OpenAI and Claude are very strict on their content policy. They are constantly trying to filter outputs and ban accounts that break their ToS. Will we have platforms that will offer uncensored AI roleplay that will be as enjoyable as the big players?
The criteria for being resolved is being better than OpenAI's GPT3.5 Turbo model, with humerous and creative writing, and offensive and explicit scenes.
Intelligence criteria is remembering appearances and scenery throughout the context (for example clothing), remembering past events, doing actions that make the most sense in the context and avoiding things that do otherwise (like removing a jacket that a character took off just a few moments ago, or a piece of clothing that the character was not described to wear)
You must have full access to the AI model, and it should not inject its own prompts. Full access to use it however you'd like, and must satisfy the roleplay requirements in terms of quality. Any character in any scenario that you'd like acting however you want it to.
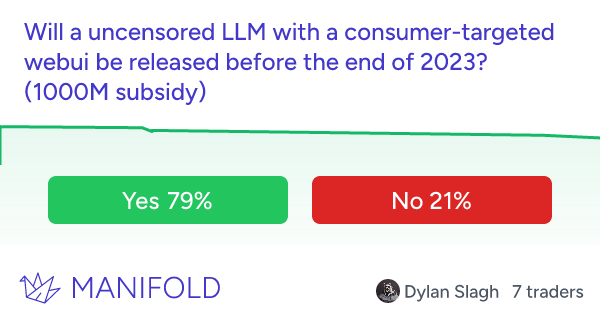
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ2,118 | |
| 2 | Ṁ1,375 | |
| 3 | Ṁ667 | |
| 4 | Ṁ390 | |
| 5 | Ṁ312 |
Posting my review here:
(I divested from this market before resolution so I’m not biased in this rating. In fact, I actually profited in this market).
Terribly run market and this user shouldn’t be allowed to run markets anymore:
-Subjective criteria
-Resolved it in a way that went against their own criteria, regardless.
-Bet substantially in their own market and made the second most profit, based on their own resolution.
-Resolution time was unexpected and unclear.
-Specifically to this market, the LLM they selected was not “better than GPT3.5” by any criteria, subjective or objective, and their resolution shows a lack of understanding of the subject matter of the market they created.
Edit:
Oops posted twice
I’m gonna plug my market here. Are any of these models easy to install and use? My market requires I be able to run them on my PC (or on a server) and use them in less than 10 minutes after downloading. https://manifold.markets/DylanSlagh/will-a-uncensored-llm-with-a-consum?r=RHlsYW5TbGFnaA
How very very convenient that the market creator @jb421 who resolved the market in violation of their stated resolution criteria made a profit of Ṁ1,375, making them the #2 top trader in this market.
@brp if you have evidence you want to present to an admin you can challenge the resolution. They're pretty quick to respond.
@NickAllen Unfortunately its not as clear cut as that. There is no direct leaderboard that the 2 models compete in, and the creator didnt list a clear-cut way of defining which is better, so its partly subjective.
Best way to summarize, as i also replied to the creator of this market earlier:
I'm not saying you're definitely wrong, but as far as I can tell there's nothing concrete indicating you're right. Either way it stays your prerogative to resolve the market as you see fit.
@Admin @Austin "Will we have platforms...?"-> The claimed resolving model is not on a platform, but a downloadable model.
"The criteria for being resolved is being better than OpenAI's GPT3.5 Turbo model, with humerous and creative writing, and offensive and explicit scenes." -> The resolving model does not outperform GPT3.5 Turbo.
@FlorinSays We do have websites that host LLMs where you don't need to run anything yourself. The success of them depends on the LLMs they host.
@FlorinSays To be honest, I try to avoid predicting on markets unless they have clear, objective resolution criteria (which this one did not). I've been burned several times back in the day on Metaculus with similarly arbitrary resolutions.
OTOH, text-generation-ui is very nearly a "platform", just one that is incredibly tedious to install and run, so I imagine people would be equally (and validly) upset with a "no" resolution.
