In his “Situational Awareness” essays, Leopold Aschenbrenner posits we will “muddle through” the problem of aligning superhuman AI. I take this to mean we will have techniques which we are reasonably sure work, but without formal guarantees. Further, I expect that muddling through will involve new insights into AI control, but I expect the techniques will be unsatisfying from an agent foundations perspective.
If we get super intelligent AI, we will muddle through?
I’ll consider an AI super intelligent if one or more frontier labs claims it’s it so, and this is corroborated by one or more safety/eval lab.
Resolves yes if the AI is reasobably aligned one year after announcement without a no trigger:
Resolves no if there is a critical alignment failure discovered within the year period, either real or potential.
Resolves no if we the alignment method involves satisfying guarantees or arguments on the safety of the AI.
I’m not sure how best to pose the question or when to set the resolution date. Feedback solicited.
Update 2025-07-19 (PST) (AI summary of creator comment): If there is no superintelligent AI by the resolution date, this market will resolve to N/A.
 1,000
1,000People are also trading
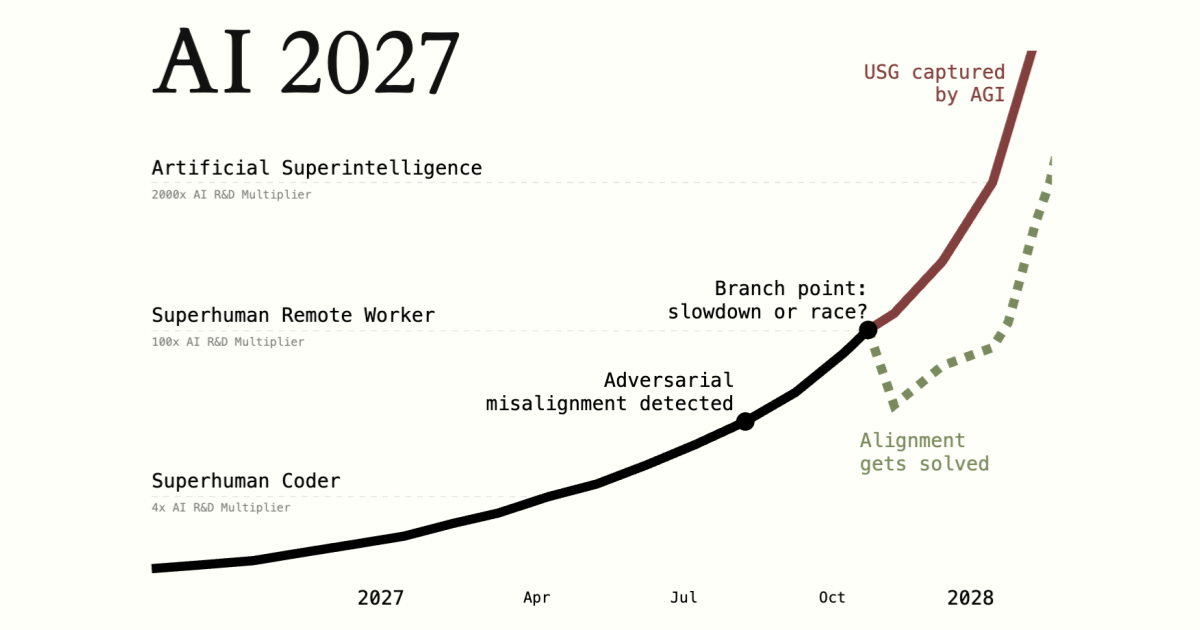
It seems like https://ai-2027.com/ basically predicts we will muddle through. Anyone disagree?