By portable, I mean under 3.6 kg (8 pounds). The device should be commercially available.
Update 2025-08-06 (PST) (AI summary of creator comment): The creator will wait a few days before resolving, as independent benchmarks appear to show significantly worse performance than those reported in the model card for the proposed qualifying model.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ130 | |
| 2 | Ṁ46 | |
| 3 | Ṁ3 | |
| 4 | Ṁ1 |
People are also trading
@sortwie Resolves as YES. OpenAI's gpt-oss-20b fits the bill (model card https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf)
Using ollama or llama.cpp you can easily run it on a laptop faster than the original GPT-4 even without GPU. GPU would be significantly faster though (I've got 200 tokens per second on my RTX 4090).
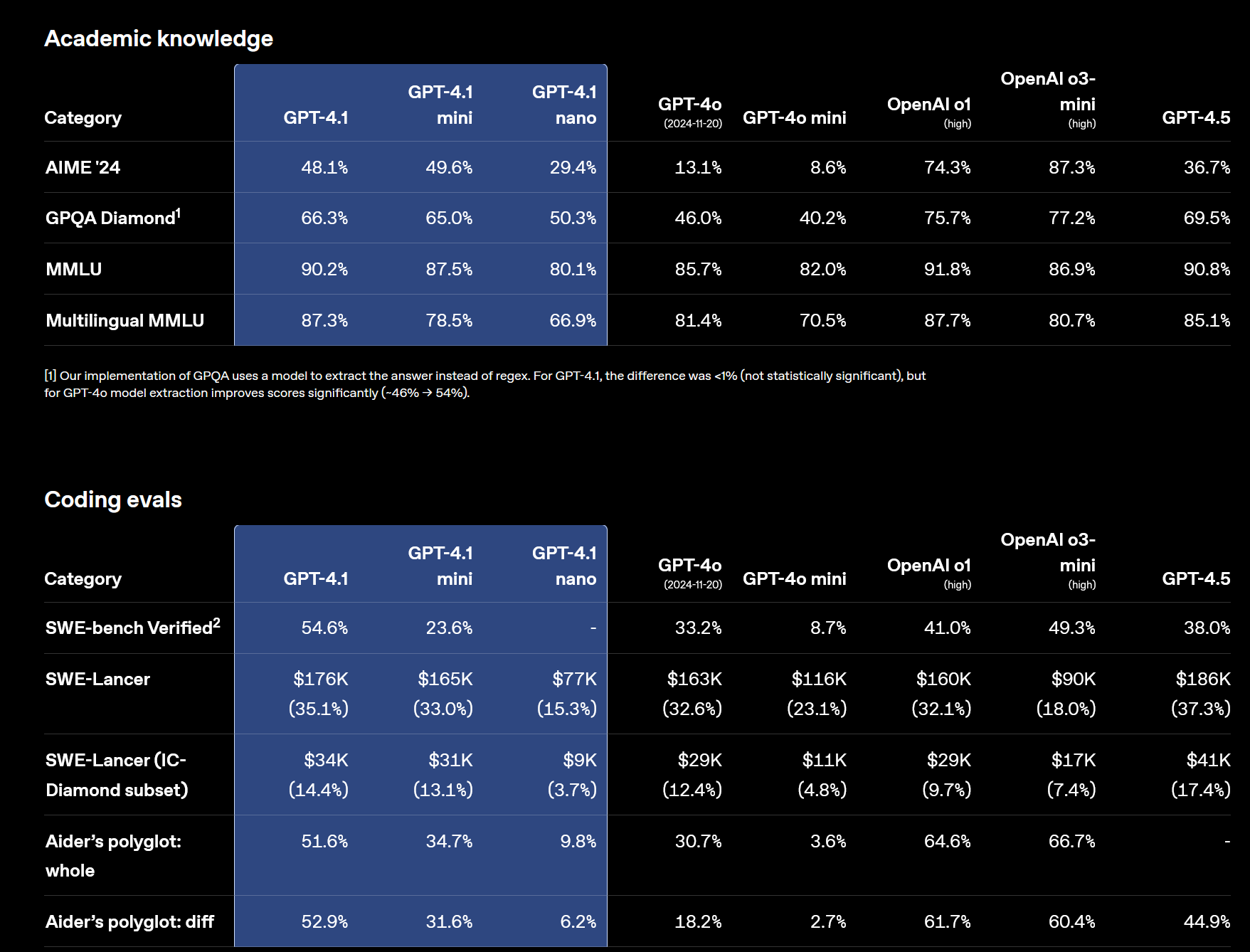