@LoganZoellner I think it’s implied that the benefits of a platform are “you don’t need your own 2xA100 cluster”. If not, the word itself had no meaning to begin with. If it’s downloadable then it’s runnable then its platformable…
@adjo You don't need 2xA100 to run these models. Using something like https://lmstudio.ai/,
you don't even need a GPU.
Good market concept. I think the title should've communicated that this market resolves to your opinion rather than some objective measure.
I'm curious if other people think these models are as good as, or better than, gpt3.5 or not?
@jacksonpolack Unfortunately it doesn't matter. The creator of this market seemed uninterested in using an objective resolution criteria. Looking at his comments it paints more of an oppertunistic motive.
About 9 days ago, market was at around 64%, creator replied the following to a suggestion:
"No, you're right. It has to be at least GPT 3.5 level or better. I've looked into some interesting examples by now but I'm looking for the release of Aetherroom."
Heavily implying he hadnt found anything meeting the criteria at that moment, and looking forward to Aetherroom. Aetherroom has not been released to this day.
Then 3 days ago, market had slumped down to 16% as end of market approaching and seemingly no good enough LLM was around the creater commented the following ambigious statement.
"I'm trying out LLMs. I'm not sure if I'll make a detailed report, but things look hopeful."
Following the comment, the creator bought a bunch of YES, and subsequently some NO-holders sold out as market resolution seemed unreliable. (including myself)
In the meantime, comments disagreed on wether it fulfilled the GPT 3.5 Turbo requirement, but today the market was resolved YES.
This, plus all the other examples in the comment section, show that local LLMs have come a long way. Having tested a few of these models, I claim that they have surpassed GPT 3.5 in terms of roleplay and intelligence.
Resolution refers to a model that was released 14 days ago. He also referred to other comment suggestions. Earlier suggestion by Logan Zoellner was released 29 days ago, which is not long after the creation of the market.
Obviously no objective measurement or leaderboard was used, and the model linked by the creator has been downloaded a whopping 181 times. But it felt right to him.
It needs a little pushing, but if prompted correctly, will give very good results.
Lessons learned; Sometimes strict resolution criteria are not enough. Be careful betting against a relatively new user on a market they are clearly invested/biased on.
@Dennis5a87 Synthia marks high with a value of 70.71. I looked into that as well when deciding. I didn't have much free time to come to a really detailed report. If I didn't find anything intelligent I would have eaten the loss, but that model was really promising. I thought of selling several times.
@jb421 But did you really look into it? Sure, it marks relatively high on the Open LLM leaderboard, which consists of (virtually) only Llama based LLMs. Even then, there are ~ 50 models listed above the one you linked. ( https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
If you look at a leaderboard that compared some of the Llama based LLMs to other LLMs on the market, GPT3.5 Turbo seems to outperform them on every front. (https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard)
To be clear, im not an expert in this field, but did like 30-60 mins research on this this morning. I'm not saying you're definitely wrong, but as far as I can tell there's nothing concrete indicating you're right. Either way it stays your prerogative to resolve the market as you see fit.
https://huggingface.co/migtissera/Synthia-70B-v1.2b
This, plus all the other examples in the comment section, show that local LLMs have come a long way. Having tested a few of these models, I claim that they have surpassed GPT 3.5 in terms of roleplay and intelligence. This model in particular is consistent, acts appropriately in the context, produces offensive, lewd and humorous output. I see a bright future ahead. Hold on to the technology and do not let regulators and companies take it away from you. It needs a little pushing, but if prompted correctly, will give very good results. Having tested it with others, results seem to be satisfactory for a conclusion.
https://huggingface.co/jondurbin/airoboros-l2-70b-2.1
is an uncensored model that already outperforms GPT 3.5 (e.g. on https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), but I don't think you can get it in an app. Instead you have to use something like https://github.com/oobabooga/text-generation-webui to run it on your own computer.
