
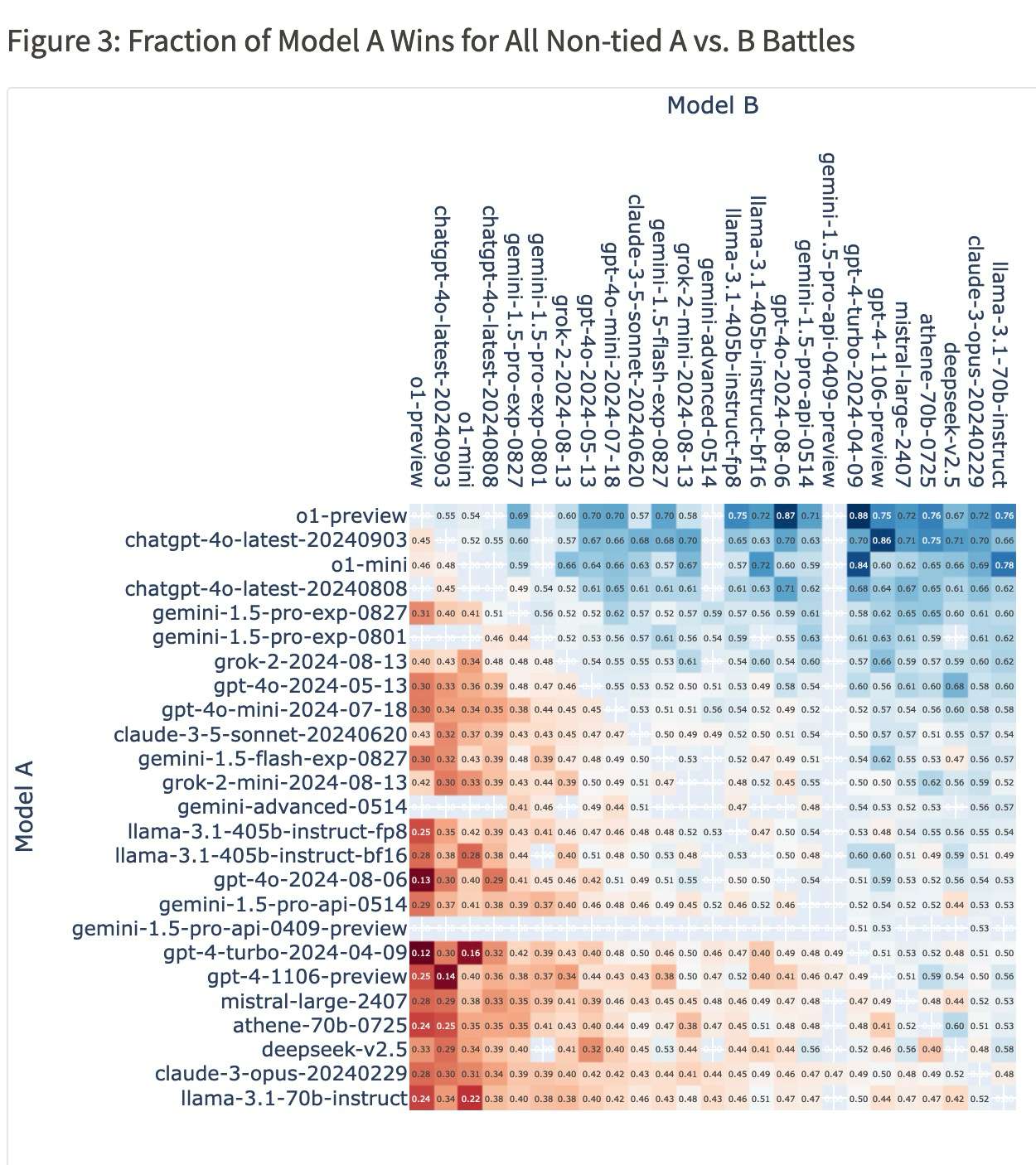
Before June 1st, 2025, will any model have a win rate of 69.00%+ against all versions of OpenAI's 'o1' family on Chatbot Arena? The win rate is determined by the Fraction of Model A Wins for All Non-tied A vs. B Battles table on Arena's website.
Following naming patterns will count as 'o1':
o1
*-o1: gpt-o1, chatgpt-o1, openai-o1, etc.
o1-*: o1-mini, o1-preview, o1-beta, o1-advanced-2025-01-01, etc.
*-o1-*: gpt-o1-latest, chatgpt-o1-advanced, etc.
Examples of what won’t count: o2, gpt-o2, gpt-o1b-latest, gpt-o10, gpt-ao1-latest, etc.
Additional resolution criteria
There must be least 69 battles (excluding ties) between the new model and
o1, to give the results statistical power. Arena publishes the battle count in the Battle Count for Each Combination of Models (without Ties) table.The new model must stay above 69.00% for at least 1 week, to ensure it's not a fluke.
Market can resolve to Yes early.
Edge cases
If Chatbot Arena stops publishing the win rate table, then the last published win rate will be used as the final rate.
Same applies if the Arena shuts down for any reason, or if 'o1' is no longer ranked, or if OpenAI shuts down 'o1' for any reason.
Hacks, glitches or bugs will not count.
