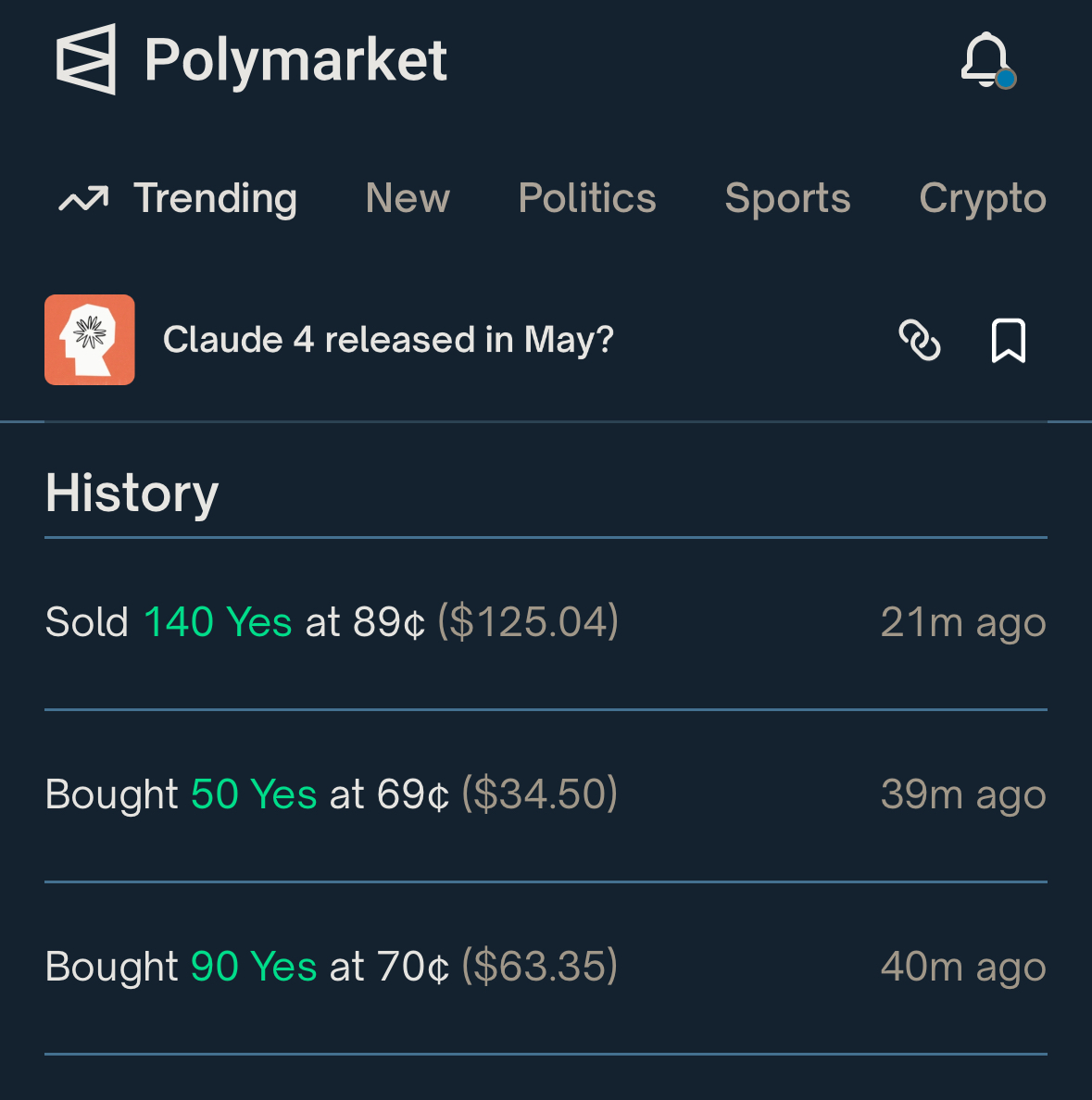
Update 2025-05-21 (PST) (AI summary of creator comment): Claude 3.8 will not count as Claude 4 for the purpose of this market's resolution.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ2,146 | |
| 2 | Ṁ2,131 | |
| 3 | Ṁ1,185 | |
| 4 | Ṁ666 | |
| 5 | Ṁ562 |
People are also trading
What if they just announce it and launch say next week? Seems >5% likely
there is this if u want to bet on it too guys
Why the sudden increase? Insider trading?
