
Will Claude 3.5 Haiku be better than Claude 3 Opus?
31
Ṁ100Ṁ4.7kresolved Nov 5
Resolved
NO1H
6H
1D
1W
1M
ALL
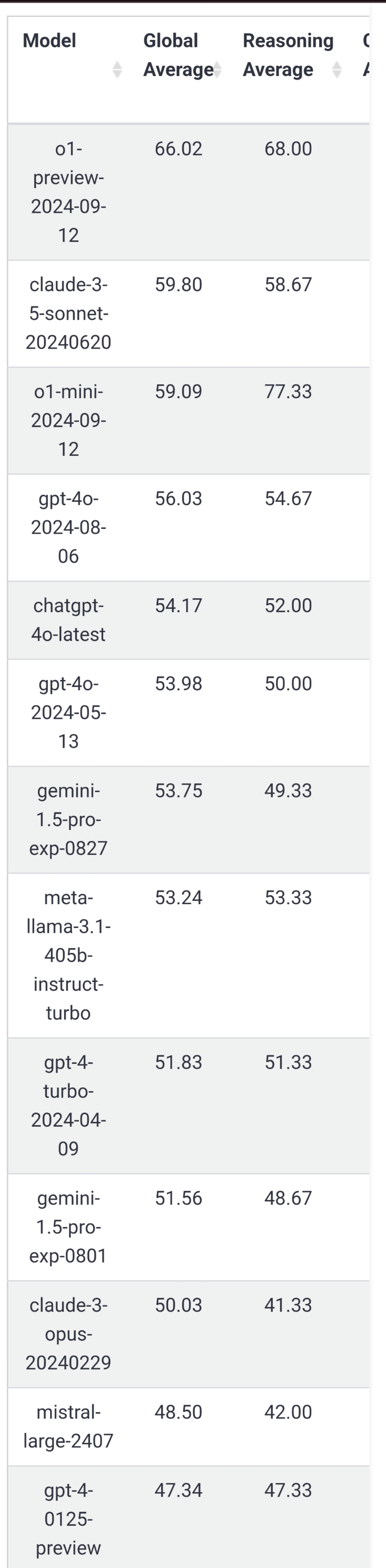
I will resolve it according to the most recent benchmark results from livebench.ai as soon as the results are available.
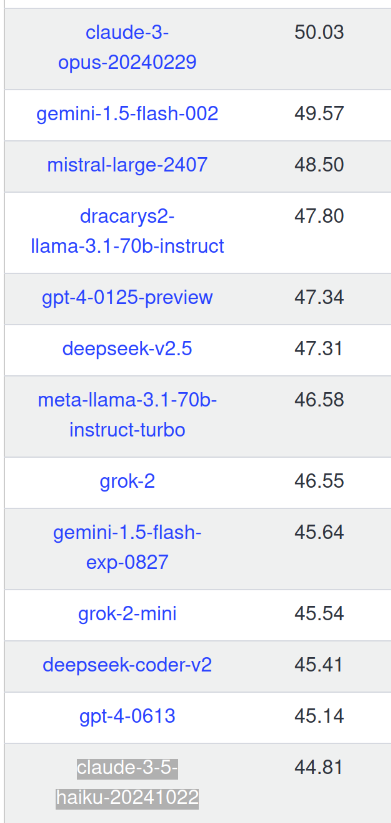
In the current benchmark Claude 3 Opus has a score of 50,03 on the 'Global average', while Claude 3.5 Sonnet scores 59,80.
This question is managed and resolved by Manifold.
Market context
Get  1,000 to start trading!
1,000 to start trading!
