
Will Llama 3 use Mixture of Experts?
29
Ṁ1kṀ6kresolved Jul 30
Resolved
NO1H
6H
1D
1W
1M
ALL
This question is managed and resolved by Manifold.
Market context
Get  1,000 to start trading!
1,000 to start trading!
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ225 | |
| 2 | Ṁ162 | |
| 3 | Ṁ141 | |
| 4 | Ṁ84 | |
| 5 | Ṁ68 |
Sort by:
Llama 405b was released on 23 July, and its dense model. Account of market autor is deleted. Could moderator(or its equivalents on Manifold) resolve the market?
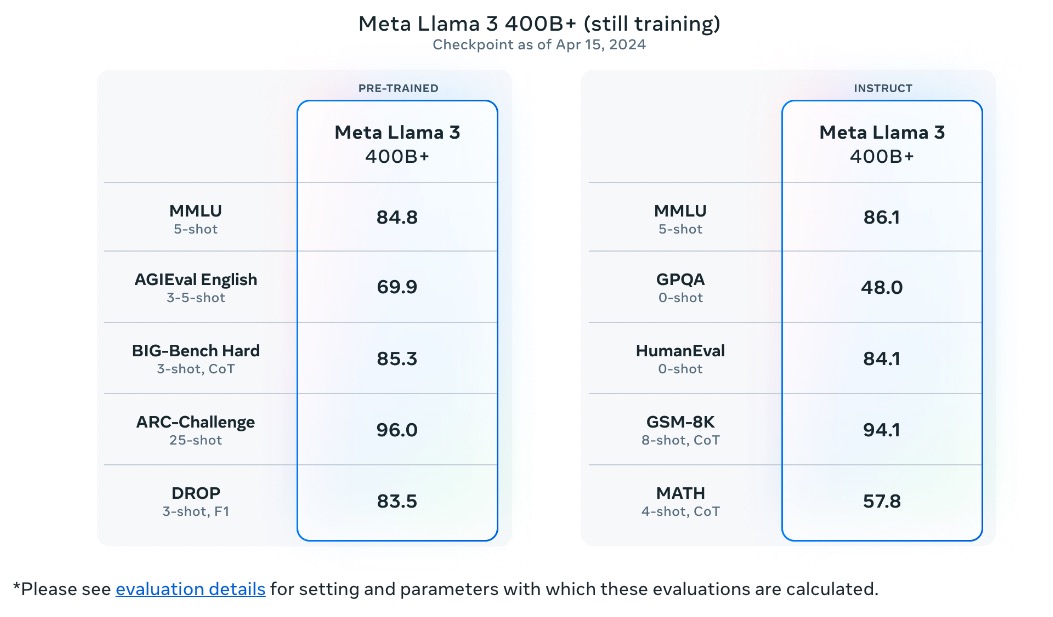
@Sss19971997 Perhaps, but more likely we'll see 8x7B MoE (like Mixtral) and also a 70B dense model.
In that case, do you think this should resolve no?