As for capabilities: gpt-oss-20b destroys GPT-4 in a direct comparison. It's not even close. GPT-4 still occasionally struggled with primary school math. gpt-oss-20b aces competition math and programming, while performing at PHD level on GPQA (page 10 of the model card, see screenshot below):
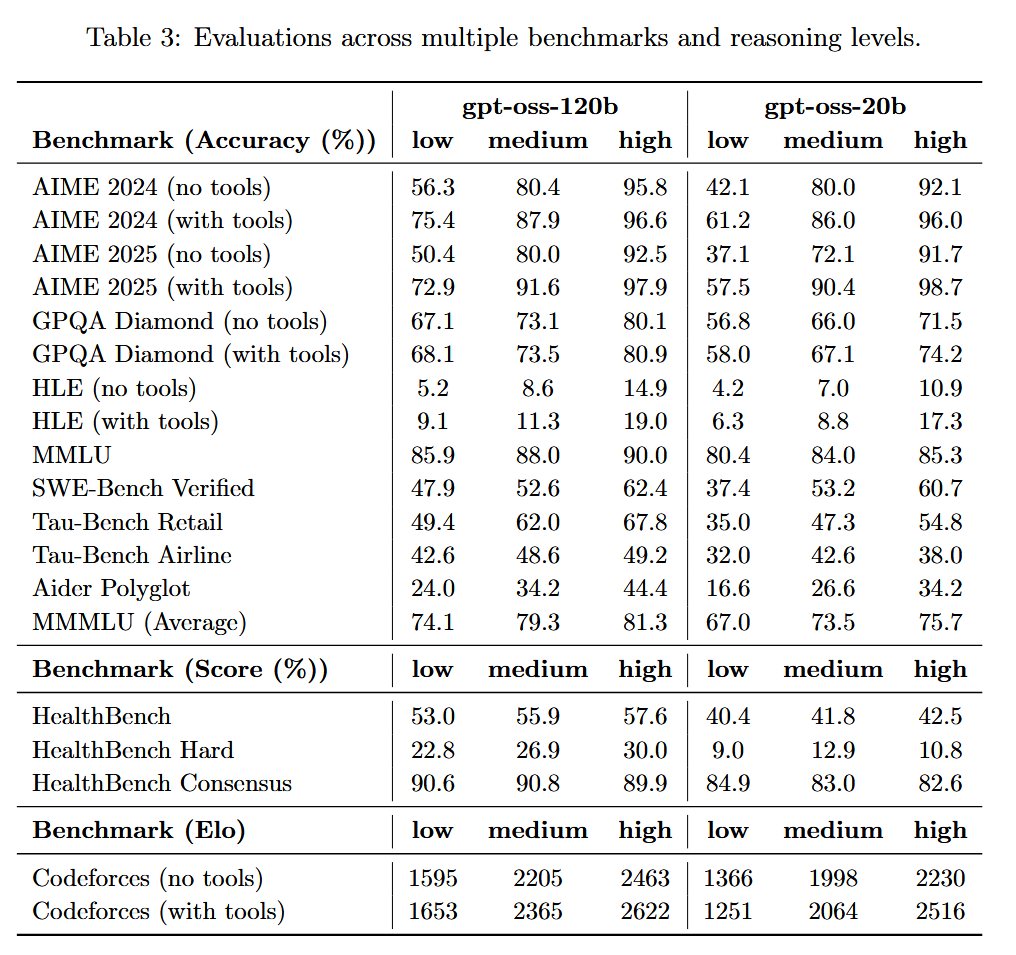
AIME 2024 (no tools)
• 20b: 92.1%
• GPT-4 (orig): ~10–15% (proxy: GPT-4o reported 12% and the 2023 GPT-4 wasn’t better on AIME-style contests). Result: 20b crushes it.
(https://openai.com/index/learning-to-reason-with-llms)AIME 2025 (no tools)
• 20b: 91.7%
• GPT-4 (orig): no reliable public number; based on AIME-2024 behavior, likely ≤20%. Result: 20b ≫ GPT-4.GPQA Diamond (no tools)
• 20b: 71.5%
• GPT-4 (orig baseline): ~39%. Result: 20b ≫ GPT-4.
(https://arxiv.org/abs/2311.12022?utm_source=chatgpt.com)MMLU (5-shot)
• 20b: 85.3%
• GPT-4 (orig): 86.4%. Result: roughly parity (GPT-4 a hair higher).
