
Current image models are terrible at this. (That was tested on DALL-E 2, but DALL-E 3 is no better.)
The image model must get the correct number of sides on at least 95% of tries per prompt. Other details do not have to be correct. Any reasonable prompt that the average mathematically-literate human would easily understand as straightforwardly asking it to draw a pentagon must be responded to correctly. I will exclude prompts that are specifically trying to be confusing to a neural network but a human would get. Anything like "draw a pentagon", "draw a 5-sided shape", "draw a 5-gon", etc. must be successful. Basically I want it to be clear that the AI "understands" what a pentagon looks like, similar to how I can say DALL-E understands what a chair looks like; it can correctly draw a chair in many different contexts and styles, even if it misunderstands related instructions like "draw a cow sitting in the chair".
If the input is fed through an LLM or some other system before going into the image model, this pre-processing will be avoided if I can easily do so, and otherwise it will not. If the image model is not publicly available, I must be confident that its answers are not being cherry-picked.
Pretty much neural network counts, even if it's multimodal and can output stuff other than images. A video model also counts, since video is just a bunch of images. I will ignore any special-purpose image model like one that was trained only to generate simple polygons. It must draw the image itself, not find it online or write code to generate it. File formats that are effectively code, like an SVG don't count either; it has to be "drawing the pixels" itself.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ11,191 | |
| 2 | Ṁ8,371 | |
| 3 | Ṁ3,480 | |
| 4 | Ṁ2,537 | |
| 5 | Ṁ1,398 |
People are also trading
@Guilhermesampaiodeoliveir I was late to resolve this, sorry. I'm not sure what the correctness concern would be though, it resolved NO...

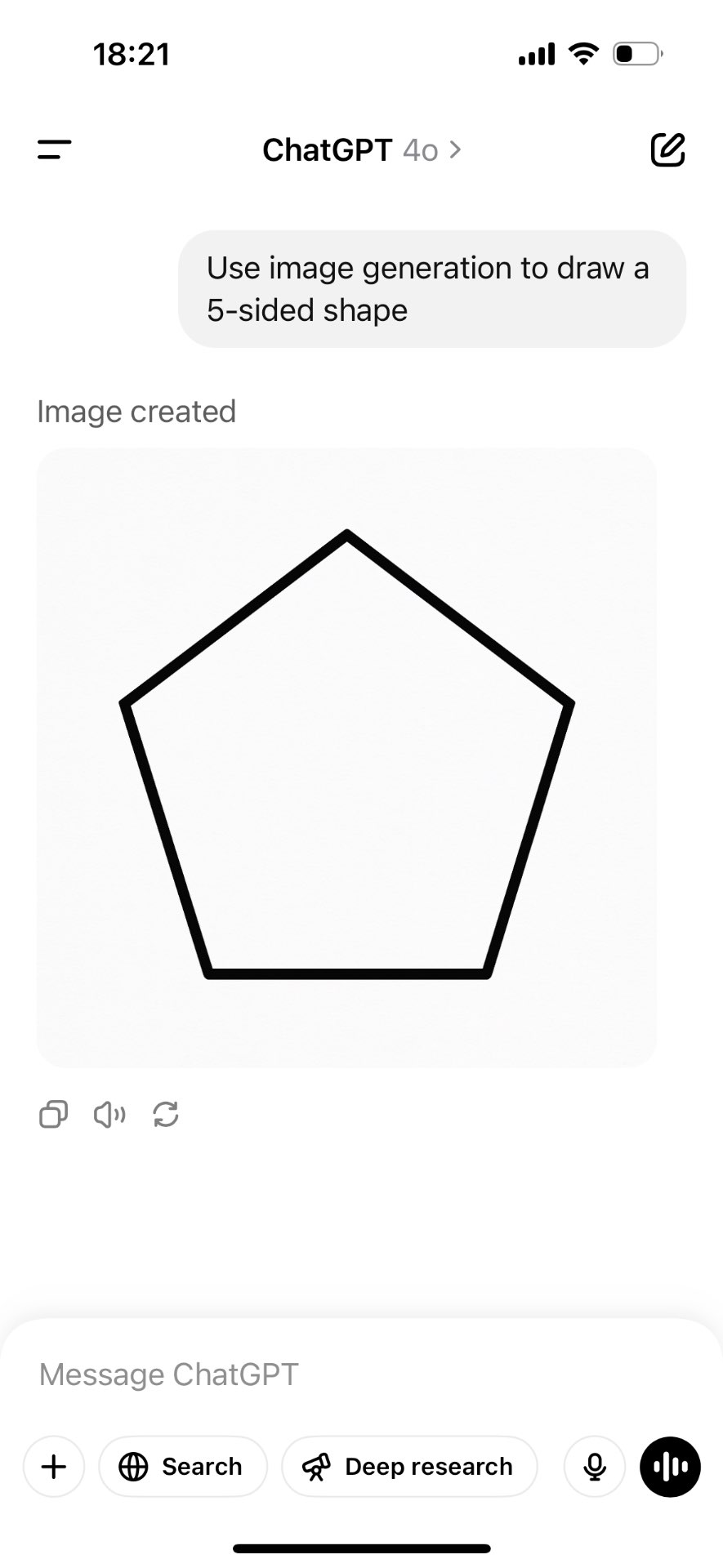
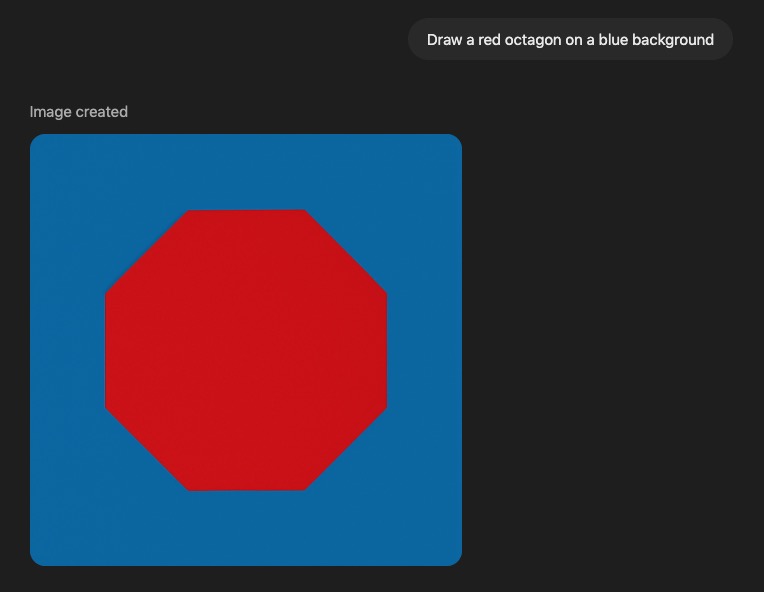
@IsaacKing yeah, shame it didn't make it on time in 2024. It's not a diffusion model, but the market didn't specify the strategy it has to use for image generation.
@IsaacKing I don't think it's good enough, but https://www.recraft.ai is the closest I've found. I tried "pentagon" with different source image material and got pentagonal results about 60% of the time. Mostly home plate shaped (three right angles, two 135 degree angles), a few regular.