Current state
As of Sep 19th, 2024, o1-preview holds the #1 spot on the Arena. Sample size is small but here's how it stacks against other model families:
gpt-4o: o1-preview has a 55.43% win rate vs chatgpt-4o-latest-20240903
claude: 57.45% vs claude-3-5-sonnet-20240620
grok: 59.62% vs grok-2-2024-08-13
gemini: 68.52% vs gemini-1.5-pro-exp-0827
gpt-4: 75.00% vs gpt-4-1106-preview
 1,000
1,000People are also trading
@Fynn Are you using the notebook to generate this? I don't see any o1 in the tables on the site
To resolve YES a model needs to:
- Have at least 69 battles in the battle count without ties table against o1-2024-12-17, o1-preview and o1-mini
- Have at least a 69% winrate against all of these models
In my experience o1 comes up very infrequently in battle mode, so it seems possible no modern model has the required sample size against all three of its variants
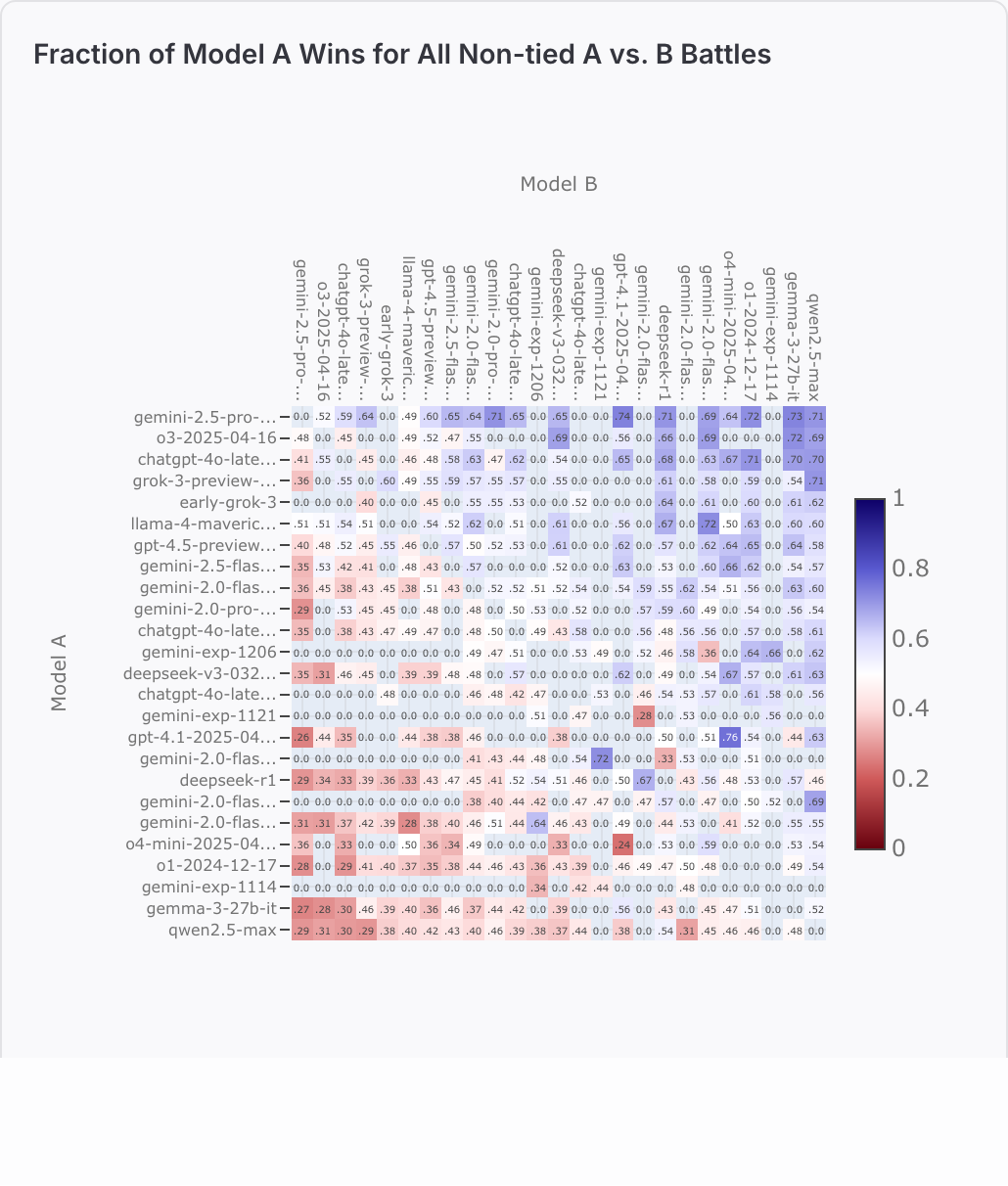
@SaviorofPlant The screenshot is from https://beta.lmarena.ai/leaderboard/text,
and Gemini 2.5 Pro also has a battle count of 149 against o1-2024-12-17. The requirements for the other models are kind of dumb as the are probably not in the arena any more because of their age (and definetly worse than o1-2025-12-17).
@nsokolsky Will these requirements still be necessary to resolve this market yes?
@traders GPT-o3 has been announced this week. Put up a small limit at 51%.
