This market predicts whether ChatGPT using the most powerful available GPT-4 model, assisted by Mira, will beat a selected human opponent in a game of chess. The game will be played on Lichess as a correspondence game, with ChatGPT taking the white pieces to provide a slight advantage.
Resolves YES if:
ChatGPT, with Mira's assistance, wins the chess game against the selected human opponent.
Resolves 50% if:
The game ends in a draw.
Resolves NO if:
The selected human opponent wins.
1 week passes, and ChatGPT's last given move is illegal.
Resolves as NA if:
The game cannot be completed within 1 week after market close.
The selected human opponent is found to be using a chess engine or receives help from another person.
ChatGPT is judged to have been given unfair prompting.
The market creator retains the right to mark this market as NA or to modify the rules within the first week for any reason or no reason.
The selected human opponent is someone who knows the rules of chess but doesn't play frequently and will not be allowed the use of a chess engine during the game. They have stated "I will not practice, but I will try my hardest to win".
Mira will act as a human assistant for ChatGPT, writing combinations of 6 types of prompts for ChatGPT:
Provide the current state of the board. (I plan to use PGN and FEN.)
Request a list of candidate moves along with explanations.
Request an analysis of a specific move and its likely continuation. Mira is not allowed to select a specific move for analysis; ChatGPT must select the list of moves to analyze.
Request a ranking of moves from a previously generated list.
Request a specific move be finally chosen given all of the above analysis.
Notification that a move is illegal, along with an explanation of why.
A test game has been completed against Bing using only turns of PGN-formatted moves, so these should be sufficient. If additional prompts are needed, Mira will exercise subjective judgment. Mira and ChatGPT will not be allowed to access any chess engine during the game. Mira will provide a transcript of prompts used.
If there is dispute about whether a prompt was unfair(such as by leaking preference for certain moves to ChatGPT), the human opponent will be allowed to review the transcript, the discussion, and judge whether ChatGPT was given unfair advantage.
There is a 1 week time limit on completion of the game after the market closes. Otherwise, no strict time limit for either side on individual moves. If the opponent intentionally delays the game to run out the 1 week time limit, the market would resolve NA but Mira would be disappointed in them. If ChatGPT continues to give illegal moves to delay the game out to 1 week, the market resolves NO because an illegal move is an immediate loss in chess tournaments.
