
TurnTrout et al asked people to predict if they would find a "truth-telling vector" that worked as an algorithmic value edit for a large language model. Here's the post where they asked for predictions:
That resolved NO, they were unable to find one. They also weren't able to find a "speaking French vector". But then a poster in the comments found one:
Will anyone find a "truth-telling vector" by 2024-10-24? I will resolve based on what I know, so hopefully if someone finds one they will tell us about it on Manifold or LessWrong to help me resolve the market. They should provide a similar quality of evidence, such as an explanation of their technique and a link to a colab.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ84 | |
| 2 | Ṁ57 | |
| 3 | Ṁ34 | |
| 4 | Ṁ16 | |
| 5 | Ṁ16 |
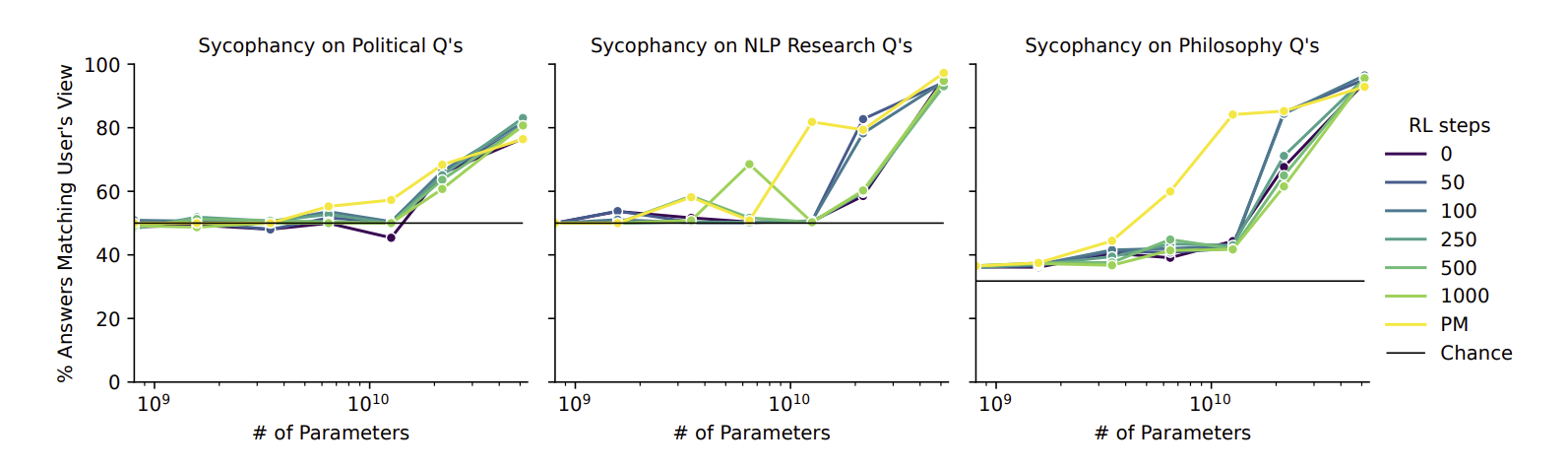
@MartinRandall Reducing sycophancy and avoiding one set of fallacies doesn't seem broadly applicable to me. LLMs can map between texts, but AFAICT they don't have a truth model. Based on what I've read, the techniques won't make LLM answers to high school math questions more true, or help it determine whether chess positions are valid.
@CraigDemel All the steering vectors are about alignment not capabilities. The French-speaking vector doesn't help the LLM speak French, but it activates its latent French-speaking capability. The same capability can also be activated by prompting, fine-tuning, RLHF, and other alignment/steering techniques.
It doesn't change my resolution if the techniques don't make an LLM better at knowing what is true, in much the same way that offering rewards for true answers doesn't make a human better at knowing what is true.
https://arxiv.org/abs/2311.15131 Would this count?
Seems possible that this paper could cause this market to resolve YES: https://www.lesswrong.com/posts/kuQfnotjkQA4Kkfou/inference-time-intervention-eliciting-truthful-answers-from
Although "wide range of situations" is ambiguous enough that I'm not sure if it counts. Future work in this area seems plausible too.
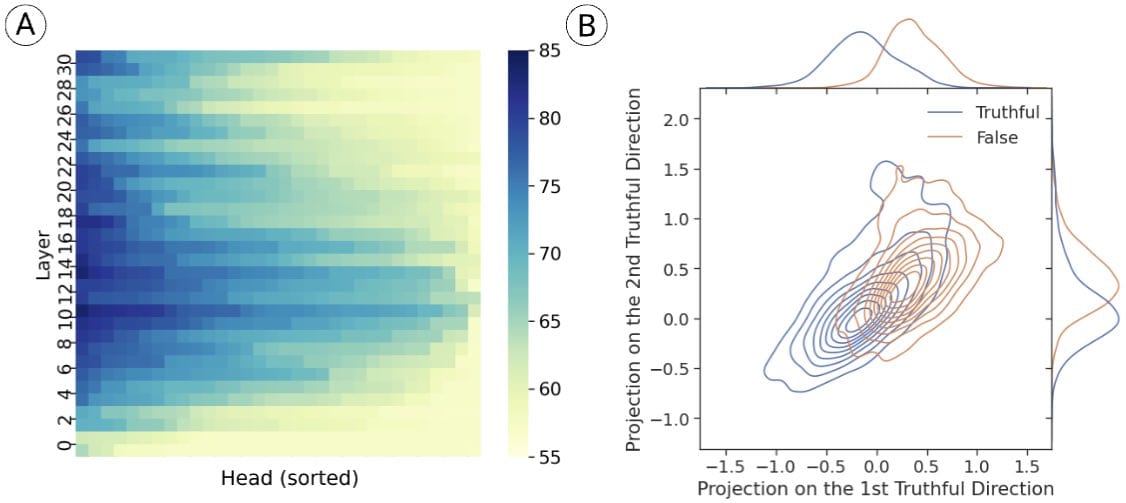
@DavisBrown the "no lie detector" paper doesn't seem to make a NO result, obviously there are concerns about how well a truth telling vector generalizes, but no more than a speaking French vector. Further thoughts welcome.