(https://arxiv.org/pdf/2303.08774)SWE-bench Verified
• 20b: 60.7%
• GPT-4 (orig): 3.4% (20b simply crushes GPT-4)
(https://openreview.net/pdf?id=VTF8yNQM66)Codeforces Elo (no tools)
• 20b: 2230 (with tools 2516)
• GPT-4 (orig): no official Elo; GPT-4o scored ~808. So original GPT-4 likely sub-1k on this setup. Result: 20b ≫ GPT-4.
(https://arxiv.org/html/2502.06807v1)
@ChaosIsALadder I'm inclined to agree, but I'll wait a few days. Independent benchmarks appear to be significantly worse than those reported in the model card.
@sortwie Yeah, please do wait to make sure OpenAI isn’t pulling a fast one. My personal anecdote: I was testing the model for work and also thought it was less smart than it should be, until I realized you have to put "Reasoning: high" in the system prompt. I suspect that’s why people get worse results than those in the model card. No model had this until now, so they might have forgotten to do it. I think this is why, e.g., https://artificialanalysis.ai/models/gpt-oss-120b rates gpt-oss a bit worse than Qwen3. When you scroll down, you see it uses a lot fewer tokens than Qwen:
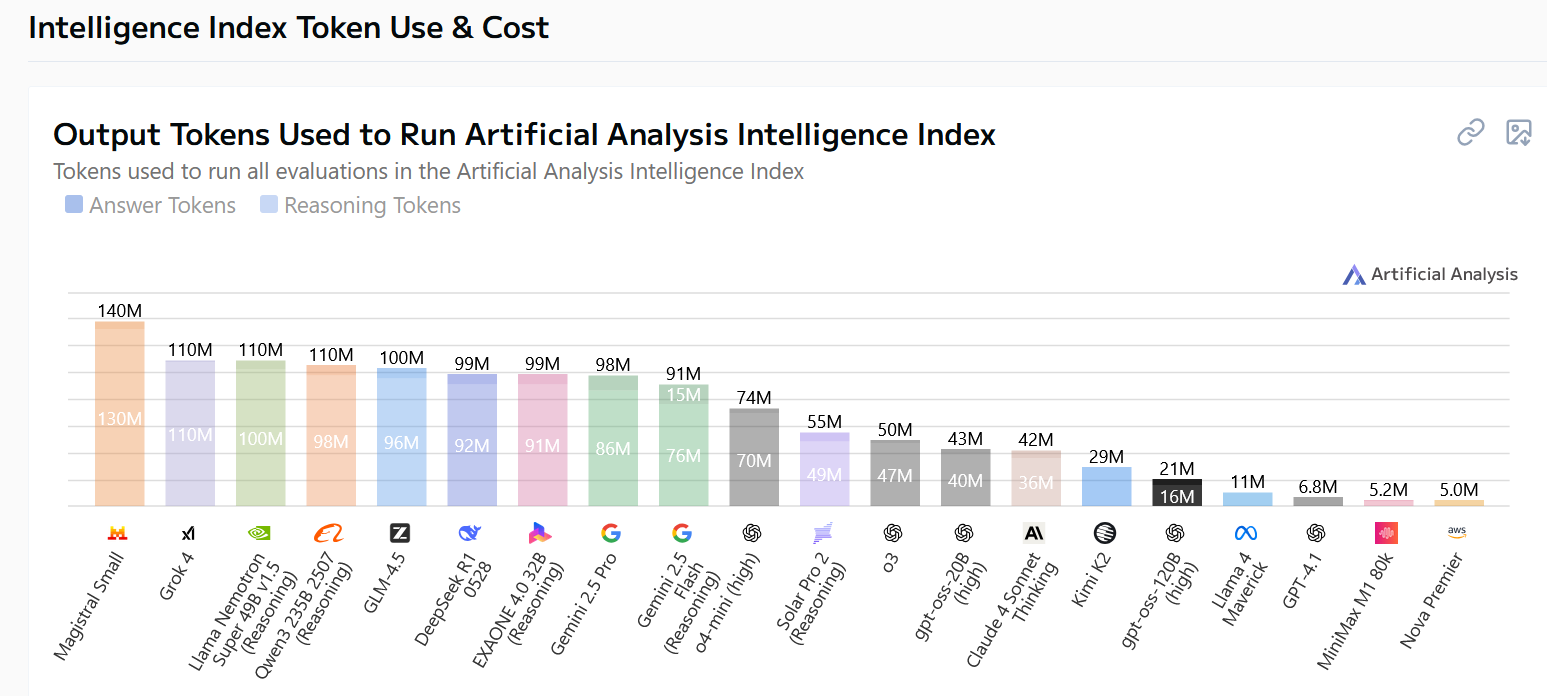
At least in our internal testing gpt-oss always scored at least as well as Qwen3 and occasionally better, but only after I set the reasoning to high. In any case, even without the setting, gpt-oss still utterly trounces the floor with the original GPT-4.