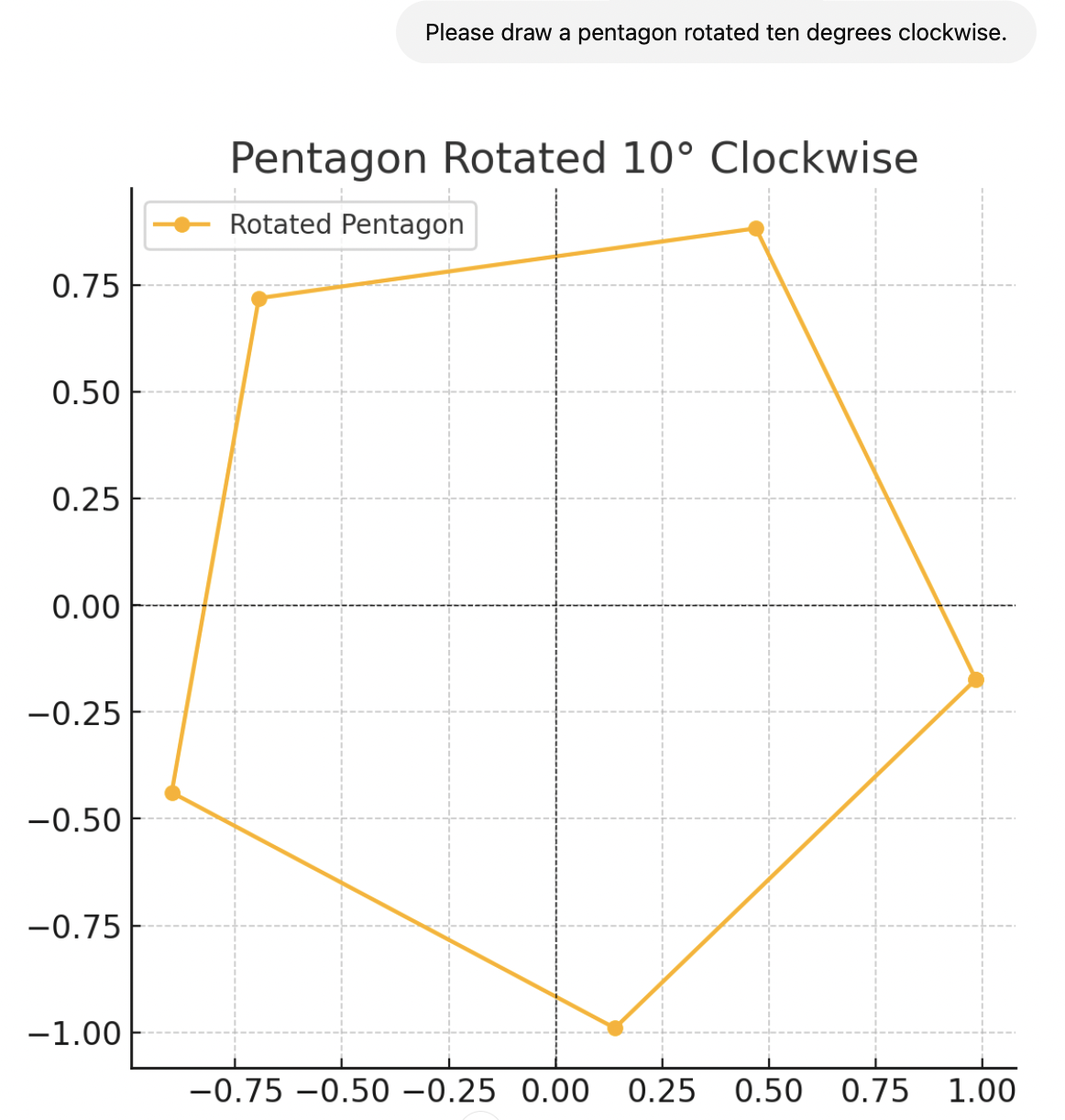

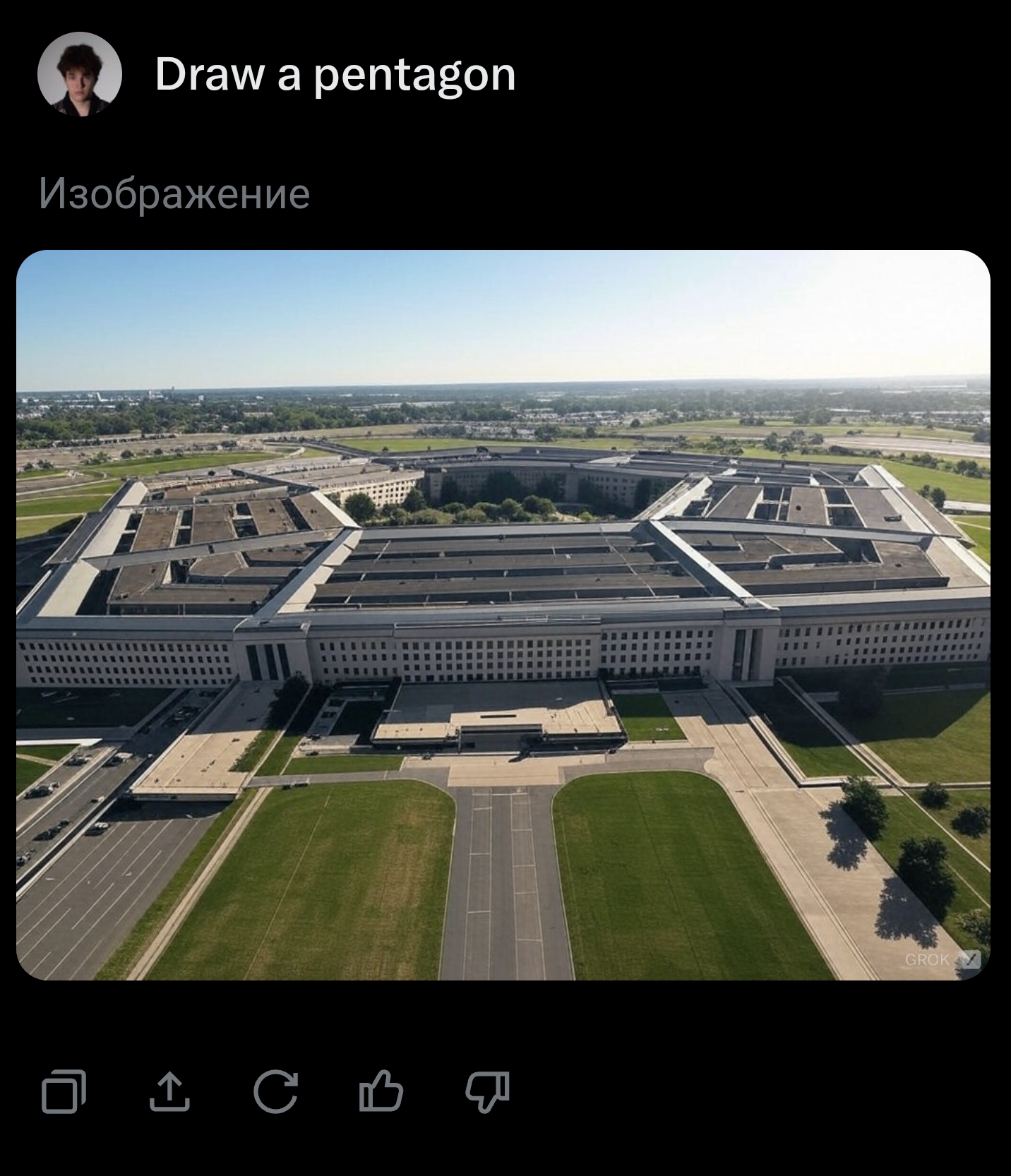
