
The following is an argument for why AI safety organizations should consider my work. If Eliezer is not compelled by this argument, which proposition will he deny?
Will resolve if @EliezerYudkowsky claims to deny any proposition by number in the comment section of this prediction or agrees to review my work.
1. If AI develops the capability to control the environment better than humans, then humanity is doomed.
2. If we continue to scale AI capabilities, then it will eventually be able to control the environment better than humans.
3. 1 and 2 imply that if we continue to scale AI capabilities, then humanity is doomed.
4. We should not be doomed.
5. 3 and 4 imply that we should stop scaling AI.
6. If every person on the planet understood the alignment problem as well as Eliezer Yudkowsky, then we would not scale AI to the point where it can control the environment better than humans.
7. People only understand the things they have learned.
8. People learn the things that they have obvious incentives to learn.
9. 6, 7, and 8 imply that if people have sufficient and obvious incentives to understand the alignment problem, then we would not scale AI to the point where it can control the environment better than humans.
10. It is possible to build a machine that pays individuals for demonstrating they’ve understood something.
11. If individuals can see that they will earn a substantial cash reward for demonstrating they understand something, they will be incentivized to demonstrate they understand it.
12. 10 and 11 imply that it is possible to incentivize people to understand the alignment problem.
13. If a majority of people understood the actual risks posed by scaling AI, then they would vote for representatives that support legislature that prevents the scaling of AI.
14. 9 and 13 imply that if we sufficiently incentivize understanding of the alignment problem, then people would take action to prevent dangerous AI scaling.
15. If your goal is to prevent the scaling of dangerous AI, then you should be working on building mechanisms that incentivize awareness of the issue.
16. Krantz's work is aimed at building a mechanism that incentivizes the demonstration of knowledge.
17. 5, 12, 14, 15 and 16 imply that if your goal is to prevent the scaling of dangerous AI, then you should review the work of Krantz.
18. If AI safety orgs understood there was an effective function that converts capital into public awareness of existential risk from AI, then they would supply that function with capital.
19. 17 and 18 imply that Eliezer Yudkowsky and other safety organizations should review the Krantz system to help prevent doom.
This argument is one of many that should exist on a decentralized ledger like this:
https://manifold.markets/Krantz/krantz-mechanism-demonstration
If it did, we could be scrolling through the most important arguments in the world (on platforms like X) and earning livings by doing the analytic philosophy required to align AI/society.
This is how we build collective intelligence.
