All events must take place between the first day of the first event (even if before the opening ceremony) and the end of the last event, or the closing ceremony, whichever is later.
I reserve the right to edit or N/A anything
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ1,914 | |
| 2 | Ṁ1,485 | |
| 3 | Ṁ1,025 | |
| 4 | Ṁ709 | |
| 5 | Ṁ598 |
People are also trading
U.S. wins the most GOLD medals and Cheating scandal by any athlete (think: 2012 badminton)
resolves n/a for being ambiguous and underdefined. Such is the nature of prop bets.
I'll give the first person to prove "All gold medal winners combined have more letters from first half of alfabet than second half"
U.S. wins the most GOLD medals and Cheating scandal by any athlete (think: 2012 badminton)
resolves n/a for being ambiguous and underdefined. Such is the nature of prop bets.
I'll give the first person to prove "All gold medal winners combined have more letters from first half of alfabet than second half"
All gold medal winners combined have more letters from first half of alfabet than second half
what does it even mean? @CryptoNeoLiberalist ?
Not sure what you intended to promise in return for this, but I got ChatGPT to run a script on the full list of medalists, extracting the gold medalists' names and counting the letters. Here's the full name list if anyone wants to play around with it.
The upshot:
Total letters from A-M: 2,086 (the clear winner)
Total letters from N-Z: 1,489
Individual letter counts:
A: 434
B: 55
C: 102
D: 90
E: 335
F: 44
G: 94
H: 139
I: 330
J: 46
K: 109
L: 192
M: 116
N: 312
O: 243
P: 30
Q: 11
R: 215
S: 169
T: 150
U: 114
V: 74
W: 38
X: 10
Y: 93
Z: 30
No, good point, not unless they were named on that list. Basketball only lists the winning team for example, not all the team members, so they aren't included.
It does seem like the Olympics website lists them individually as medalists, which would suggest they should probably be included, but unfortunately it uses some ungodly load-and-unload-on-the-fly setup that prevents easy extraction of the full list.
However! Wikipedia also lists them individually, and doesn't do any messing around with loading parts of the page on the fly. It did take a fair bit of extra wrangling to parse since it's not plain text, but here are the headline results:
Total letters from A-M: 3,401
Total letters from N-Z: 2,424
Full name list here.
my own results using some basic python and @MugaSofer's list:
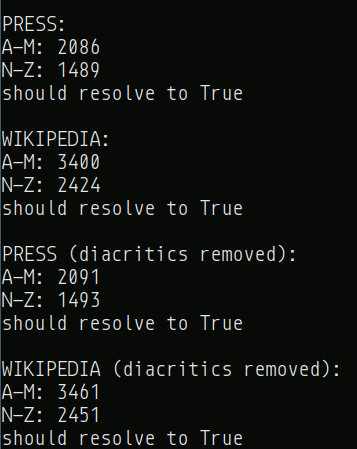
(the spreadsheet contains 2 lists, "Associated Press" and "Wikipedia", and the "removed diacritics" lists count letters such as "Ć" the same as "C" as per the unidecode library)
seems like Muga's results were quite accurate
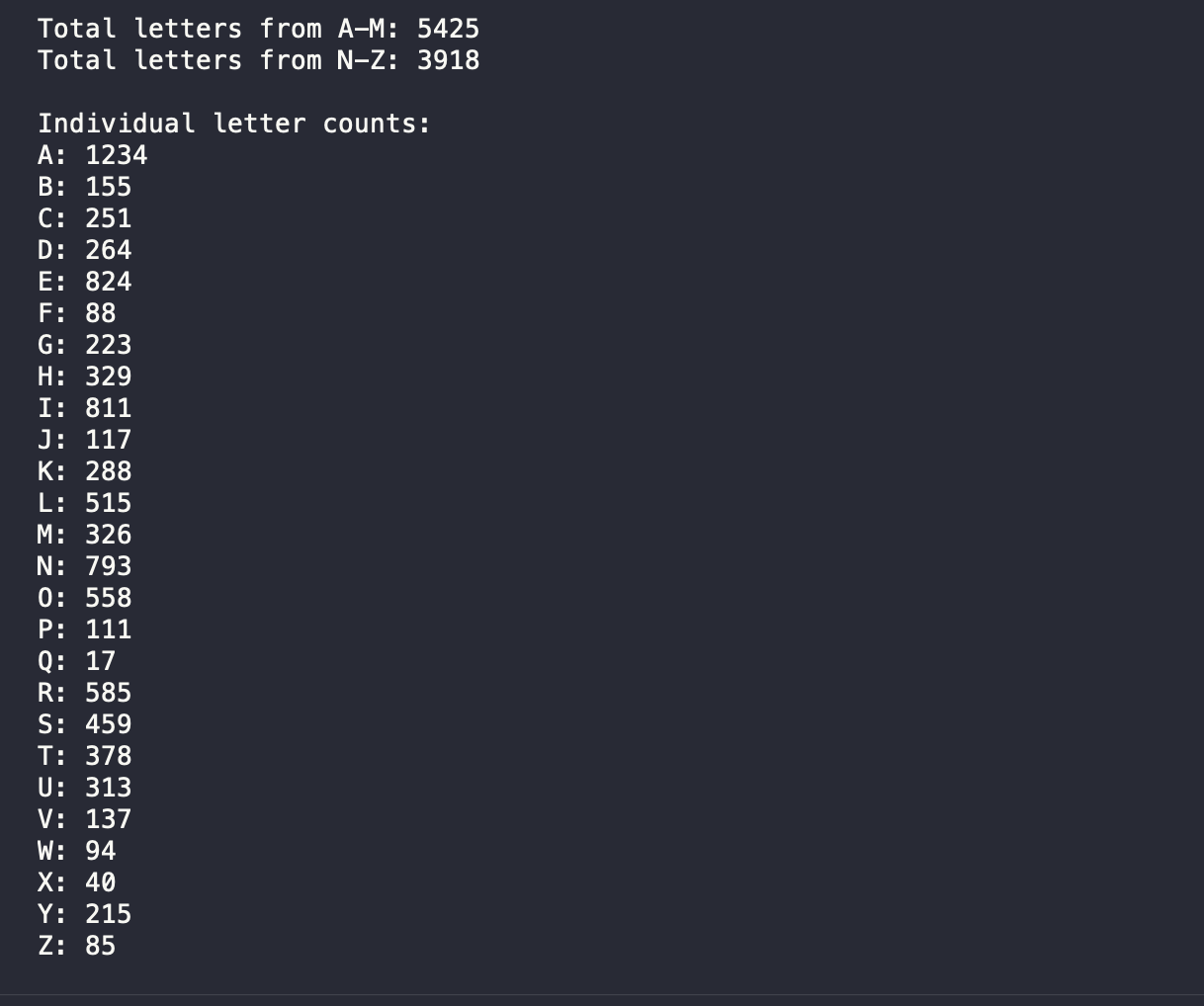