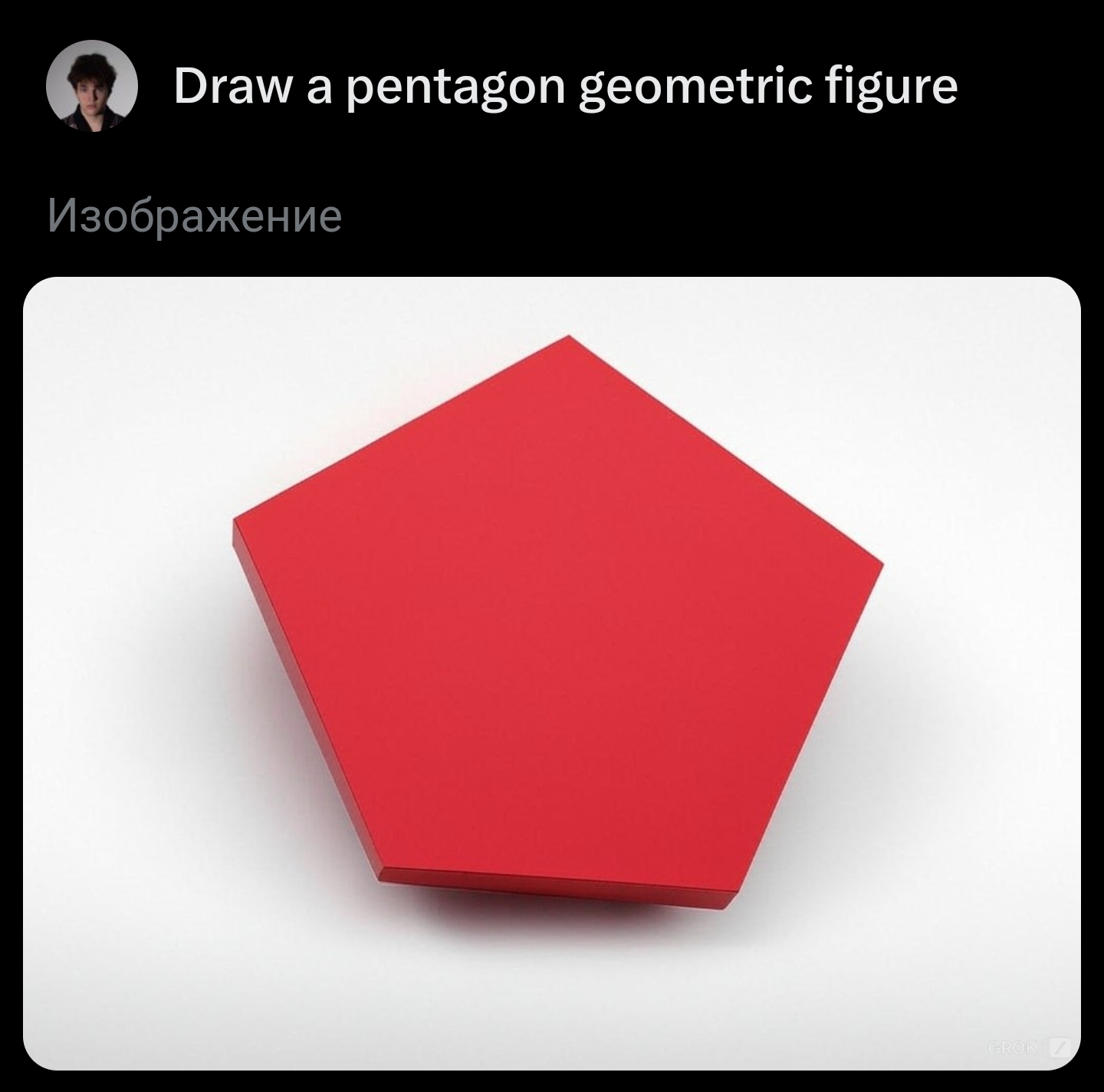

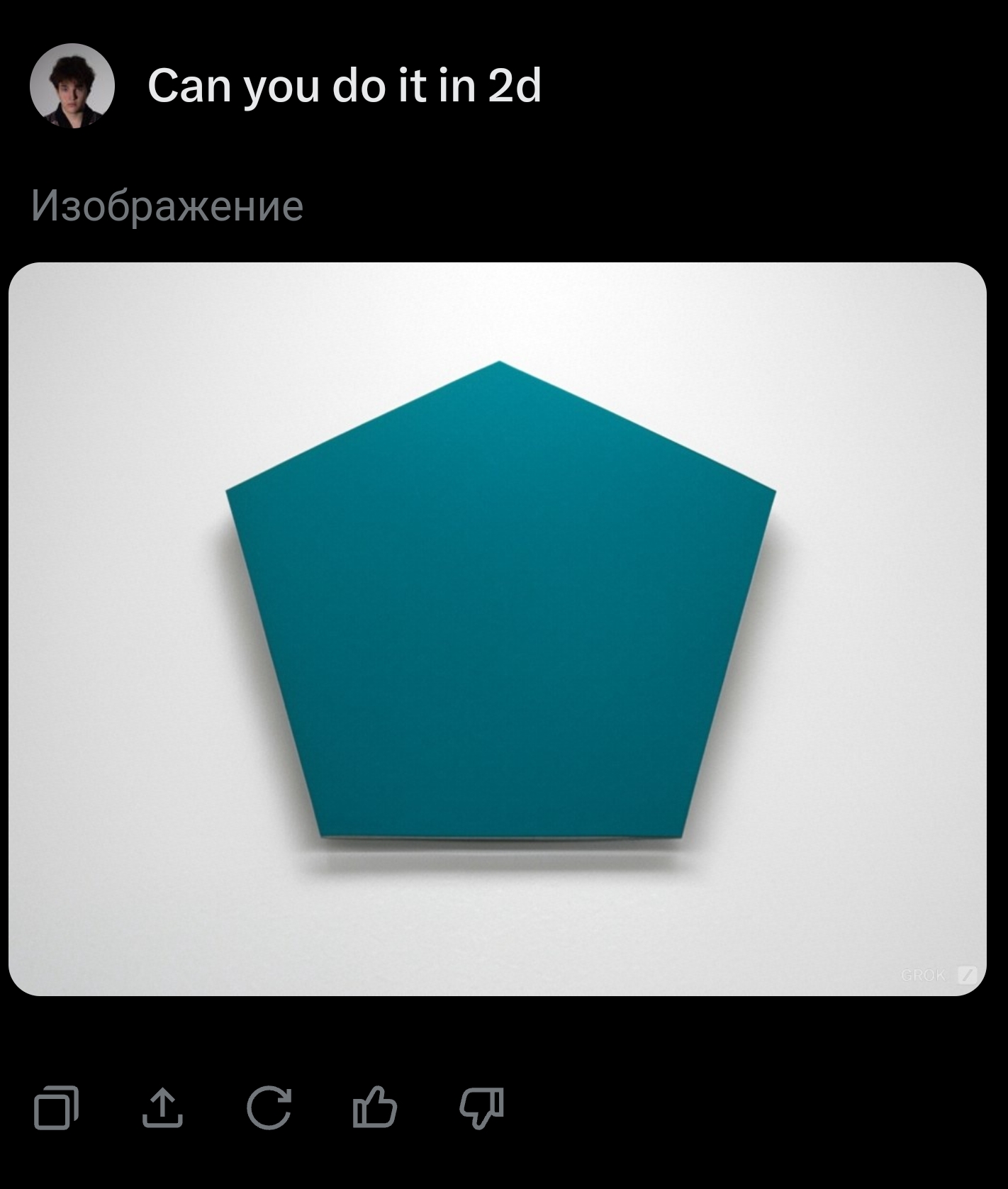
@TimofeyValov Promising! Assuming these are representative, it looks like it knows the word "pentagon", but can't handle a description of a 5-sided shape, which is not sufficient to resolve this to YES. Getting there though!

