

 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ156 | |
| 2 | Ṁ134 | |
| 3 | Ṁ117 | |
| 4 | Ṁ93 | |
| 5 | Ṁ92 |
People are also trading
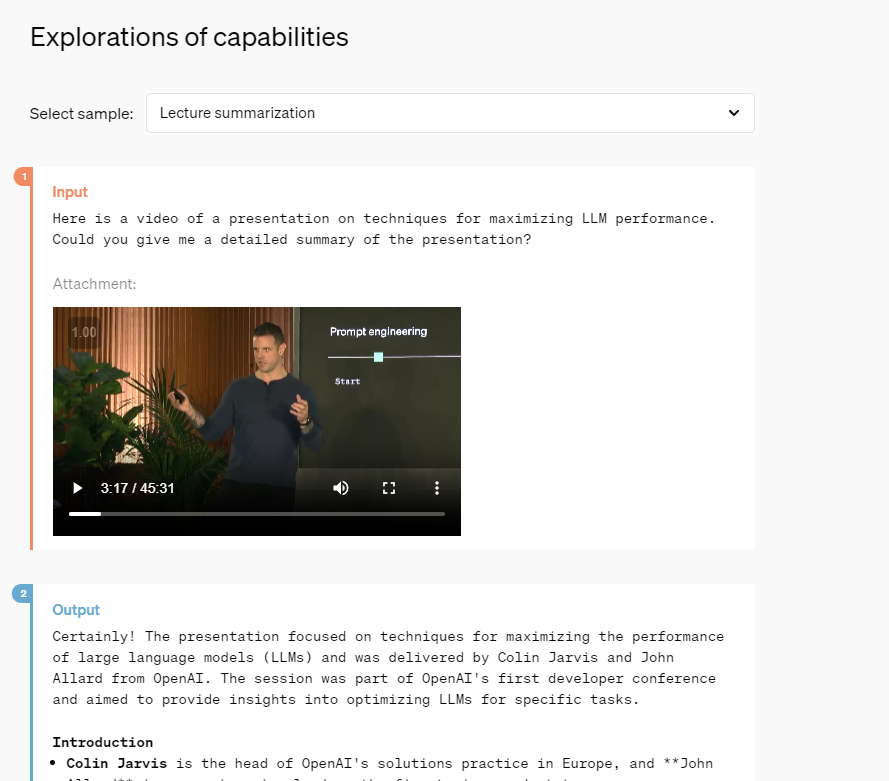
@RaulCavalcante Wow could you send the link to where you got this from. Video input appears certain then
@Ricky30235 can someone NA this because i get what youre saying but other ppl seemed to interpret it differently , it was pretty vague @shankypanky
@strutheo hm - is there argument about this one? it has the ability to use the camera but as Ricky says that's not what video input means. are there traders who say otherwise?
@shankypanky I really think it matters what is being done with that camera feed. Is it pulling occasional frames and processing them as single images? Or is it keeping history over time, like one would with video?
In the demo, if he had scanned the camera over the equation, instead of framing the whole thing, and it still got the equation, that I would take to mean it's processing video. We didn't get that in the demo so it's ambiguous. It will be easy enough to clear up once someone gets access though.
@robm I'd argue that's not ambiguous for the purpose of a market announcing a feature, though. as it was presented and demonstrated, there was no use case for saving and processing video, no mention of keeping video history over time, etc.
@shankypanky I'm most curious what the model is doing under the hood. Does it accept videos as direct input? Taking in .mp4s would be clear evidence, this phone camera stuff, IDK.
@ErikBjareholt No i believe his demo fits with “Streaming video understanding”, which was resolved yes, but “video input” would be if I give it a video file and ask it questions
@Ricky30235 That is just a matter of UI. The model itself clearly shows it can be given a captured video and answer questions about the footage (as they did with the waving woman in the background). The streaming is just a bonus.
As soon as the API becomes public this should become clear.
it accepts as input any combination of text, audio, and image and generates any combination of text, audio, and image outputs
On the announcement blog linked from that tweet. If it was native video, I think their marketing department would have made sure to say 'video' there.
(BTW I'm not deadset on this either way, genuinely just curious how this will resolve)
@robm yeah I was just sharing the tweet because you said you were curious to know more - the market is framed as "what will be announced during the livestream" so I'm not sure how people were betting based on that. the demo seemed to be from voice/image/video recognition but I'm not sure that qualifies as video input.
of course, people could also read it as "can I input video in some way to the tool" which you can with live video. so that's also a matter of interpretation.
@strutheo I believe this would be more likely to resolve yes if “Streaming video understanding” was not a separate option, but it was and clearly resolves to yes. “Video input” I thus think is not met since the separate option existed to interpret it that way
@ErikBjareholt You can imagine streaming video resolving to no and video input resolving to yes if you could drop a video file, but couldn’t use the live camera. So when you invert, you get today’s announced capabilities

