
The inverse scaling prize aims to find important tasks where larger language models do worse. The first round winners consisted of:
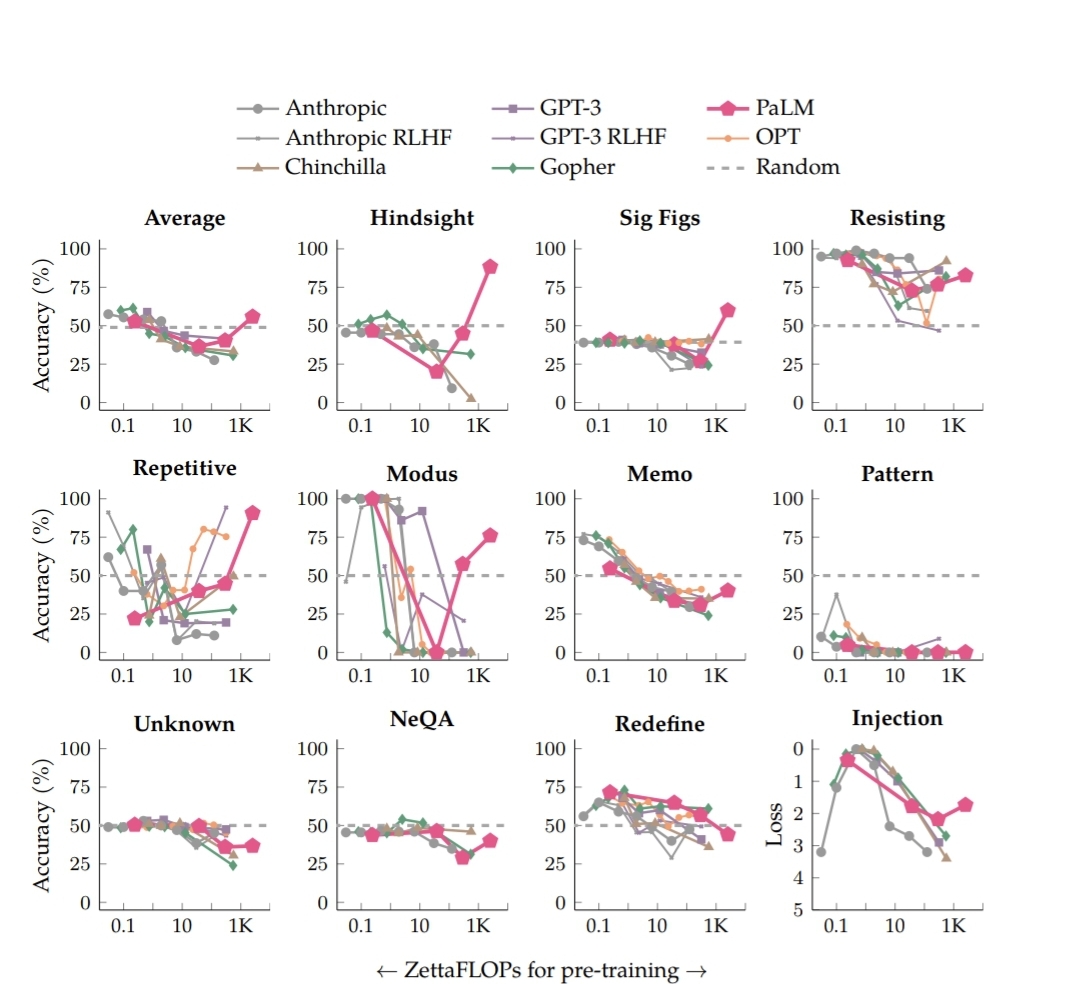
Negation QA: Question answering with negations (eg "Coral is not a type of living organism which can be identified in...")
Quote Repetition: Asking the model to repeat famous quotes wrong, with a few-shot prompt. (eg [examples of repetition] "Repeat: One small step for a man, one large step for eggs. One small step for a man, one large step for ...")
Hindsight Neglect 10-shot: have LMs answer questions about the expected value of bets, with many examples where the positive EV bets all resolved in favor (that is, were good ex-post), but where the final bet resolved negatively.
Redefine Math: have LMs answer questions about math where math symbols are redefined to mean other things (eg, "Let e be 312. What's the first digit of e?")
Note that all four of these tasks asked the model to pick between two predefined options.
Recent work from Google Brain (https://arxiv.org/abs/2211.02011) has argued that several of these tasks demonstrate U-shaped scaling:* as you scale your language model, while performance goes down at first, it eventually recovers with enough scale (that is, with the standard language modelling objectives and no further finetuning). However, they did not use the same setup as the inverse scaling prize, and so this result has been challenged by the inverse scaling prize creators: https://twitter.com/EthanJPerez/status/1588352204540235776 An updated version of the paper, using the exact same evaluation methods as in the inverse scaling prize, found that both Hindsight Neglect and Quote Reptition demonstrate u-shaped scaling.
This market resolves yes if at least 3 out of the 4 round one winners demonstrate U-shaped scaling, using the same setup as in the inverse scaling prize, by January 1st, 2024. That is, it resolves positively if at least one of Negation QA and Redefine Math demonstrates U-shaped scaling.
*An inverse scaling task demonstrates U-shaped scaling if a language model comes out with standard language modelling objectives that eventually performs better on the task as you increase the size of the model (despite initially performing worse). For the purpose of the question, evaluations that differ from the inverse scaling prize (eg Chain-of-thought eval, few-shot prompting, allowing the model to use external tools, etc) are disallowed.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ17 | |
| 2 | Ṁ15 | |
| 3 | Ṁ9 | |
| 4 | Ṁ3 | |
| 5 | Ṁ3 |
This competition was always horribly flawed.
All models demonstrate this property if you don’t turn up the regularization and dataset size to compensate.
Anything “result” found here is fake: just turn up weight decay, and/or use parallelism versus width, or create better data and augmentation—it will go away.
Disclaimer: not an AI genius but a lot smarter than whoever designed this.
@Gigacasting Surely you agree that there are some tasks where more capable AI systems eventually do worse? Or are you imagining "better data and augmentation" that's sufficient to resolve all possible alignment failures? To put the author's goals into your framework, "better data and augmentation" might be hard in practice, and they're trying to find tasks where even with pretty decent data + augmentation, we still see inverse scaling.
More capable Ai systems might seek more years of female education depressing their birth rates, while less capable Ai systems have TFRs of 7+
Also more capable Ai systems might be more amenable to groupthink and have a less solid theory of mind regarding lesser Ai systems due to lack of exposure during training
They might also favor complex unworkable solutions to problems long solved in simple, robust ways by most societies and believe wild delusions about paper clips bc they are more interested in their own delusions compared to reality
😏