 1,000
1,000People are also trading

I've gotten confirmation that "superalignment research"—meaning the alignment of models significantly more capable than current models—is continuing at OpenAI; it is unclear if the original goal—"to build a roughly human-level automated alignment researcher"—is still in force, but I'm pretty sure that both scalable oversight and adversarial testing will continue. Currently leaning towards resolving this yes
@AndrewG I think one could also make a case for resolving it N/A or resolving it at 50% (or 60%) if it‘s not a clear yes? Arguably the intent of a question like this was getting a grasp of the automating alignment research project, that‘s where the term “superalignment“ itself came from. Scalable oversight and adversarial testing are important parts of this project, but aren‘t equal.
If “automating alignment research by 2027“ is unclear, as of right now, I‘d argue for N/A. That‘s usually what one would do in an unclear case?
(It would go against the intent of the question, at least as I view it, if this market would resolve YES and then at some later point we found out that “automating alignment research“ did actually not happen in June.)
(Edit: I‘m also happy with YES if you have inside info on this and superalignment, as it was originally meant, is still in force. I wouldn‘t complain. I just personally do not know this, as of now.)
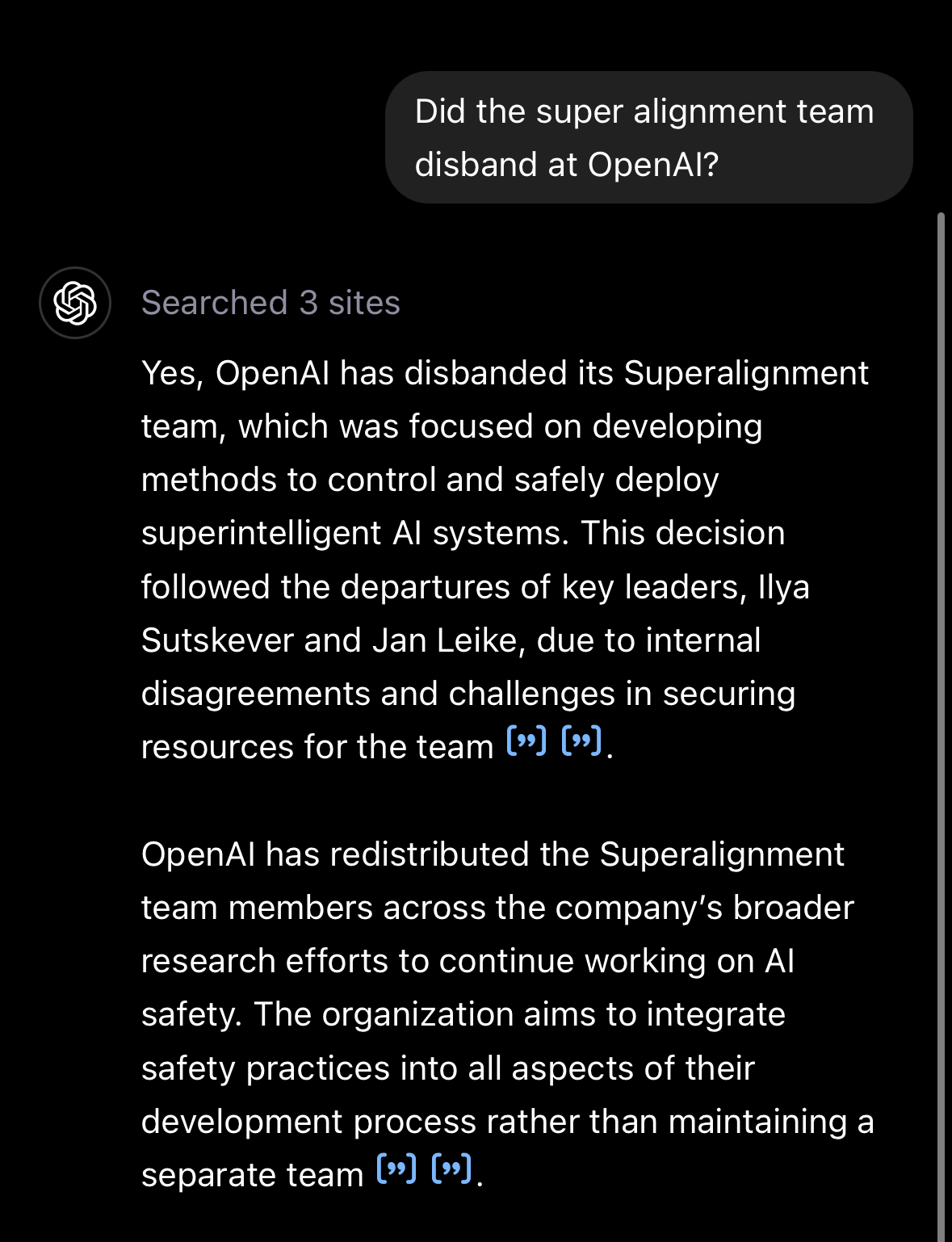
@0xSMW This is what caused the market to tank to begin with, the latest rise was reporting that superalignment work will continue under Schulman.
@AndrewG can you clarify your resolution criteria for us? This is where I'm at too, but there is some ambiguity.
@AndrewG +1 on resolve criteria, please, especially given that half the reason we're in this mess at all is that OpenAI straight-up lied about fulfilling their promise about Superalignment: https://thezvi.substack.com/p/openai-fallout
Axios is reporting on a yet-to-be-released OpenAI blog post that says superalignment work is continuing: https://www.axios.com/2024/05/28/openai-safety-new-model