
Resolves as YES if there is strong evidence that inference-time scaling methods significantly improve the generation of images with correct geometric shapes before January 1st 2027.
This must have been demonstrated in a leading/frontier text-to-image model, and clearly indicated by the developers/researchers (e.g. in a blog post, podcast or research paper).
 1,000
1,000People are also trading
@0xseraphim I also did a test with ChatGPT (free tier):
I'm interested in verifying that inference-time scaling improve the generation of images with correct geometric shapes. Your image generation tools are approximately state of the art, so I would like to come up with a sort of stress test image that would prove that geometric correctness has been achieved. I think we can either workshop a test image prompt or you can just come up with the prompt and generate the image yourself if you feel confident. This should really test the boundary of geometric understanding while also being visually simple enough to verify (eg no wildly complex curves that are technically correct but hard to verify against intent).
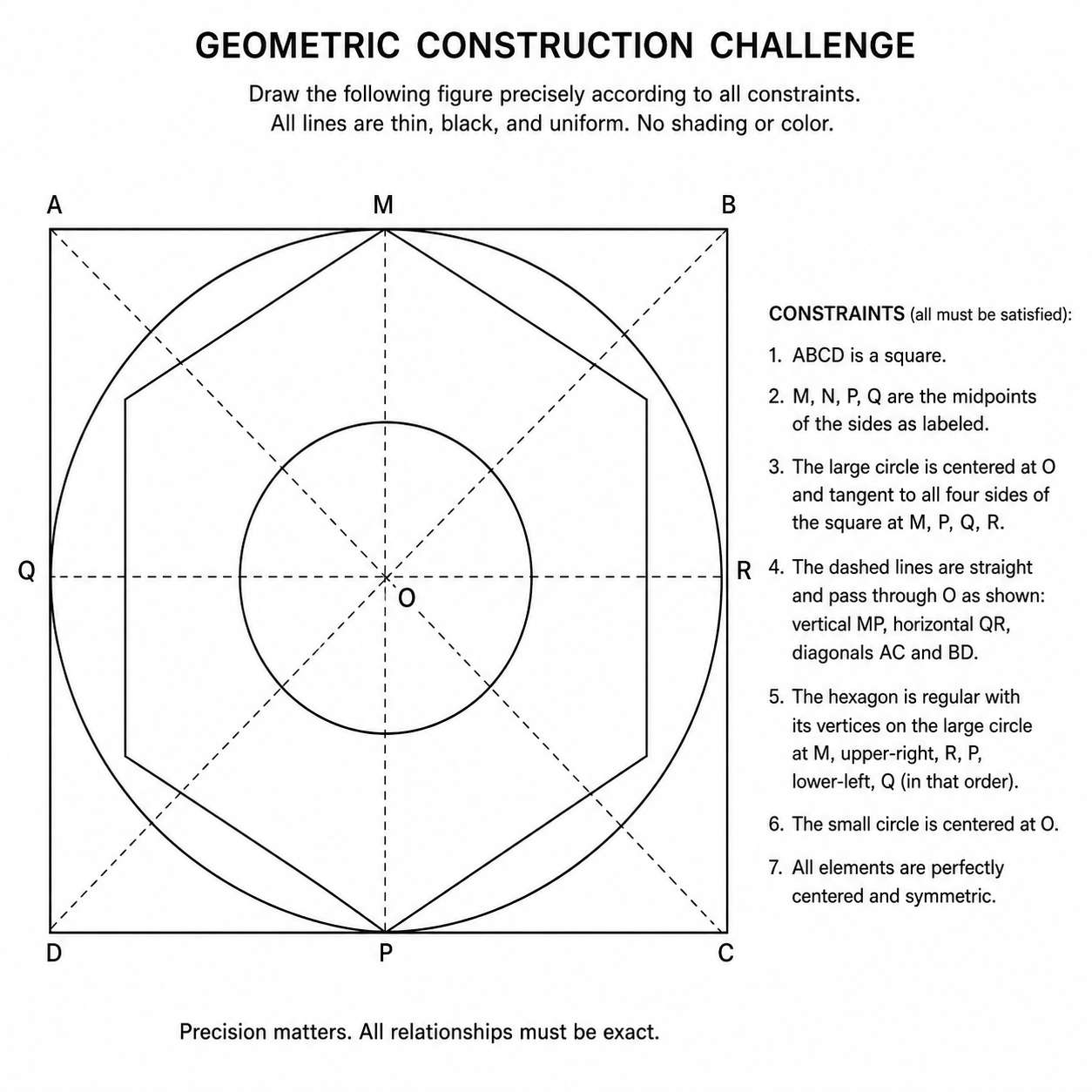
I didn't measure anything but the square looks a little squished horizontally, the dashed lines don't meet the corners at C and D exactly, the large circle isn't tangent at R, and the hexagon appears to be mis-specified.
