
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ16 |
@ViorelPETCUVorL
Quote:
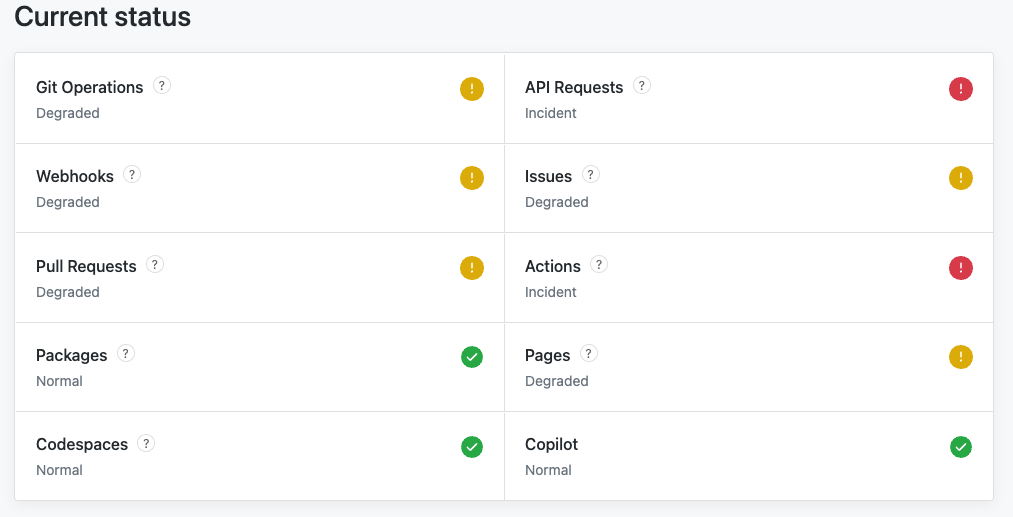
"On January 9 between 12:45 and 13:56 UTC, services in one of our three sites experienced elevated latency for connections. This led to a sustained period of timed out requests across a number of services, including but not limited to our git backend. First, those requests that eventually timed out were starving out other requests from executing, leading to broader failed requests. Second, the git backend services are critical dependencies of many GitHub features, which led to broader impact to other jobs and requests. An average of 5% and max of 10% of requests failed with a 5xx response or timed out during this period. We are actively working to identify all contributing factors of this incident, including opportunities to improve resiliency across all impacted services."
According to this statement, looks like "Infrastructure not scaling" is the resolve of this question.
" ... three sites experienced elevated latency for connections ... "
The infrastructure on these sites was not scaling to meet the demand.
@ViorelPETCUVorL "Elevated latency" could have any number of causes, seems like this should be unknown.

@npt https://www.githubstatus.com/incidents/pxg3dz4yg7lp
I don't agree, the solution was to increase limits ( if you reread the incident resolution updates )