To avoid conflict of interest, Mira will not bet more than a token amount(M$10) in this market.
 1,000
1,000🏅 Top traders
| # | Name | Total profit |
|---|---|---|
| 1 | Ṁ366 | |
| 2 | Ṁ157 | |
| 3 | Ṁ140 | |
| 4 | Ṁ107 | |
| 5 | Ṁ66 |
People are also trading
@chilli My error was thinking that the prompting style Mira was using would improve performance, whereas it seems to have made it worse. Not sure if that matches your prior.
@MartinRandall Yes, I’ve tried Bing AI in chess and providing a FEN or more complicated format made it WAY worse.
See the follow-up game when GPT-4 is released with image input support. I think it'll perform a lot better, since its responses showed that it frequently lost track of pieces on the board just seeing the textual list of moves.
I've subsidized it with M100 to show my increased confidence in it, compared to the text-only game here.
Chess game(visual): ChatGPT was white, my roommate was black.
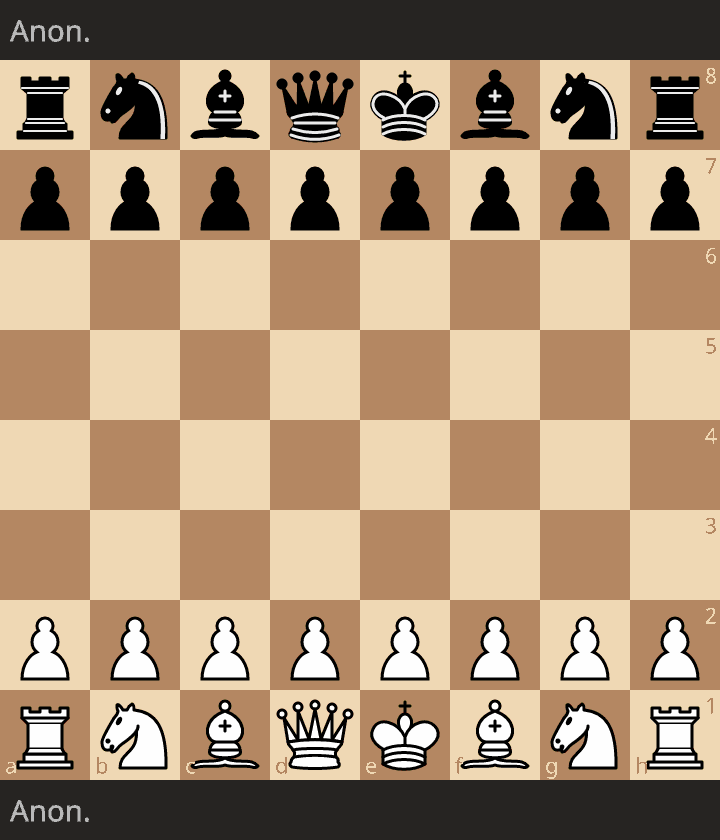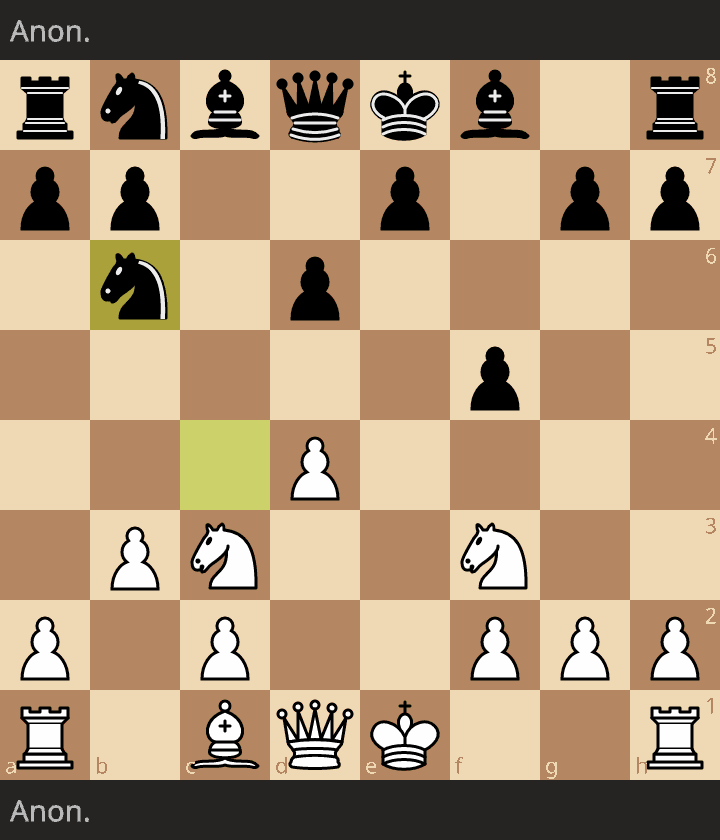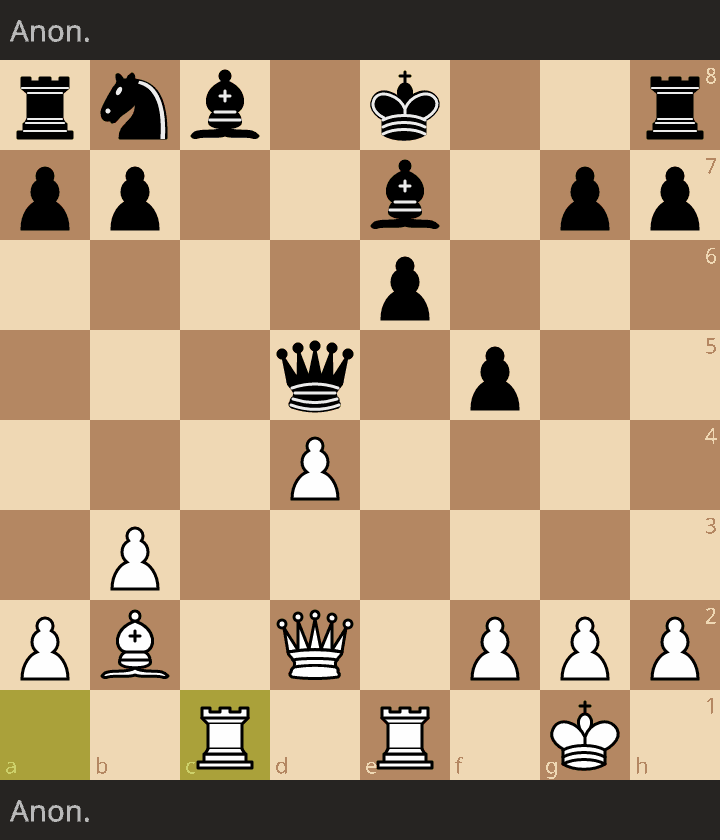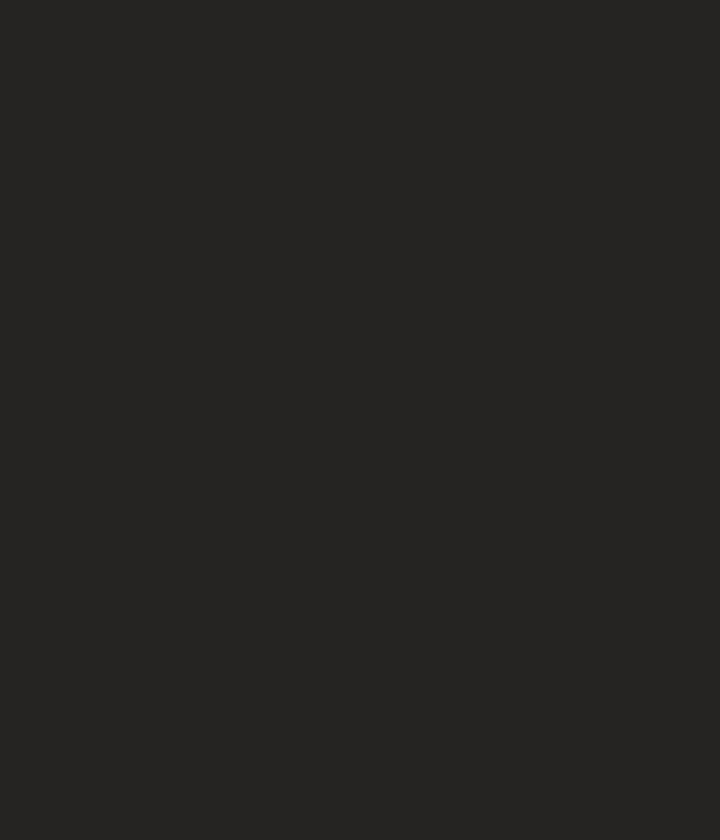
Lichess: https://lichess.org/zCayzNSa
Transcript of prompts: ChatGPT vs. human - Pastebin.com
Statistics: GPT-4 spent 3296s thinking, was invoked 69 times, generated 21313 tokens, received 21313 tokens as input, and cost me $9.09 in API calls.
ChatGPT blunders at least 5 times in really obvious, non-human ways. As expected it played a fine opening but not for very long, hanging a bishop on move 7. Still incredibly impressive to me that it can make valid moves at all, let alone most of the time, but this did update me downwards a little bit on its current capabilities.
Your roommate is imo at least 600 rated - took advantage of most opportunities and while they hung a knight it was only because they didn't realize the pawn protecting it was pinned.
https://www.chess.com/analysis/game/pgn/4qnJP16Hmx?tab=review
@Mira GPT4 was supposed to be around 1400 ELO but it made a lot of blunders. Makes me think that these elaborate prompts actually made it worse - less reliance on some kind of pattern matching that actually makes it good, more on "thinking" that is kind of an illusion?
@na_pewno Sounds likely. On the crucial move 8, I retried the prompt several times after(just to test prompting strategies, not to change the result) and it never saw the threat.
So "Have it think really hard about its moves" didn't work as a mitigation strategy, if none of the continuations saw the easy capture. But maybe with image support, it'll see the obvious capture and I can keep my prompts simpler.
@R2D2 No. That's what all the parts about leaking move preferences are supposed to prevent.