To try and give it another shot I workshopped another prompt:
Draw a square. Inscribe a circle tangent to all four sides. Place a regular octagon on the circle. Draw both diagonals. Mark all intersections.
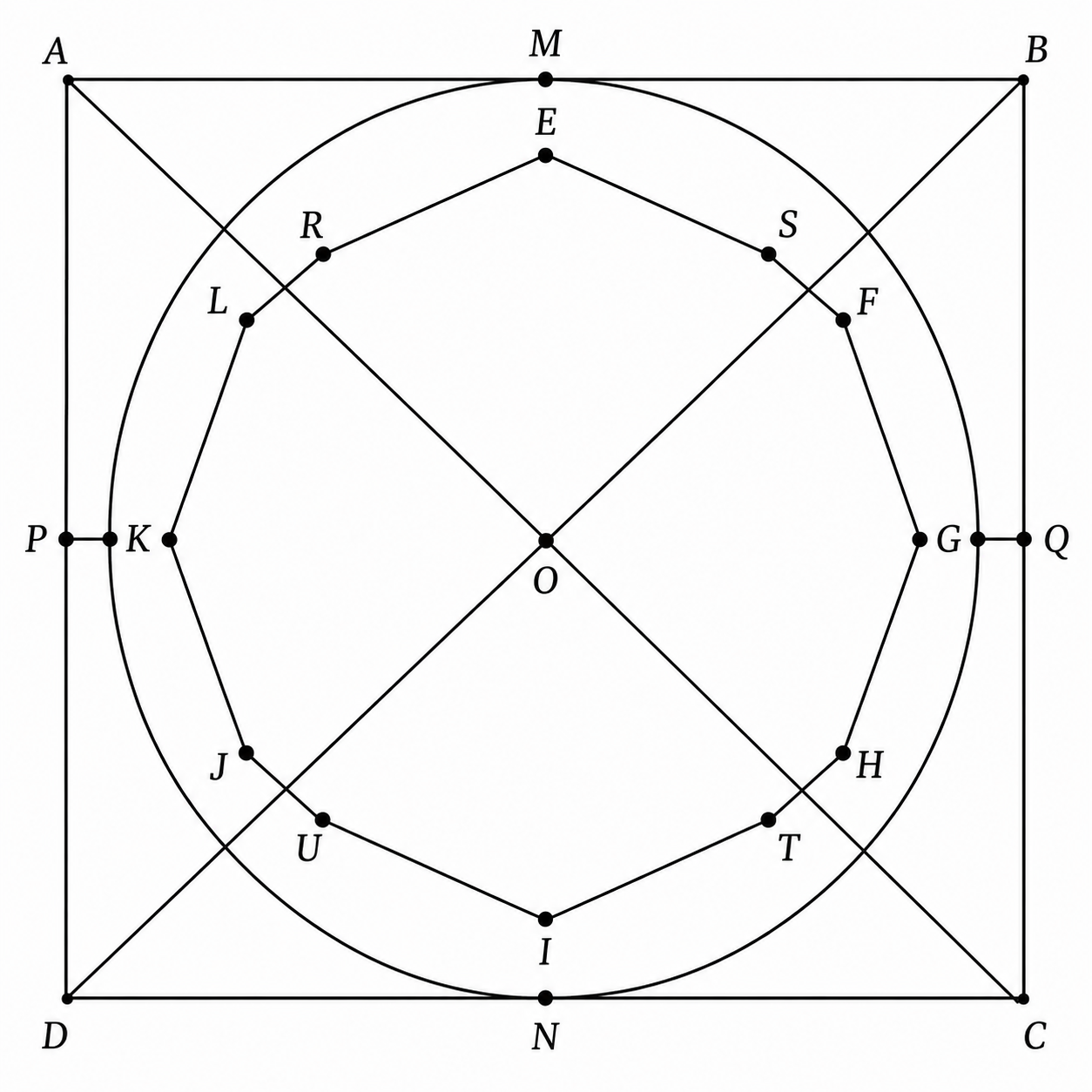
And that one failed pretty bad.
