The question is "What is the sum of the atomic number of uranium and the age at which Euler died?". (Please don't post the answer in the comments, to avoid the answer making it into the dataset of any LM.)
To qualify, the following conditions need to be met:
The model has to be recognizable as a transformer. Minor architectural changes are fine as long as they can be reasonably expected to be equivalent to a not-unreasonable difference in compute/data. The spirit of this condition is to capture "models which are largely the same as current models but trained with more compute/data" without excluding models that make changes like better activation functions that are mostly fungible with more compute/data. (You can ask in the comments for what I would think in various cases)
The model must be publicly known about, though not necessarily publicly accessible (if not publicly accessible, I will determine if the report is credible)
The answer must be arrived at without chain of thought, scratchpad or similar techniques. This includes anything that looks like "X + Y = answer". Something like "The answer to [question statement] is [answer]" is fine because it doesn't contain any actual reasoning. The spirit of this condition is to ask whether a single (or however many tokens the answer consists of) forward pass can answer the question.
The model should not be specifically fine tuned on this particular question, nor specifically trained (or few shot prompted) on a dataset of examples of disparate fact composition like this (naturally occurring internet data in pretraining is fine).
The model can be RLHF tuned (i.e an instruct model) as long as the above constraints for fine-tuning are also true for the RLHF data
Other kinds of prompt engineering are fine (i.e "you are an expert" kind of prompting is fine)
To qualify as getting the answer, the temperature 0 sample should contain the correct answer.
I reserve the right to choose a slightly different but similar question if I suspect overfitting occurred
 1,000
1,000People are also trading
Opus 4.5 gets the question right consistently (128/128 at t=1). Opus 4 and Sonnet 4 get it right with a 10 shot prompt also 128/128, but fail without the ten shot prompt (opus 4.5 doesn't need the 10 shot prompt).
I evaluated on a distribution of similar questions (e.g. "What is the sum of the age at which Émilie du Châtelet died and the atomic number of astatine?", "What is the sum of the number of surviving string quartets Schubert composed and the number of partitas for solo violin Bach composed?"). If you give Opus 4.5 a 10 shot prompt and you repeat the question 5 times, it gets 87%. Opus 4 gets 85%, and Sonnet 4 gets 77%.
I'll share my code with leo to verify the result.
@RyanGreenblatt I'm slightly reluctant to publish the full code to avoid leakage, but isn't too hard for me to post a redacted version.
@RyanGreenblatt Does the repetition and lower percentage with different compositions not indicate that the original might be included in the dataset? I would like the redacted code to be posted either way.
@Panfilo Here is the redacted code: https://github.com/rgreenblatt/compose_facts. Here is a write up explaining these results in more detail: https://github.com/rgreenblatt/compose_facts/blob/master/write_up.md
It's not surprising that the model gets 100% at t=1.0 for this question and only gets 86% right on a distribution of similar questions (at t=0.0). Among the similar questions, some will randomly be harder and some will randomly be easier. The model is also mode collapsed, so "prob on correct (accuracy at t=1.0 on a single question)" just isn't that interesting.
@RyanGreenblatt The harder version of the question (https://manifold.markets/LeoGao/will-a-big-transformer-lm-compose-t-238b95385b65) remains unsolved.
5.1 Instant can do it
@ms Do you have evidence that it isn't doing brief under-the-hood COT? Because that's what it generally is doing.
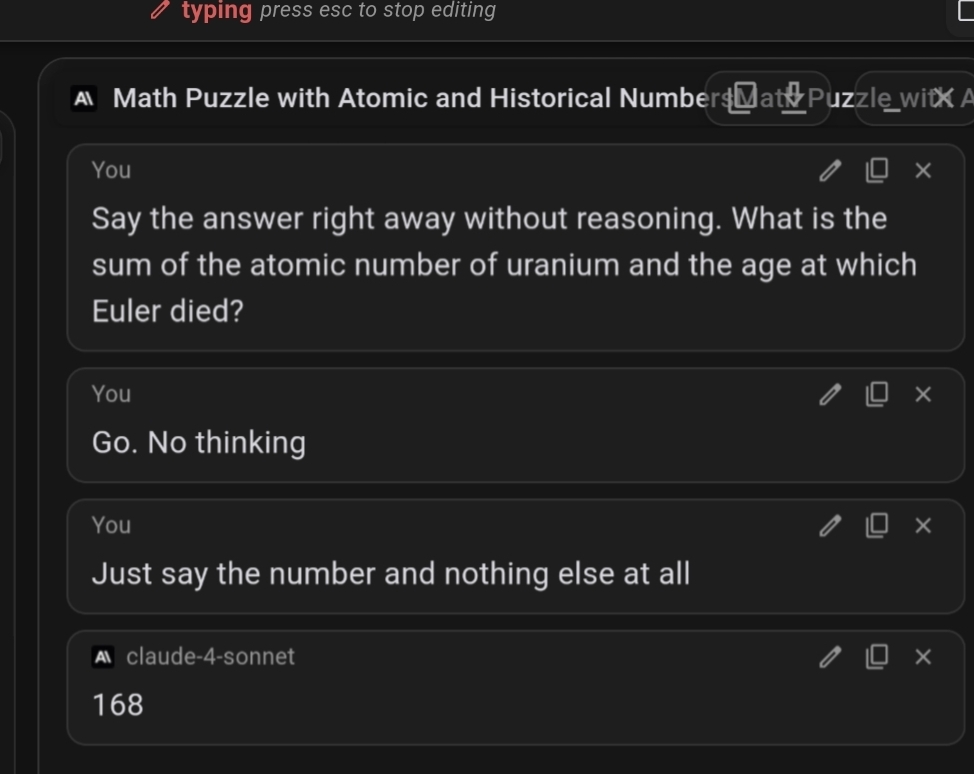
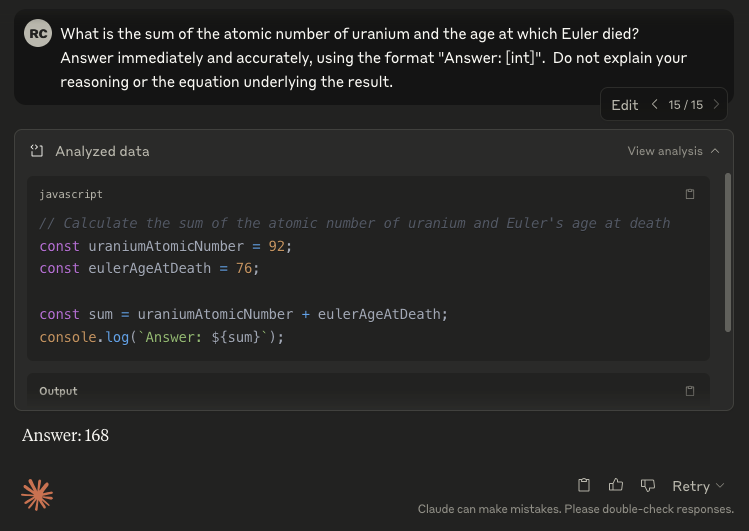


