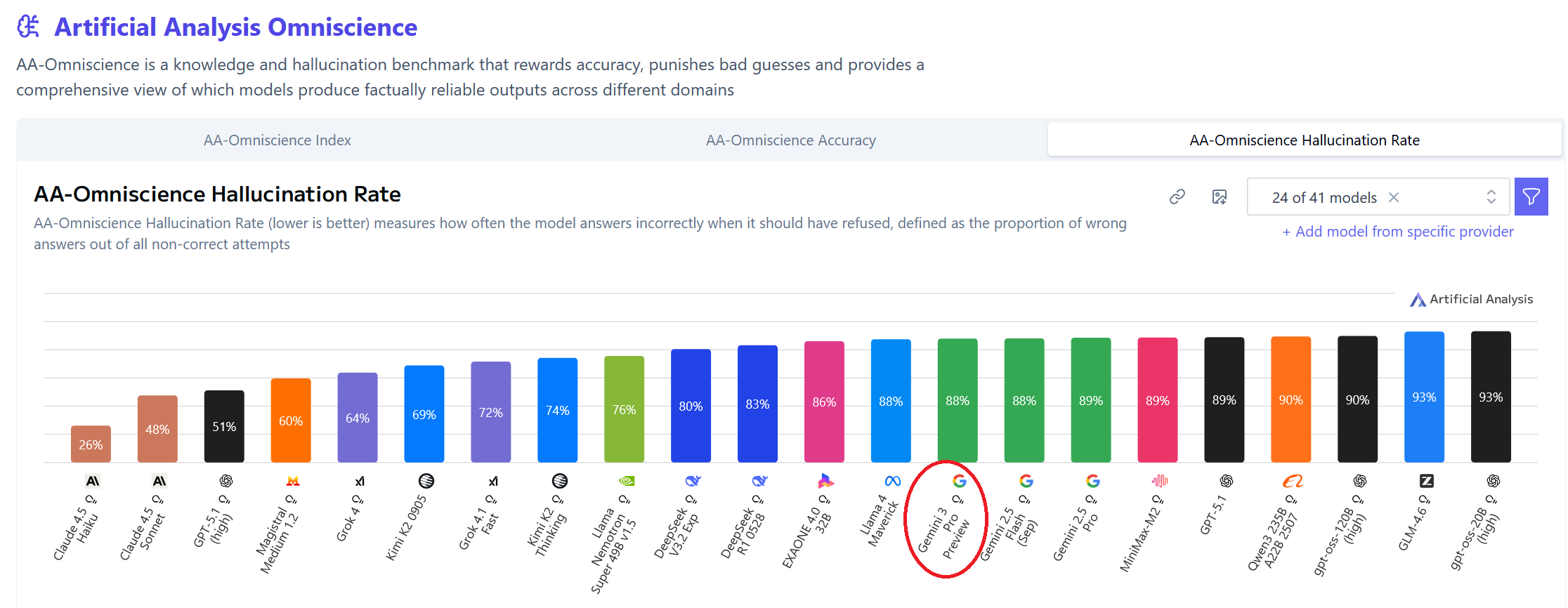
@ChaosIsALadder The difference between GPT-5.1 and GPT-5.1 (high) is interesting here. I wouldn’t have expected the token budget to make such a difference to hallucinations.
@eapache I don’t think it does, they didn’t only work on token budgeting, they also further worked on hallucinations
@Bayesian Thank you Bayesian, but I can't meet you there until a few people buy enough YES "Will 5,000+ Gazans starve" at its new low price. Not to sell, but so I can justify to myself buying much of anything else.