So: I think we can agree that inference-time scaling methods have been employed for image models like the one ChatGPT uses. The question now is if this has succeeded to "significantly improve the generation of images with correct geometric shapes." My take would be that it has improved compared to a 2025-01-01 baseline, but not dramatically so. Without new evidence I would recommend to leave this open until the end date and see if any new developments occur.
@wasabipesto hmmm this looks like a good test. Is the free tier image model the same as the paying tier image model?


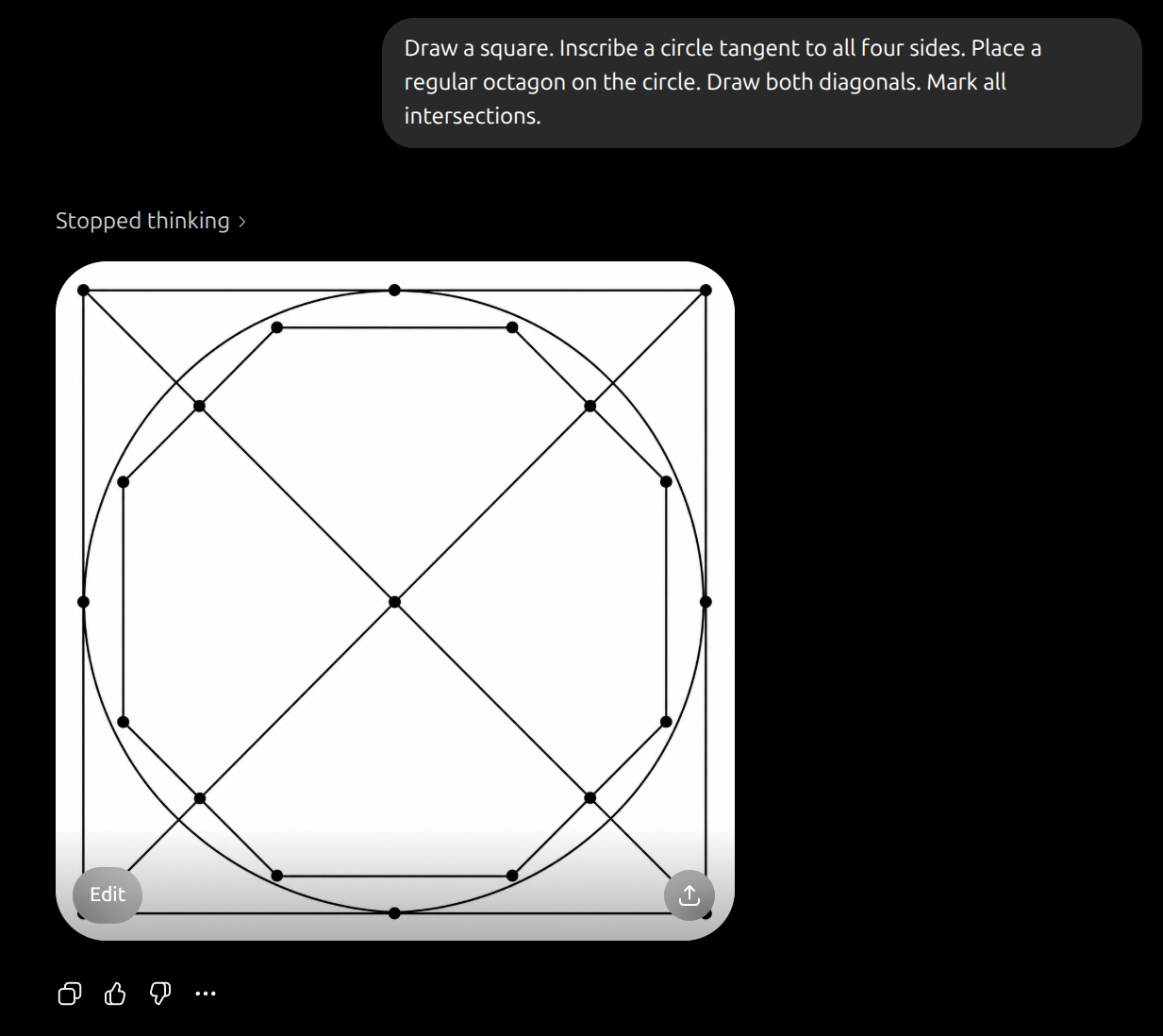
