
"comparable capability" refers to the text performance only, to keep it simple (the hardest part of making GPT-4 is the language model anyway). To be comparable the performance should be equal or extremely close across a wide range of benchmarks (e.g. MMLU, HumanEval, WinoGrande) and tests (e.g. SAT). It should also have at least 8k context length (chosen since GPT-4 has 8k and 32k context length versions).
Of course, to qualify as YES, the group that develops a competitor must publicly announce that they trained an LLM with the benchmark results.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ617 | |
| 2 | Ṁ286 | |
| 3 | Ṁ187 | |
| 4 | Ṁ110 | |
| 5 | Ṁ102 |
Really hard to justify resolving YES based on PaLM 2, so it had to be NO. The lessons I learned from judging this market were incorporated into my new market - please go bet there! https://manifold.markets/hyperion/will-google-gemini-perform-better-t
Some analysis of PaLM 2 vs GPT-4. This is hard to benchmark because PaLM 2 Large is not public and we can only rely on the technical report.
At first glance, PaLM 2's results in the technical report appear ~5% below GPT-4 across most standard benchmarks (e.g. MMLU, Hellaswag, Winogrande, etc). However, Table 5 on PaLM 2 technical report shows results from using CoT which are better than or equal to GPT-4 on Winogrande and DROP. Sourcing other benchmarks around the internet of GPT-4 on StrategyQA and CSQA show that PaLM 2's published results are slightly better. GPT-4 is notably better at coding, however, judging by the Humaneval results.
The main reason to resolve NO here, however, is that PaLM 2 (as described in the report) is not a chatbot: it is a base model instruction-finetuned on FLAN, not a full RLHF finetune on millions of human preferences.
If we were considering base models only, I think that PaLM 2 has comparable capability. However, considering full chat capabilities that people care about, I expect PaLM 2 to be slightly worse to use. Therefore I will not consider PaLM 2 sufficient to meet the bar for this question, unless there are well-argued objections.
@Felle How can the resolution be improved? It seems pretty clear to me, since I explicitly name benchmarks.
@hyperion I didn't like the criterium for the model to be 'developed' by October '23 instead of it just being released then I think. Sorry for the late response 🙏🏼
I'm buying more NO because there's only a month left now, but:
"The Code Llama models provide stable generations with up to 100,000 tokens of context. All models are trained on sequences of 16,000 tokens and show improvements on inputs with up to 100,000 tokens."
"[...] based on Code Llama [...] WizardCoder-34B surpasses (initial) GPT-4, ChatGPT-3.5 and Claude-2 on HumanEval with 73.2% pass"
So it meets context size and at least one benchmark, though it's limited to code only.
@Mira What do you think about the PaLM 2 published results which are competitive? I'm unsure
@hyperion Google Bard is using that, right? I'm surprised they claim it matches GPT-4: I tested it months ago, was very disappointed, and haven't really thought about it since. As the market requires, they did announce it and they did find some benchmarks, so I would understand if it's technically a YES.
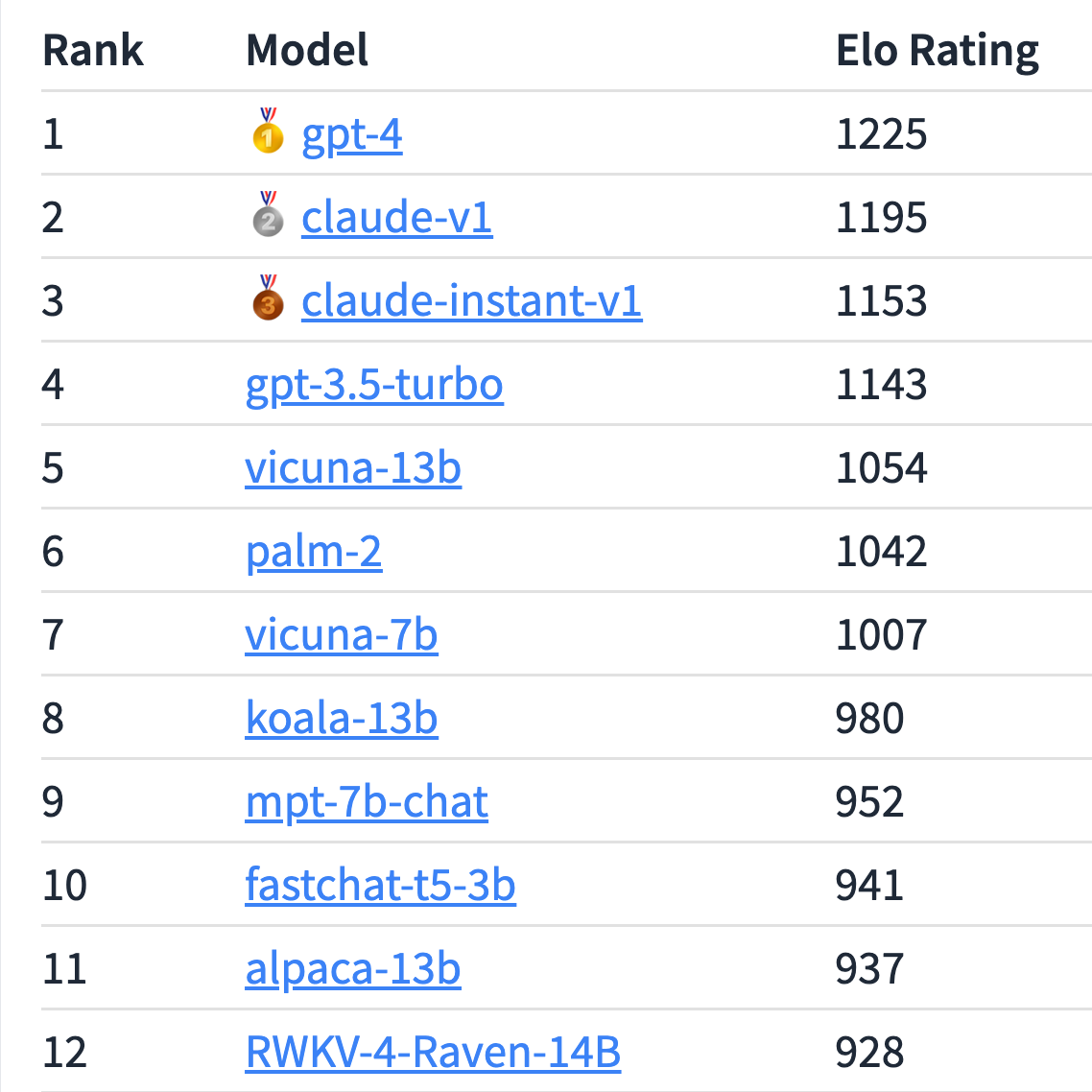
One example of a benchmark where it's worse: it's 200 ELO points below GPT-4 on this leaderboard, and 100 points below GPT-3.5-turbo: https://lmsys.org/blog/2023-05-25-leaderboard/
Everyone finetuning language models uses GPT-4 as the gold standard to rate responses and generate synthetic data. I haven't heard of anyone using PaLM 2 for this. This would be similar to a "citation count" metric.
HumanEval is also mentioned in the market description and is 37.6 vs. GPT-4's 67 at release.
IMO Anthropic's Claude is the only LLM that comes close to GPT-4. The next version of Claude might be competitive.
@Mira I don't believe the PaLM 2 API or Bard is the most capable version in the paper. The benchmarks in the actual paper are fairly convincing
New: In a rare collaboration between DeepMind and Google Brain, software engineers at both Alphabet AI units are working together on a GPT-4 rival that would have up to 1 trillion parameters—a project known internally as Gemini.