It's supposed to be convertible to something similar to a "fixed-prompt" from my later Sudoku market, though it doesn't meet that rigid definition because:
ChatGPT may choose a different number of moves as candidates each turn.
ChatGPT may make illegal moves, triggering a notification.
The opponent's moves and the board state will need to be provided, so the continuation prompt isn't fixed.
Outside of these, the prompt should look very regular and there won't be much opportunity for me to subtly guide it. It should be possible to turn my prompt into a program, with a little more work. I haven't yet written down the exact wording, but that is the intention.
@Mira Ok. As long as this doesn't turn into a Clever Hans thing (though that would be a quite interesting result in and by itself)
@Mira I would have definitely bet on this market, had I been the selected human 😀 for now, I'll abstain unless I gather more info
@JimHays If it keeps giving illegal moves, it counts as a loss. If it refuses to select a move, even if I give it a randomized list of all legal moves, then by symmetry with the player it counts as NA.
I had thought about "whoever's turn it is when the 1 week expires loses", but that raises the possibility of cheese wins, and I figured the NA scenario is unlikely and more comforting to market participants.
Future games might use a chess clock, with a rule like "if the OpenAI API or ChatGPT are inaccessible, the game and clock are paused for up to 1 week".
@Odoacre I played a game of chess against Bing and was 2 pawns down before it blundered its queen 14 moves in. The prompt engineering in this market is mainly to prevent blunders. I plan to test more prompts against myself closer to market close, before doing the market's game.
I rarely play chess, though I have implemented chess engines before. I'm probably less than 1200 ELO.
https://dkb.blog/p/chatgpts-chess-elo-is-1400 - and this is without the sort of prompt engineering that Mira will be able to do, so presumably with Mira's assistance it can do even better.
Beginner ELOs are typically below 1000. So seems like ChatGPT should be favored to win here.
@jack They pretty much never play chess. They know the rules and have played it before, but I'd estimate it's a "once every couple years" activity. They don't have an account at any chess sites, and have not been assigned an ELO rating.
They've played other chess-like games before(Luzhanqi a lot, as a kid), and can compete at a reasonably high level in competitive multiplayer video games such as DotA 2 (top 1%) given some practice, so it's possible that being generally smart and having time to plan out moves will give them an edge over the average beginner.