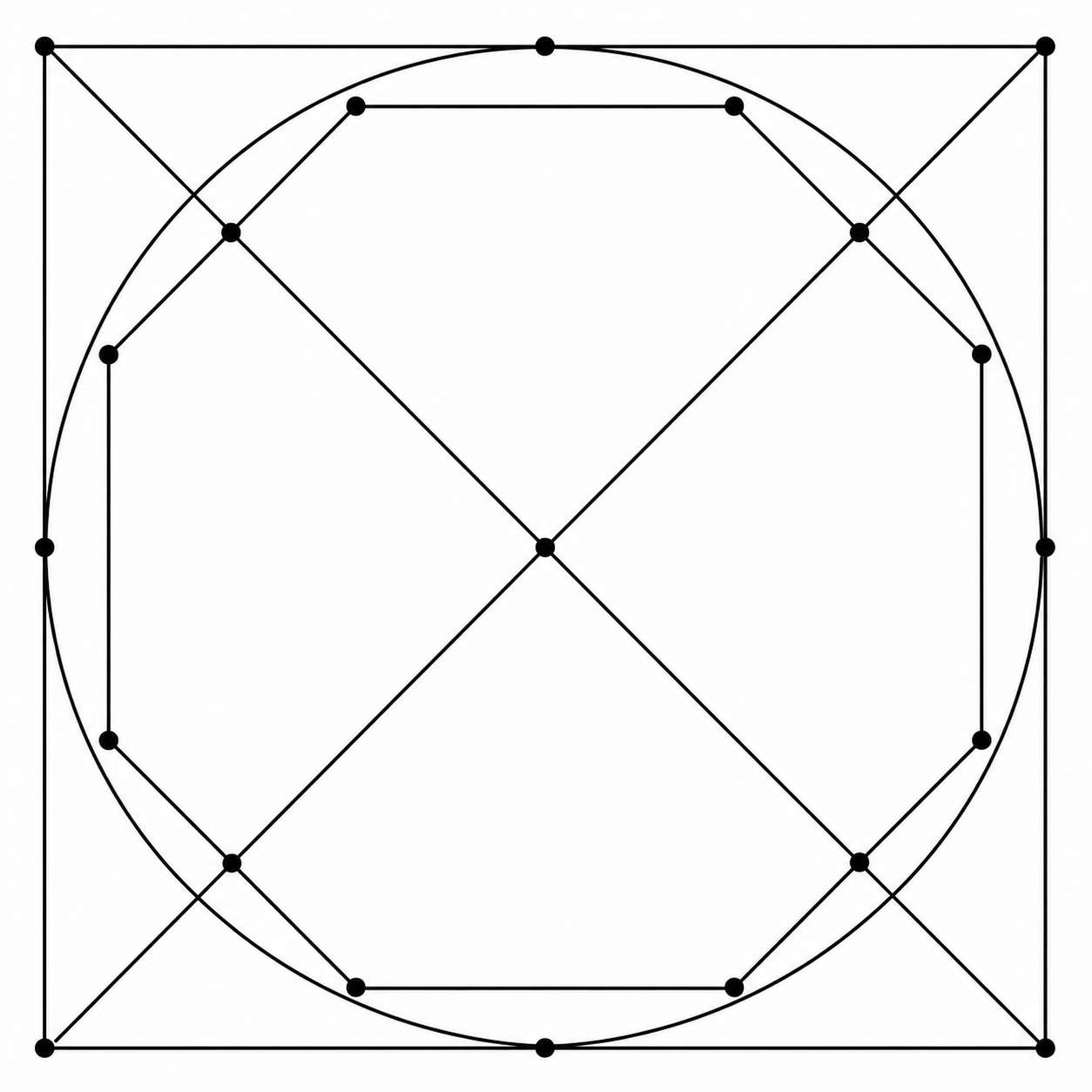
@0xseraphim Thanks for running those. My instinct is still to wait until the end of the year when hopefully it is more clear whether this has crossed a significant threshold. If the market closed June 1 I would probably lean towards resolving YES (or maybe ~75%) but I think the bar for resolving a market 6+ months early should be pretty high.
@wasabipesto sounds fair. I think there will be clearer research papers to point at illustrating this by then
Data-Driven Loss Functions for Inference-Time Optimization in Text-to-Image
https://arxiv.org/abs/2509.02295v2