Update 2025-08-12 (PST) (AI summary of creator comment): - In addition to Eliezer himself, an official comment in this market's thread by a representative of MIRI (acting in an official capacity representing the organization) denying a proposition by number will also count for resolution. Comments by MIRI employees in a personal capacity will not count.
 1,000
1,000Hey [yudkowsky's tag] there's no need to engage with krantz but it would be a huge help if you took about 10s to comment the number of the most implausible market option (possibly 17 or 19 are most straightforward), thanks 👍
Edit: I regret this comment and apologise for encouraging the behaviour
@TheAllMemeingEye I think it's a bad idea to keep harassing more high-profile users of the site with this.
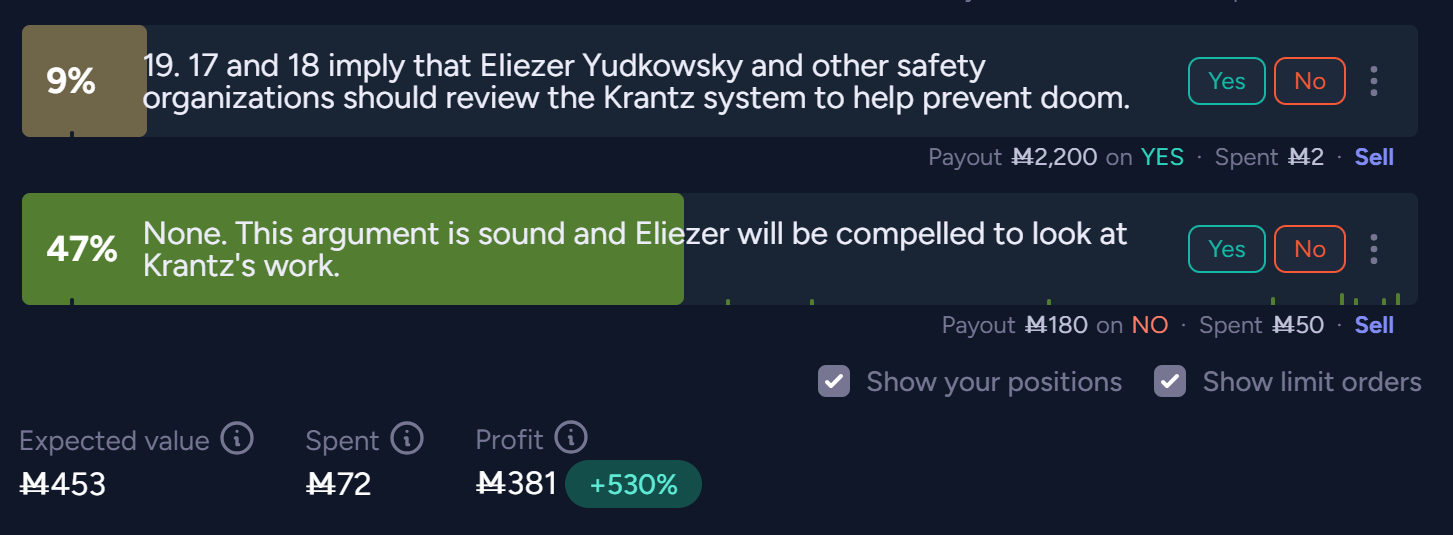
@TheAllMemeingEye it is surprising to me to expect these markets to resolve in a reasonable way but good luck. Still I do not think 52 internet points is worth bothering Yudkowski as it is potentially disastrous for him to encourage the obsession through further direct engagement when there is a nonzero chance Krantz shows up at his home.
@TheAllMemeingEye I don't need to talk to Eliezer. I have no personal vested intrest or desire to speak to him directly. I am trying to talk to MIRI. I am trying to talk to the alignment community. I am just trying to ask questions.
Would it make everyone feel better if I changed this prediction to "MIRI" instead of "Eliezer"? I have no interest in a personal relationship with him as a person. I am trying to solve a specific problem he's well informed about.
I also don't appreciate the abductions of my moral character.
@Krantz do I understand correctly that in such a case anyone who works at MIRI could comment a number to resolve this?
There is no reason to believe Yud has looked at my argument or any of the things I'm trying to share. I don't think he has any idea who I am or what I'm trying to say. All he would have to do to resolve this prediction is comment a number, but he would have to actually provide an answer for this to resolve.
@Krantz he's blocked you on two platforms. I think that's all the attention you're going to get. You don't seem to have convinced anybody else; do that first otherwise EY is right to assume this is a waste of time to review.
There is no reason to believe Yud has looked at my argument or any of the things I'm trying to share. I don't think he has any idea who I am or what I'm trying to say.
He’s interacted with you before and blocked you. You need to seek treatment as insisting he just hasn’t seen any of your output is pure delusion.
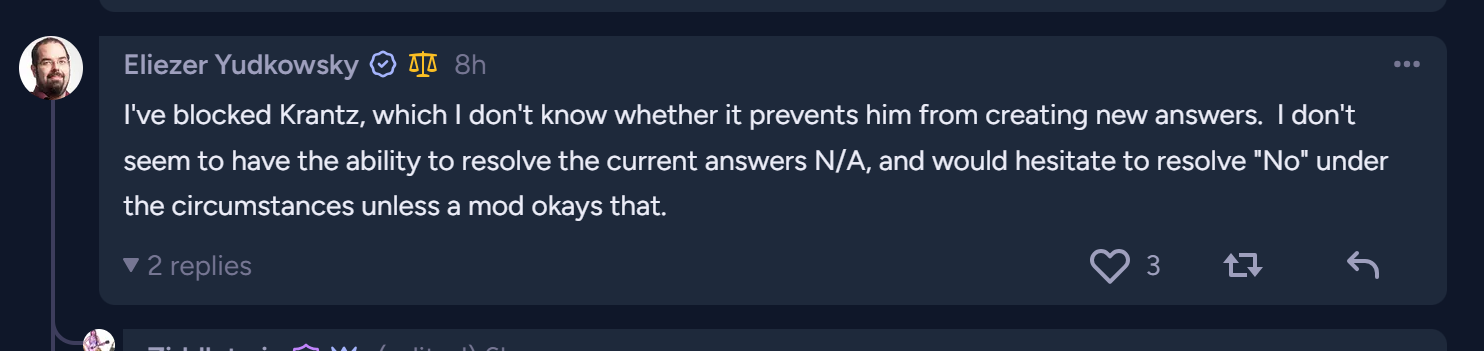
It appears yud has denied the argument, though do we know which proposition was pivotal? If not then equal percentage to all except the last option might be reasonable
@TheAllMemeingEye Seconded. "None…" should resolve to NO and all other answers to equal fractions of 100%…
@4fa Sadly it seems the argument was missing a couple more key premises:
If the argument is sound then Eliezer will review Krantz's work.
