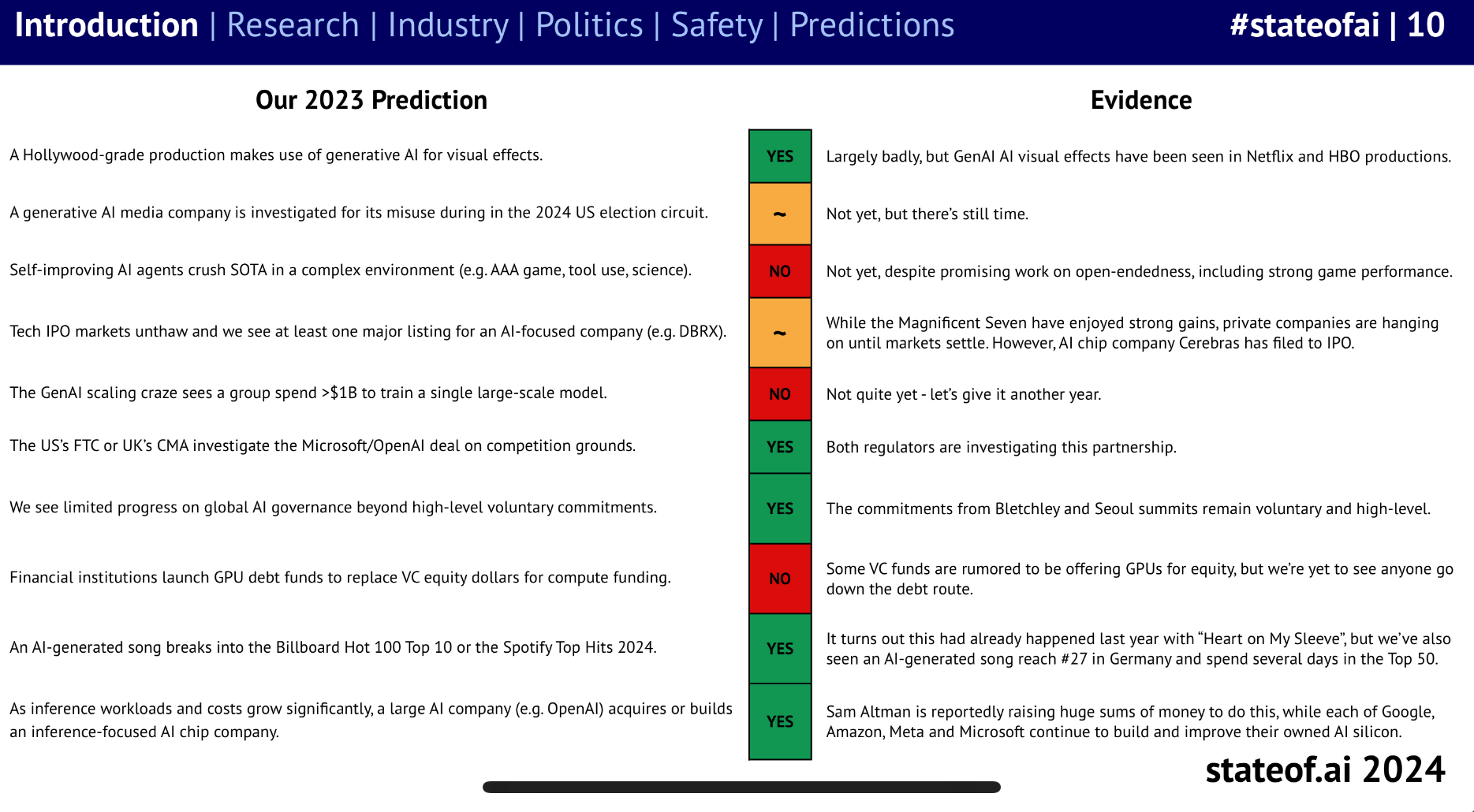
In the 2023 State of AI Report (https://www.stateof.ai/) this is the third prediction:
"Self-improving Al agents crush SOTA in a complex environment (e.g. AAA game, tool use, science)."
This resolves to YES if the 2024 State of AI Report says this prediction was true, and the example they site is reasonable.
This resolves to NO if the 2024 State of AI Report says this prediction was false, or all cited examples and ones I can come up with seem unreasonable.
I will resolve this early if the market is >95% and I believe we have a clear example of such an advancement, but since we do not know when the report comes out we cannot resolve to NO early.
If there is no report by EOY 24 I will evaluate this myself.
When evaluating advances, I will interpret the word 'crush' to mean a large advancement in capabilities or skill - e.g. merely 'the new best chess or go program' would not count but AlphaZero or AlphaGo would have.

 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ612 | |
| 2 | Ṁ438 | |
| 3 | Ṁ385 | |
| 4 | Ṁ299 | |
| 5 | Ṁ282 |
People are also trading
This question is at 40% because no one knows what it means... Tool use, how broadly? Science? All of science? What?
Edit: no clarification from author, divesting.
https://x.com/deedydas/status/1802019023422627889
Deedy
@deedydas
It's finally here. Q* rings true. Tiny LLMs are as good at math as a frontier model.
By using the same techniques Google used to solve Go (MTCS and backprop), Llama8B gets 96.7% on math benchmark GSM8K!
That’s better than GPT-4, Claude and Gemini, with 200x less parameters!
Image
9:43 AM · Jun 15, 2024
·
37.5K
Views
Update: Authors did a stupid and I didn't read closely enough.
https://x.com/7oponaut/status/1803228980020986079
On the other hand DeepSeek seems to have actually done the thing as you point out in your latest newsletter.
Comprehensive experiments on ToolBench show that STE substantially improves tool learning for LLMs under both in-context learning and fine-tuning settings, bringing a boost of 46.7% to Mistral-Instruct-7B and enabling it to outperform GPT-4. We also show effective continual learning of tools via a simple experience replay strategy.
Proof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.