Update: results are posted here: https://firstsigma.github.io/midterm-elections-forecast-comparison
The summary results are:
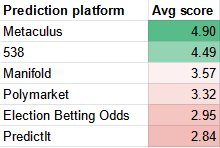
See the post for details and analysis.
It's interesting to compare forecasts between different prediction platforms, but it's rare for them to have questions that are identical enough to compare easily. Elections offer one helpful opportunity.
I will score several prediction platforms on a set of 10 questions on the outcome of the 2022 US midterm elections: Senate and House control, and several individual Senate and gubernatorial races with high forecasting interest.
For each prediction platform, I will take the predicted probabilities on Monday evening, and compute the average log score on these questions. This is a measure of prediction accuracy - higher log score means better accuracy.
I plan to compare these prediction platforms:
538 (statistical modeling and poll aggregation)
Polymarket (real-money prediction market)
PredictIt (real-money prediction market)
Election Betting Odds (prediction market aggregator)
Manifold (play-money prediction market)
Metaculus (prediction aggregator)
Others can be added, just add a comment with the data on their predictions for each of the questions above.
Important note: the election is much closer to one overall prediction than a set of independent predictions, because the races are highly correlated. The forecast that scores best is probably going to be the forecast that landed closest to the mark on the broader question of how much the nation overall went left or right, or how far left or right the polls were biased - and a large part of this is chance. So despite the large number of individual races, each election cycle can be thought of as roughly one data point, and to truly measure accuracy well, we'd need to run this experiment several times over different election cycles.
Of course, I've also created meta prediction markets on which prediction platform will be the most accurate: https://manifold.markets/group/election-forecast-comparison
Questions compared
I selected this set of 10 questions to compare across prediction platforms:
Senate control
House control
Senate races
Pennsylvania - Mehmet Oz (R) vs John Fetterman (D)
Nevada - Adam Laxalt (R) vs Catherine Cortez Masto (D)
Georgia - Herschel Walker (R) vs Raphael Warnock (D)
Wisconsin - Ron Johnson (R) vs Mandela Barnes (D)
Ohio - J. D. Vance (R) vs Tim Ryan (D)
Arizona - Blake Masters (R) vs Mark Kelly (D)
Governor races
Texas - Greg Abbott (R) vs Beto O'Rourke (D)
Pennsylvania - Doug Mastriano (R) vs Josh Shapiro (D)
These were selected as races that had a high amount of interest across the prediction platforms. The main reason for using a limited set of questions is that not all prediction platforms made forecasts on all races - the main limiting factor was which questions were on Metaculus. (I did later find a couple more races on Metaculus, but did not add them to my list because I had already preregistered the question set.) Using a smaller set of questions also makes the data collection easier for me.
They are not all highly competitive races - which is a good thing for looking at how accurate and well-calibrated predictions are across a range of high or low competitiveness races.
Fine print on methodology
In the event that the winner of an election is not one of the current major-party candidates, I will exclude that race from the calculation. This is to normalize slightly different questions between platforms - some ask which candidate will win, others ask which party will win.
For 538, I use the forecasts on this page https://projects.fivethirtyeight.com/2022-election-forecast/, i.e. the Deluxe model. I also score the Classic and Lite models for comparison
For PredictIt, I compute the inferred Republican win probability as the average of Republican YES price and 1 - Democratic YES price. I do not use the NO prices (this is because the YES prices are what the platform highlights most prominently)
For Metaculus, I will use the Metaculus Prediction. I will also score the Metaculus Community Prediction for comparison.
For Manifold, there are often multiple questions on the same race, sometimes with slight differences in resolution criteria. I used only the prediction on the market featured on the main midterms map page https://manifold.markets/midterms.
Manifold has a separate instance for the Salem Center/CSPI Tournament which I will also compare. The market mechanics are the same but it uses a separate play-money currency and has a similar but different user base.
This tournament does not have a question on the Texas governor race. I will substitute the main Manifold's prediction there. (For the purposes of main Manifold to Salem Manifold comparison, this is equivalent to excluding this question.)
See prediction questions on which platforms will be most accurate here: https://manifold.markets/group/election-forecast-comparison
Hi @jack - I love the analysis that you did benchmarking different platforms. It is something we're interested in doing at Metaculus (where I work). I was wondering if you have a document with the calculations that you'd be willing to share?
And, I wanted to endorse your point that "the election results are highly correlated, so the platform that turns out to be most accurate may not have actually been the best set of predictions." I currently don't know if Metaculus was best or worst - but I don't think that the results will be significant for exactly the reason you identify.
We are interested in doing benchmarking to advance forecasting knowledge, and would welcome exploring if we might work together on something like this! Please feel free to email me at tom at metaculus dot com, if you're interested. Thank you!
Thanks, glad people are interested! Here's my spreadsheet where I'm tabulating this: https://docs.google.com/spreadsheets/d/1P95dImsdgKiqSqBdxL3eendS7fcZCYHPZgUntRDnxUU/edit#gid=0. I still need to double-check my work, if anyone spots mistakes let me know.
There are some things I'm interested in experimenting with, like what if I try to adjust the odds of each prediction platform to remove the different overall left-right biases, and then compare those?
Hey @jack - I tweeted out your analysis and didn't think anything of it (I usually get like 2 likes on my tweets) but it's weirdly getting some movement. https://twitter.com/galestorm94/status/1590364168930340866?s=20&t=yNkC81UvOY-5EKdldHg68w
I linked your bio in a follow-up tweet for credit, but just LMK if you'd like me to delete the thread.
See prediction markets on which platforms will be most accurate here: https://manifold.markets/group/election-forecast-comparison