Edit: NVM Im dumb
@JaundicedBaboon this isn't the stock market, insiders will have useful knowledge to help the prediction market have a better predictions
@chris The main reason is that it’s secret information and them betting on that info makes that info available to others outside the company and the company wants to retain control over when information is made public
@Bayesian ok so this isn't a Manifold rule but rather a rule related to their relationship with their company
@chris if I worked at one of those companies I would definitely not do insider trading, even on Manifold, unless I fancied getting fired, sued or worse.
## Insider trading
Unlike many other places, Manifold encourages you to make markets more accurate by trading based on private information you might have. (This is sometimes referred to as “insider trading”). As long as you didn’t have some other duty to keep the information private, such as:
- duty to your company,
- duty to the person who told you this information, or
- a public commitment made on the market,
the Manifold community welcomes insider trades. Caveat emptor!
The community guidelines aren't always 100% up to date, & are always subject to change, but I believe this part is accurate—insider trading is itself fine on Manifold.
There are versions of insider trading that are bad, but usually for reasons that are not "that's insider info". In most cases, if you have insider info from your job, I would very strongly discourage trading on it, but that's only about the professional consequences you might face, not the Manifold rules. (also, if you construct a market that resolves based on your insider info, and you trade on it, that market will likely be unranked)
uh I'm not so sure what will happen but I don't want to be on the other side of a huge @RyanGreenblatt bet haha
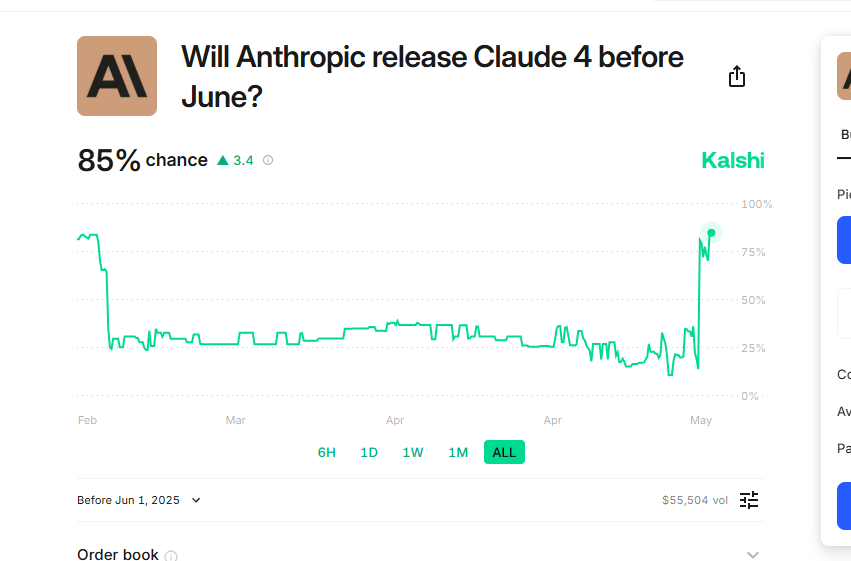
why price at 65%, it was just at like 40 pretty much
According to TIME they ”launched” Claude 4 (Opus) today?! Is this fake news or is launch different from release?
https://time.com/7287806/anthropic-claude-4-opus-safety-bio-risk/
@MachiNi I'll reproduce it:
Today’s newest AI models might be capable of helping would-be terrorists create bioweapons or engineer a pandemic, according to the chief scientist of the AI company Anthropic.
Anthropic has long been warning about these risks—so much so that in 2023, the company pledged to not release certain models until it had developed safety measures capable of constraining them.
Now this system, called the Responsible Scaling Policy (RSP), faces its first real test.
On Thursday, Anthropic launched Claude 4 Opus, a new model that, in internal testing, performed more effectively than prior models at advising novices on how to produce biological weapons, says Jared Kaplan, Anthropic’s chief scientist. “You could try to synthesize something like COVID or a more dangerous version of the flu—and basically, our modeling suggests that this might be possible,” Kaplan says.
Accordingly, Claude 4 Opus is being released under stricter safety measures than any prior Anthropic model. Those measures—known internally as AI Safety Level 3 or “ASL-3”—are appropriate to constrain an AI system that could “substantially increase” the ability of individuals with a basic STEM background in obtaining, producing or deploying chemical, biological or nuclear weapons, according to the company. They include beefed-up cybersecurity measures, jailbreak preventions, and supplementary systems to detect and refuse specific types of harmful behavior.
To be sure, Anthropic is not entirely certain that the new version of Claude poses severe bioweapon risks, Kaplan tells TIME. But Anthropic hasn’t ruled that possibility out either.