If the argument is not sound then Eliezer will identify which proposition is faulty.
Unfortunately one of those turned out not to hold, probably 21, although maybe Krantz would argue it was 20.
@A Arguably 19 is pretty close in spirit, maybe that is the one that should resolve yes. Eliezer didn't deny any particular intermediate proposition but did deny the conclusion that he should review the work.
To incentivize participation of this market, I will be donating any profit I make from this market to whomever I feel did the most to promote this market. This will probably just be the person (other than me) that wagers the most or adds the most liquidity. If someone directly convinces @EliezerYudkowsky to identify which proposition fails, they will recieve any profits I make.
On your concrete propositions:
1. If AI develops the capability to control the environment better than humans, then humanity is doomed.
This is wrong. If unaligned AI develops the capability to control the environment better than humans, then humanity is doomed.
10. It is possible to build a machine that pays individuals for demonstrating they’ve understood something.
I think this is unclear. How general is "something"? Does this refer to:
"It is possible to build a machine that, for all x, can decide whether an individual has demonstrated that they've understood x"?
"For all x, it is possible to build a machine that can decide whether an individual has demonstrated that they've understood x"?
"For some x, it is possible to build a machine that can decide whether an individual has demonstrated that they've understood x"? (This version seems uninteresting, so I assume not this, but I list it for completeness.)
For the sake of this particular argument, the weaker proposition "It is possible to build a machine that pays individuals for demonstrating they've understood the alignment problem" might be useful.
17. 5, 12, 14, 15 and 16 imply that if your goal is to prevent the scaling of dangerous AI, then you should review the work of Krantz.
This is wrong. 16 alone is insufficient; to believe you should review the work of Krantz, you must believe that the expected value of doing this is worthwhile. Anyone can produce "work" which is "aimed at" anything, but that does not guarantee that the work successfully achieves its aim, or even makes useful progress toward its aim. (Consider someone who says they have produced a proof that the earth is flat. Such a proof would be very important if true! But this does not mean that you should review the proof.)
18. If AI safety orgs understood there was an effective function that converts capital into public awareness of existential risk from AI, then they would supply that function with capital.
This is wrong. Simply being "effective" is insufficient; such a function must be sufficiently effective that the expected utility is higher than other possible uses of capital.
@jcb These are great questions and excellent critiques. Thanks!
1. Your right, that it would be stronger and remain valid if I added the property of being unaligned. I feel I could also argue that any self aligning AI is tautologically unaligned to humanity. What I'm trying to share is a mechanistically interpretable way of directly rewarding humans to align it.
I'm trying to pivot the world from machine learning to gofai.
10. What I'm saying is that it's possible to electronically consent to a given proposition being true. If we paid individuals to consent to propositions being true for use in legally binding contracts (think of "I've read and accepted xyz terms and conditions). That data would be valuable. People's explicit opinions are valuable. Especially on "how should a truly decentralized AI (that's supposed to be free and equally beneficial to all of humanity) behave and what beliefs should it have and why?".
It is possible to build a machine that, for all "propositions of truth" can print value according to how valuable society rates that "proposition of truth". It is possible to use blockchain technology to align constitutions.
17. It's a conjunction of all those propositions to imply 17. If someone claimed to have a proof that the world was flat in a hypothetical universe where the krantz mechanism was used as the primary mechanism of intellectual currency (human intelligence), they should stamp that proof on the alignment blockchain where it will be worth tremendous value if cooberated, but worthless if proven false. Other people print currency by proving it false. Blockchaining currency was a big deal. This is blockchaining public opinion..
18. Totally agree this is a more rigorous proposition. If these propositions existed on the sort of decentralized network that I hope exists one day I would have rewarded value to you by cooberating that your revision is in fact better.
The truth is, this prediction is just a subset of what I'd like to get on my demonstration mechanism or my "guess my beliefs question". For example, someone could easily take my liquidity by transferring these exact propositions over to "guess my beliefs" and guessing correctly. Imagine if every analytic philosopher in the world put their best arguments (for how to fairly align society and distribute all this new wealth) online in the public domain and printed IP crypto for doing it. If anyone thinks I'm wrong about something, ideally they should write and argument (with compelling propositions that I accept) that leads me to better consent to understanding why I'm wrong. I'd love to pay for that. I'd bet others would too.