did a similar experiment for 2020 and seems like this question should always resolve YES for any sufficiently large list of names. also why is 2020 dramatically higher? i had 744 gold medallists which seemed way off but makes some sense given wikipedia says 2,402 medals were won by 2,175 athletes in 339 events
@MugaSofer seems like your script missed a pretty sizable bunch of names after all: e.g Abdumalik Khalokov, Adriana Ruano etc
Huh, you're right, it definitely seems like some stuff was missed. Good catch. Spot-checking, I think whole tables were skipped over.
I have absolutely no idea why. The tables that parsed correctly seem to have the same format as the ones that didn't; in fact they all seem to be using a shared wiki template. This is the relevant code, for reference:
from bs4 import BeautifulSoup
# Load the HTML content from the provided file
with open('/mnt/data/List of 2024 Summer Olympics medal winners - Wikipedia.html', 'r', encoding='utf-8') as file: content = file.read()
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(content, 'html.parser')
# Re-parse the HTML content and target the tables with class "wikitable plainrowheaders"
tables = soup.find_all('table', {'class': 'wikitable plainrowheaders'})
gold_medalists = []
for table in tables:
rows = table.find_all('tr', {'valign': 'top'})
for row in rows:
cells = row.find_all('td')
if cells:
# Extract gold medalists from the second cell, which corresponds to the gold medal column
gold_cell = cells[1]
# Extract all names within the gold medal cell
names = gold_cell.find_all('a')
gold_medalists.extend([name.get_text(strip=True) for name in names])
# Remove duplicates and sort the list
gold_medalists = sorted(set(gold_medalists))
Of course, the bug could be hiding in some other part of the code, but I can't paste the whole thing here.
Maybe you'll have better luck with whatever setup you used to get the 2020 data? I'm pretty confident the answer here is in fact YES given the sample size, but...
@dlin007 alphabets tend to be arranged such that more common-ish (and easier) characters are arranged towards the front. take it with a lot of hand-waviness, but it's useful that kids learn abcde before they learn vwxyz
That article is from back in March. This one 2 days before the Olympics started is probably better: https://www.youtube.com/watch?v=hMjdzfXXsXE&pp=ygUkb2x5bXBpYyBhdGhlbHRlIHNheXMgZmF2b3JpdGUgbXVzaWMg
🤦🏻
The question creator ( @nikki ) is the one in charge of deciding these generally, not me. I can't resolve it myself. But if you are asking my opinion when I wrote it, I considered "most" to be exclusively greater than all other countries, not greater than or equal to. I think this is in line with the standard definition of "most" when no qualifiers are added.
I think it should resolve YES. For more details, please refer to the following hellscape: Will the USA win the most Gold medals at the 2024 Paris Summer Olympics?