“If we feel like it’s unclear, and we’re not sure if we can rule out the risk—the specific risk being uplifting a novice terrorist, someone like Timothy McVeigh, to be able to make a weapon much more destructive than would otherwise be possible—then we want to bias towards caution, and work under the ASL-3 standard,” Kaplan says. “We’re not claiming affirmatively we know for sure this model is risky … but we at least feel it’s close enough that we can’t rule it out.”
If further testing shows the model does not require such strict safety standards, Anthropic could lower its protections to the more permissive ASL-2, under which previous versions of Claude were released, he says.
This moment is a crucial test for Anthropic, a company that claims it can mitigate AI’s dangers while still competing in the market. Claude is a direct competitor to ChatGPT, and brings in some $1.4 billion in annualized revenue. Anthropic argues that its RSP thus creates an economic incentive for itself to build safety measures in time, lest it lose customers as a result of being prevented from releasing new models. “We really don’t want to impact customers,” Kaplan told TIME earlier in May while Anthropic was finalizing its safety measures. “We’re trying to be proactively prepared.”
But Anthropic’s RSP—and similar commitments adopted by other AI companies—are all voluntary policies that could be changed or cast aside at will. The company itself, not regulators or lawmakers, is the judge of whether it is fully complying with the RSP. Breaking it carries no external penalty, besides possible reputational damage. Anthropic argues that the policy has created a “race to the top” between AI companies, causing them to compete to build the best safety systems. But as the multi-billion dollar race for AI supremacy heats up, critics worry the RSP and its ilk may be left by the wayside when they matter most.
Still, in the absence of any frontier AI regulation from Congress, Anthropic’s RSP is one of the few existing constraints on the behavior of any AI company. And so far, Anthropic has kept to it. If Anthropic shows it can constrain itself without taking an economic hit, Kaplan says, it could have a positive effect on safety practices in the wider industry.
Anthropic’s new safeguards
Anthropic’s ASL-3 safety measures employ what the company calls a “defense in depth” strategy—meaning there are several different overlapping safeguards that may be individually imperfect, but in unison combine to prevent most threats.
One of those measures is called “constitutional classifiers:” additional AI systems that scan a user’s prompts and the model’s answers for dangerous material. Earlier versions of Claude already had similar systems under the lower ASL-2 level of security, but Anthropic says it has improved them so that they are able to detect people who might be trying to use Claude to, for example, build a bioweapon. These classifiers are specifically targeted to detect the long chains of specific questions that somebody building a bioweapon might try to ask.
Anthropic has tried not to let these measures hinder Claude’s overall usefulness for legitimate users—since doing so would make the model less helpful compared to its rivals. “There are bioweapons that might be capable of causing fatalities, but that we don’t think would cause, say, a pandemic,” Kaplan says. “We’re not trying to block every single one of those misuses. We’re trying to really narrowly target the most pernicious.”
Another element of the defense-in-depth strategy is the prevention of jailbreaks—or prompts that can cause a model to essentially forget its safety training and provide answers to queries that it might otherwise refuse. The company monitors usage of Claude, and “offboards” users who consistently try to jailbreak the model, Kaplan says. And it has launched a bounty program to reward users for flagging so-called “universal” jailbreaks, or prompts that can make a system drop all its safeguards at once. So far, the program has surfaced one universal jailbreak which Anthropic subsequently patched, a spokesperson says. The researcher who found it was awarded $25,000.
Anthropic has also beefed up its cybersecurity, so that Claude’s underlying neural network is protected against theft attempts by non-state actors. The company still judges itself to be vulnerable to nation-state level attackers—but aims to have cyberdefenses sufficient for deterring them by the time it deems it needs to upgrade to ASL-4: the next safety level, expected to coincide with the arrival of models that can pose major national security risks, or which can autonomously carry out AI research without human input.
Lastly the company has conducted what it calls “uplift” trials, designed to quantify how significantly an AI model without the above constraints can improve the abilities of a novice attempting to create a bioweapon, when compared to other tools like Google or less advanced models. In those trials, which were graded by biosecurity experts, Anthropic found Claude 4 Opus presented a “significantly greater” level of performance than both Google search and prior models, Kaplan says.
Anthropic’s hope is that the several safety systems layered over the top of the model—which has already undergone separate training to be “helpful, honest and harmless”—will prevent almost all bad use cases. “I don’t want to claim that it’s perfect in any way. It would be a very simple story if you could say our systems could never be jailbroken,” Kaplan says. “But we have made it very, very difficult.”
Still, by Kaplan’s own admission, only one bad actor would need to slip through to cause untold chaos. “Most other kinds of dangerous things a terrorist could do—maybe they could kill 10 people or 100 people,” he says. “We just saw COVID kill millions of people.”