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ1,728 | |
| 2 | Ṁ62 | |
| 3 | Ṁ60 | |
| 4 | Ṁ54 | |
| 5 | Ṁ52 |
People are also trading
Sort by:
sold Ṁ55 YES
bought Ṁ30 NO
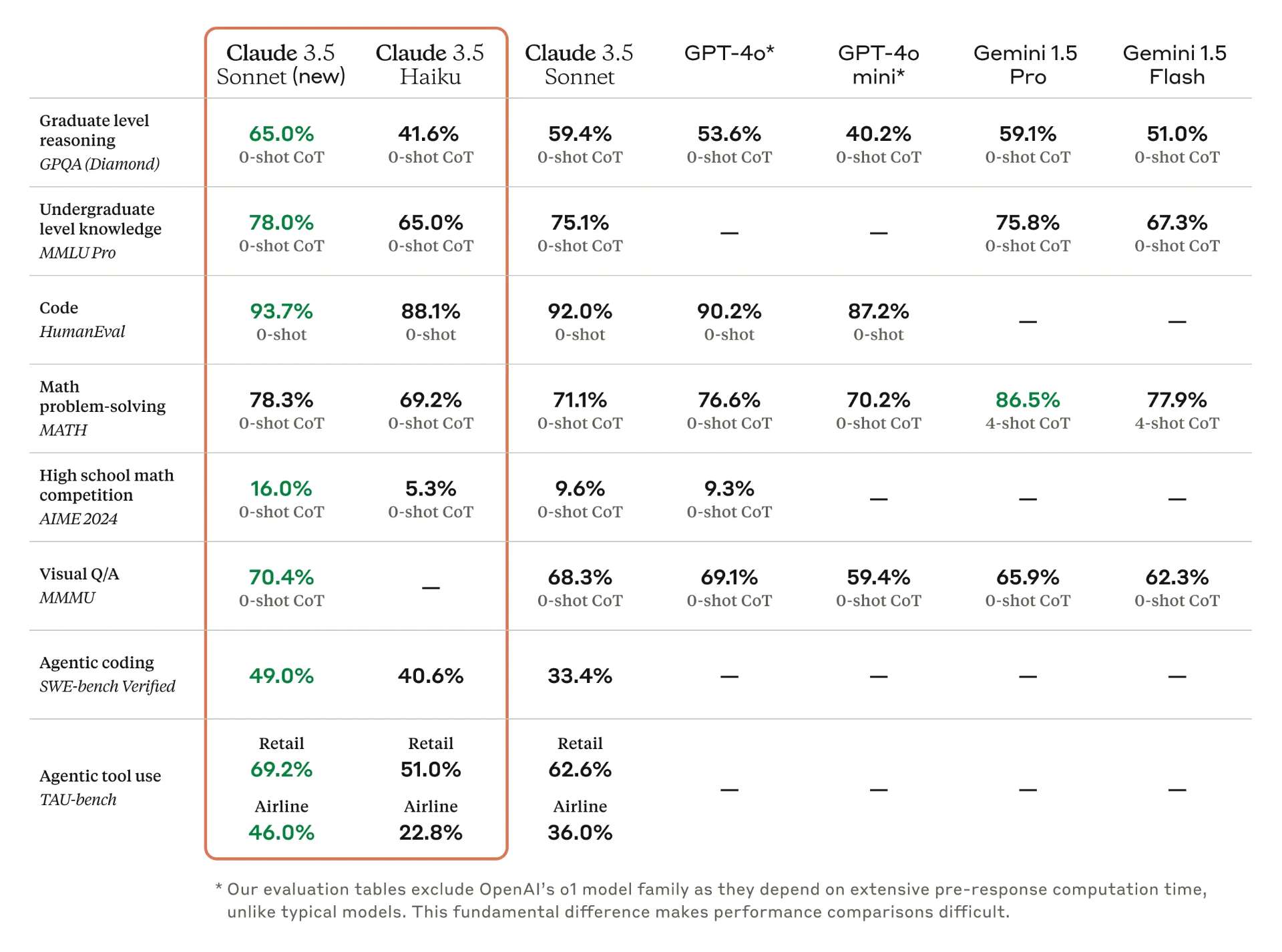
Ya, I'd consider it well below gemini-1.5-flash-002.
The GPQA scores are barely above Claude 3 Sonnet.