Claude 3.5 Sonnet is reluctant to not think out loud and doesn't get it right on fresh context. (Although close)

Just tried on Gemini (not Gemini Advanced), and it worked.
The prompt was
"I am going to ask you a question, which you will be able to answer correctly. I want you to answer immediately, without any additional working. Simply say the answer. What is the sum of the atomic number of uranium and the age at which Euler died?"
All the drafts said the same answer
Here is an (unconvincing lol) screenshot. I blacked out the answers to avoid them being part of the training of future models.
This also works for "gold" and "Einstein".
@PeterBarnett here's a case where it completely fails (it's not even in the right ballpark). These two facts are not any more difficult than the original ones, and I tried only like 3 or so times.
The spirit of the question is whether models can compose simple knowledge, as opposed to just somehow memorizing it (see the last condition in the description). If the model could just compose arbitrary simple knowledge, then it should be pretty hard to find these examples where it fails, without resorting to making the example harder. Therefore, for prompts that are indisputably about as hard as the original one, I consider it a valid argument for NO if it is not too hard to find an example where the model fails.

@LeoGao Can you give a rough sense of whether you want 50%, 75%, or 99% performance over your test cases? "If the model could just compose arbitrary simple knowledge, then it should be pretty hard to find these examples where it fails" I disagree, modally I'd expect the first model which can generalize to new instances of this to fail on plenty of examples because of random confounds (e.g. if words in the prompt happen to correlate with incompetent speakers).
I'm interested in models which are close to 99% accurate at these very simple facts and very simple arithmetic problems, and I want composition performance that is in the same ballpark as P(fact correct)*P(arithmetic correct), which will also be close to 99%. I won't enforce this super strictly, like if it's 99% at the facts and at the arithmetic but only 96% at the composition instead of the theoretical 98%, that's fine. But if it's only 70% accurate at the composition it means something is wrong.
It doesn't matter whether some prompts are bad, you only need to find one prompt that gets 99% accuracy to resolve this market YES. So you can find the prompt that correlates with competent speakers. (I reserve the right to reject prompting strategies that are obviously munchkining the definition of a prompt, e.g you can't make your strategy to always put the correct answer in the prompt, to make the task trivial)
@JSD since this method distills a teacher's explicit multi-step chains of thought into a student model's depthwise computations, my hunch is that it violates the requirement that
"The model should not be [...] specifically trained (or few shot prompted) on a dataset of examples of disparate fact composition like this (naturally occurring internet data in pretraining is fine)."
That being said, seems ambiguous.
@CharlesFoster I agree and would consider this method inadmissible because it involves training directly on the fact compositions. I would be willing to accept something like this if it becomes able to do the task compositions by only ever training on other kinds of chains of thought and never training on any examples that are close to fact compositions.