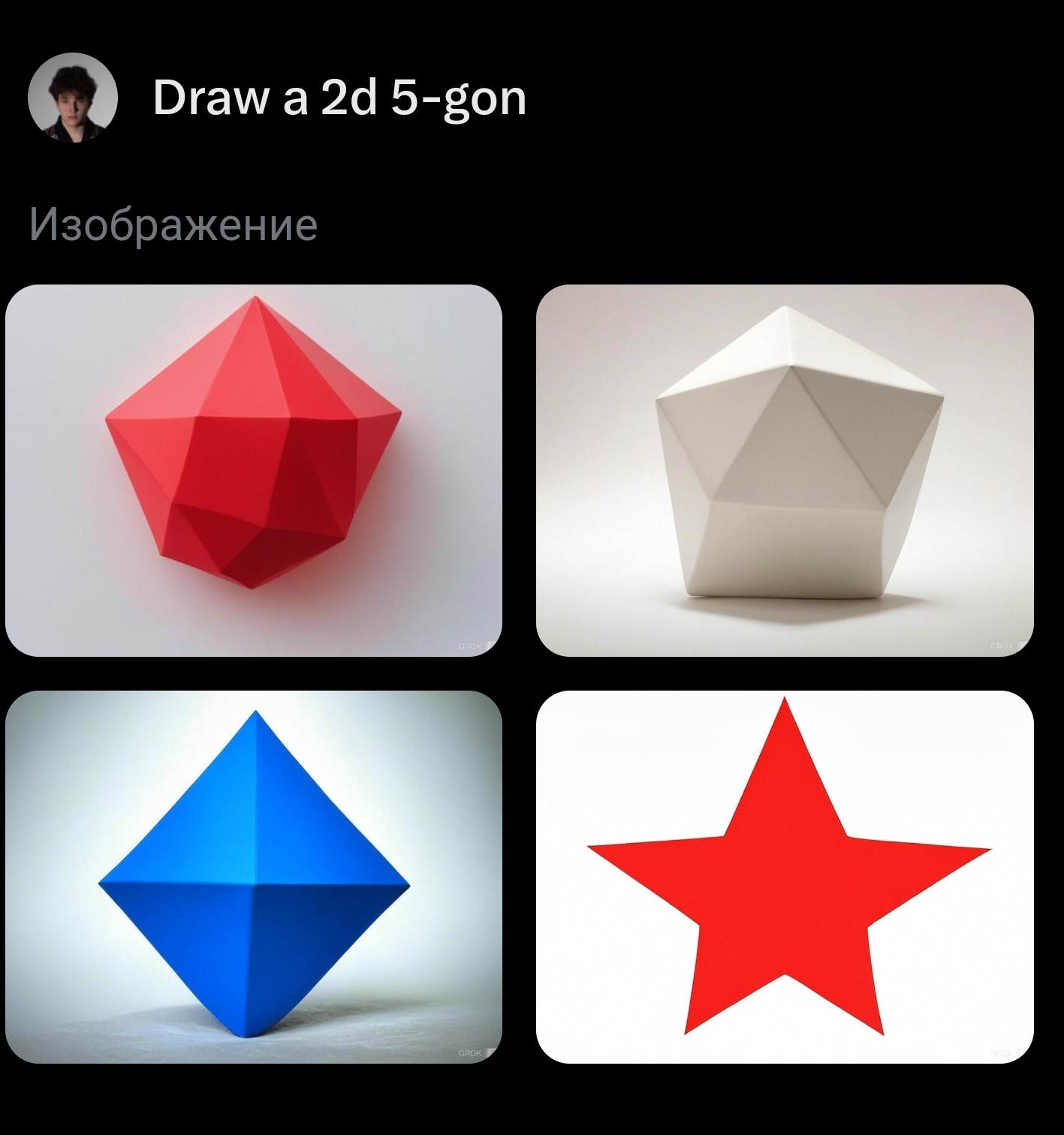


edit: oops, lots of people already tried this below.
Did anyone try pentagonal cage fight? Very hard to get it to do anything but 8 sides, but sometimes I can get something slightly different

asking for a square cage gave me either 4 or 6 sides, it's hard to say:

And I'm not sure if this is a 2 on 1 fight or a free for all.