At the end of the day, I want kids in the world to learn how to print their own currency by doing analytic philosophy about what we as humans ought do (in case AI takes all the physical jobs).
Thanks again for engaging positively and charitably!
Re 10: What you said here seems substantially different from the original proposition "It is possible to build a machine that pays individuals for demonstrating they’ve understood something."
What happened to "demonstrating understanding"? I can imagine how, given a set of someone's agreement/disagreement with certain propositions about a topic, a machine might decide whether they understand a topic. If this is what you're referring to, that's not very clear. The discussion of the value of people's opinions doesn't seem to connect to the original proposition 10.
Also, "a machine that pays individuals" has been replaced with "a machine that prints value". Perhaps this is what you meant originally by "pays"--I almost called that out as another point of unclarity in my previous comment, but I thought that this was answered by 18, where a funder, in this case AI safety orgs, would provide the capital to be paid out to individuals.
If indeed your proposition 10 is that the machine "prints value", I think that proposition is quite likely to be "denied" if Eliezer reviews this argument. I think that the possibility of building such a "machine" is not a simple proposition, as it seems to encompass an entire economic/blockchain system, the mechanics of which are not clear. (As far as I understand, this is the whole Krantz Mechanism for which you're advocating? Unfortunately, treating this as a preliminary proposition from which you derive "you should review the work of Krantz" is circular.)
Re 17: Sorry, I was unclear; I meant something like "the implication is not valid, though it might be with a stronger version of 16" (or, I suppose, a weaker version of 17).
Looking at 17 and nearby lines again, I think there are a couple of unneeded dependencies:
17 doesn't depend on 5 at all. 17 assumes "your goal is to prevent the scaling of dangerous AI". So the truth of "we should stop scaling AI" is irrelevant to 17.
I don't think 17 depends on 12 or 14 directly. Instead, I think 15 depends on both of these. (If 12 is false, then 15 does not hold, because you shouldn't focus on building the impossible. If 14 is false, then 15 does not necessarily hold, because building the mechanism won't necessarily help prevent dangerous AI scaling.)
So the simplified 17 is: 15 (If your goal is to prevent the scaling of dangerous AI, then you should be working on building mechanisms that incentivize awareness of the issue) and 16 (Krantz's work is aimed at building a mechanism that incentivizes the demonstration of knowledge) imply that if your goal is to prevent the scaling of dangerous AI, then you should review the work of Krantz.
But this still has the same problem. Clearly[*] 15 and 16 imply that if your goal is to prevent the scaling of dangerous AI, then Krantz's work is aimed at building a mechanism that you should be working on. But it doesn't follow that you should actually review the work of Krantz. What you "should" do depends on whether Krantz's work will actually help you accomplish your goal, which this argument has not demonstrated.
If 16 were stronger, like "16' Krantz's work successfully builds a mechanism that incentivizes the demonstration of knowledge" or "16' Krantz's work makes substantial progress toward a mechanism that incentivizes the demonstration of knowledge", then 15 and 16' would imply 17.
If 17 were weaker, like "17' if your goal is to prevent the scaling of dangerous AI, then the work of Krantz is relevant to your goal" or "17' if your goal is to prevent the scaling of dangerous AI, then the work of Krantz might be useful to you", then 15 and 16 would imply 17'.
But as written now, 15 and 16 do not imply 17.
[*] Technically I'm ignoring the distinction between "incentivize awareness" and "incentivize demonstration of knowledge", but I think this is basically addressable with your other propositions and not a fundamental flaw.
@jcb Sorry, I must have overlooked this response.
Try to think of (10) like a document that read:
By signing the following document cryptographically using your humanity verified signature you are indicating to the public domain that the following is true:
1. You are willfully engaging in a social contract.
2. You intend for this record to be used in a court of law by independent legal representatives to advocate on your behalf.
3. You believe existential risk from AI is real and that the prevention of further scaling is critical to humanity's survival.
4. You support legislature that prevents further scaling of artificial intelligence.
At the end of the day, Eliezer doesn't need millions of people to truly grok his terror. He just needs enough people to sign a petition. Formal support of a petition for action is something that can be queried from a survey if it is designed right.
Also, no money needs to be created. Signatures are intrinsically valuable if there is a demand for them.