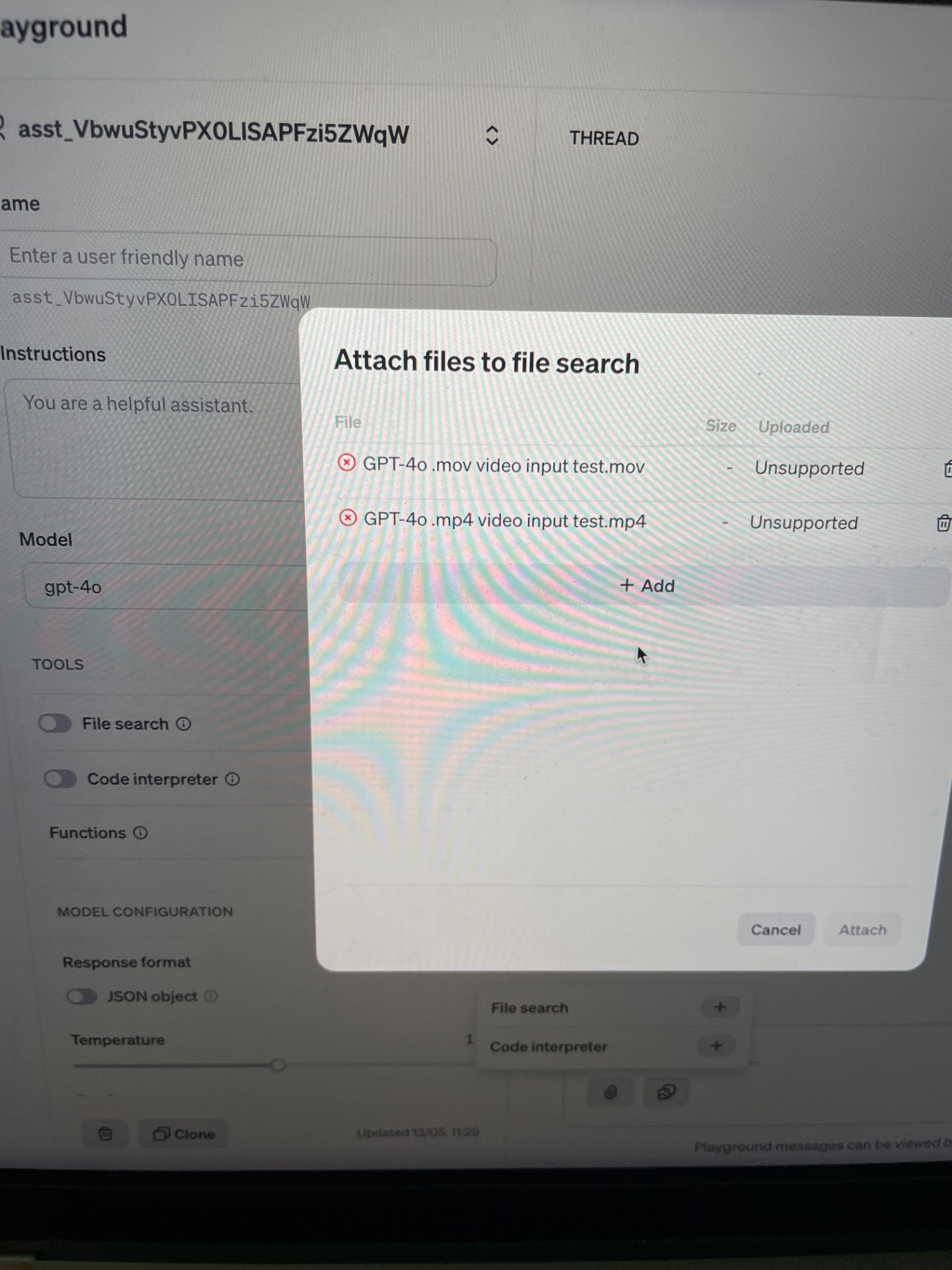
@Ricky30235 Hmm, you might be right. Altman says "video"
https://twitter.com/sama/status/1790069224171348344
but the model page says "text or image and outputting text":
https://platform.openai.com/docs/models/continuous-model-upgrades
So it's possible the phone app just took a screenshot and the model can request screenshots. But it isn't receiving an entire video clip.
@Ricky30235 That's not proof. You do not have full access:
> We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
@ErikBjareholt Oh yes you might be right about the rolling out, however @Mira above showed the model page saying inputs are text or image. They would say video if there was video input

@Ricky30235 If their own docs are explicitly stating text and image inputs but not “video input” I feel that settles it
@Ricky30235 No they wouldn't, just as they don't with audio, because you are reading the API docs and the modality isn't offered yet, but the capability is clearly demonstrated.
@Mira https://openai.com/index/hello-gpt-4o/
GPT-4o (“o” for “omni”) is a step towards much more natural human-computer interaction—it accepts as input any combination of text, audio, and image and generates any combination of text, audio, and image outputs.It has audio and can "reason over video" if the app takes still images. But there's no explicit claim that the model supports video input. Just the associated app. They would've mentioned that, since it doesn't come for free.
@Ricky30235 If they announced video input anywhere, it should still count even if it's not in the API. But I don't see them claiming video input, so no announcement until someone finds a reference. Even if later the actual model has video input, it needs to be "announced today" so someone needs to find a clear reference to video input today.
@robm Update all, it’s definitely yes. I just got access to gpt-4o in ChatGPT and it accepted the video as input (regardless if the answer is not very good)

@Mira Do you think what I showed counts? It appears video input is accepted in ChatGPT-4o and was announced today, which would meet the criterion, right?
@Ricky30235 That doesn't prove video input for the model. But I guess the market says "video input" for some unspecified thing. So even a random unrelated app that doesn't even use an LLM could count...