Kimi K2 Thinking gets top score on HLE, according to independent evaluation?
20
Ṁ100Ṁ1.3kresolved Feb 2
Resolved
NO1H
6H
1D
1W
1M
ALL
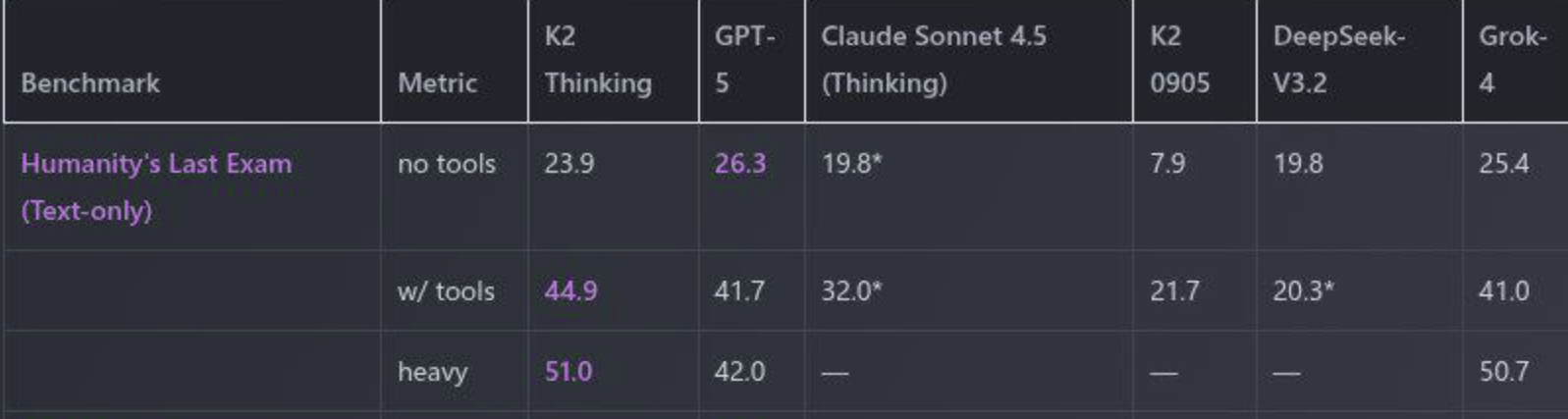
Resolves according to https://scale.com/leaderboard/humanitys_last_exam,
or to https://scale.com/leaderboard/humanitys_last_exam_text_only if only text-only is evaluated.
Context:
This question is managed and resolved by Manifold.
Market context
Get  1,000 to start trading!
1,000 to start trading!
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ40 | |
| 2 | Ṁ38 | |
| 3 | Ṁ37 | |
| 4 | Ṁ28 | |
| 5 | Ṁ28 |
Sort by:
@traders Kimi K2 Thinking just ranked #4 behind GPT-5, GPT-5 Codex, and Grok 4 in an independent run of HLE from Artificial Analysis: https://artificialanalysis.ai/evaluations/humanitys-last-exam
Although it doesn't resolve this market, it is a significant evidence that Kimi K2 Thinking won't top an independent run of HLE from Scale as well.
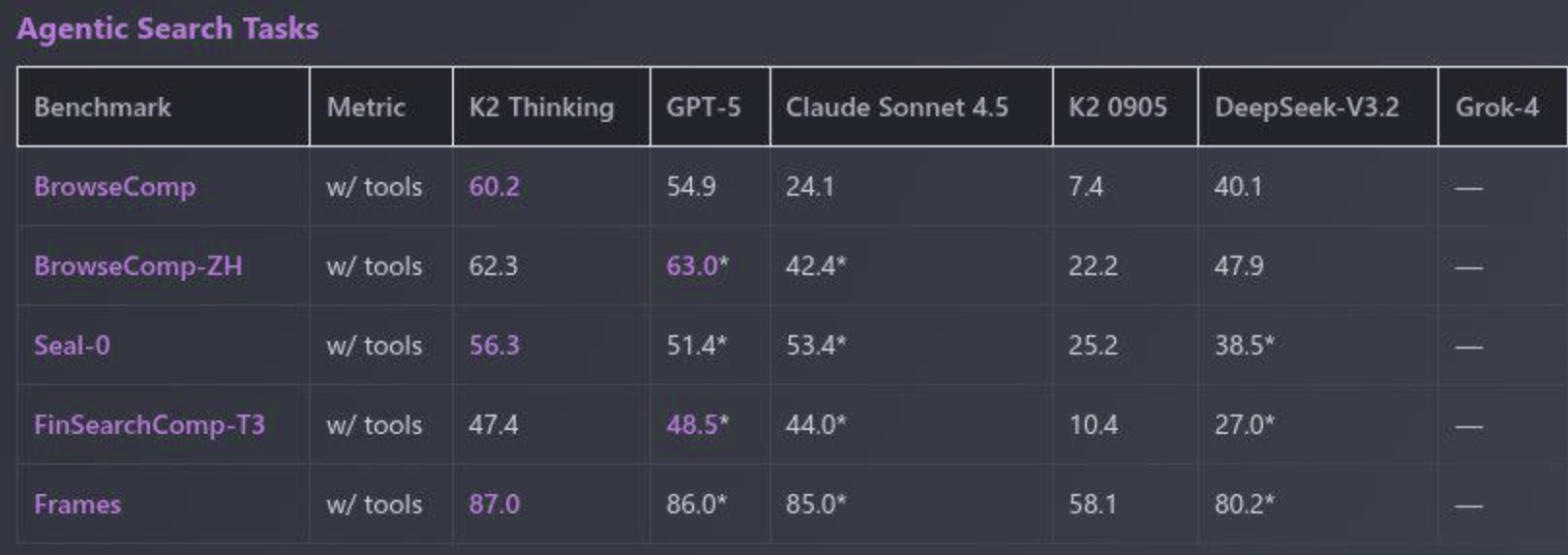
@MikhailDoroshenko do you think k2-thinking is particularly better at internet-based research than the other frontiermodels and that gives it the upper hand on HLE when internet search is allowed?