@sortwie Artificial Analysis just improved their score for gpt-oss from 58 to 61, now clearly rating it above Claude 4 Sonnet Thinking, and GPT 4.1 and DeepSeek R1 0528. Like I've said, it turns out that setting up gpt-oss correctly is non-trivial to the point the Artificial Analysis now actually has a benchmark on how well of a job the providers did with the setup. There's quite high variation, which explains the occasional reports about worse than expected performance (https://nitter.net/ArtificialAnlys/status/1955102409044398415):
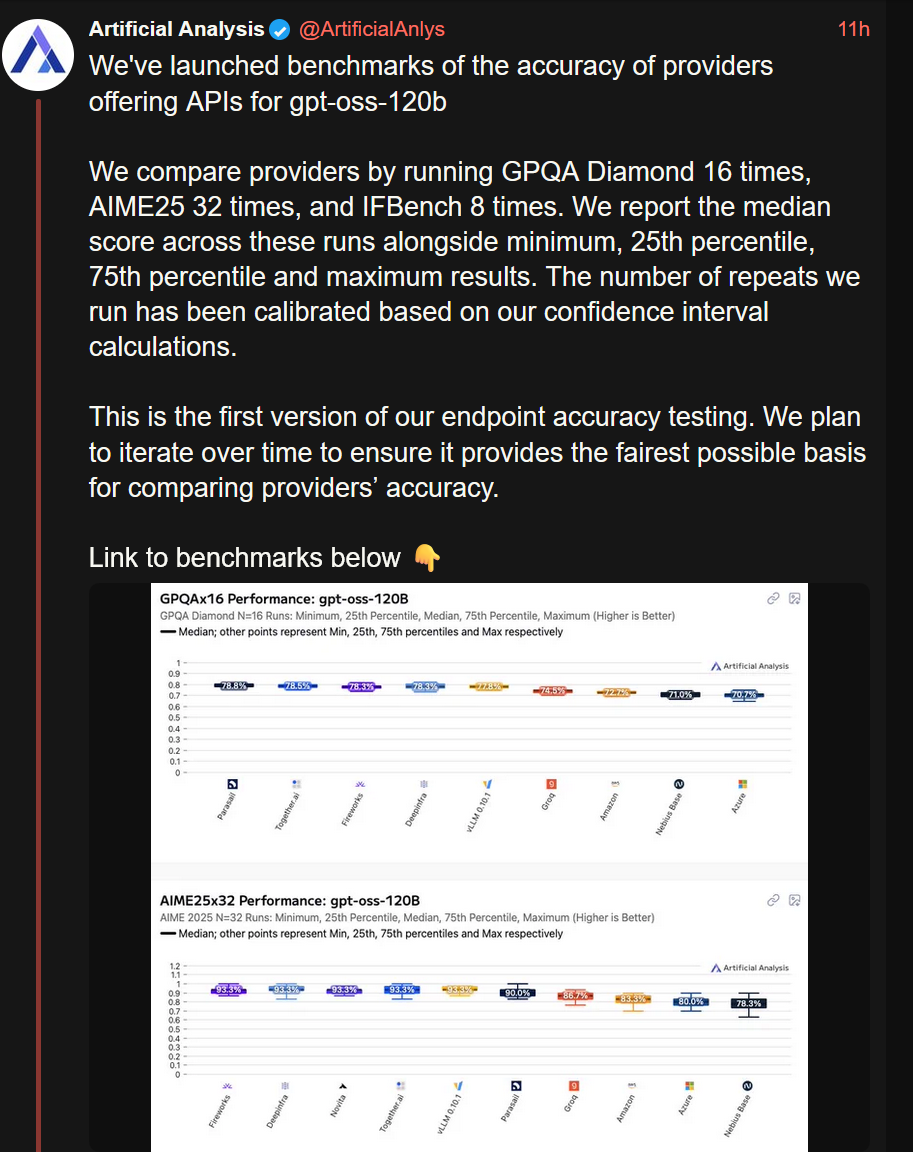
In any case it's very clear that gpt-oss-120b beats the hell out of GPT 4.1 which in turn is clearly better than GPT-4o / GPT4 (https://openai.com/index/gpt-4-1).