
This market is inspired by a market originally by @VictorLevoso; Will a non-crappy video equivalent of dall-e be published before June 2023?
So first off, buyer beware as this market, much like the inspiration market, may be up to interpretation and does not abide by best practices of it being something mapable by a third-party, quantitative metric with a threshold, but rather by the market maker's interpretation of evidence provided in the comments.
Recently, a paper came out from OpenAI researches called Shap-E, which is a 3D object generator. From the paper, Shap-E is an improvement over a previous model called Point-E. Whereas Point-E modeled point clouds, Shap-E uses something called Neural Radiance Fields (NeRF) which represents a scene as an implicit function.
An implicit function is a mathematical function that involves variables implicitly, as opposed to explicitly having a relationship, as is the case in an explicit function. Whereas in this function:
y = x^2y is explicitly a function of x. Whereas in the function:
x^2 + y^2 = 1x and y have an implicit relationship.
Point-E used an explicit generative model over point clouds to generate 3D assets, unlike Shap-E which directly generates the parameters of implicit functions. So in rendering a 3D object, Point-E uses a Gaussian Diffusion process was used to mimic how a light source illuminates a scene.
Noising Process: q(xt∣xt−1):=N(xt; sqrt(1−βtxt−1),βtI)
the state xt at time t is generated from the state xt−1 at the previous time step. The state xt is a noisy version of xt−1, where the noise is Gaussian with mean sqrt(1−βtxt−1) and covariance βtI. The parameter βt determines the amount of noise added at each time step.
Where:
xt=sqrt(αˉt)x0 + sqrt(1−αˉt)ϵ, where ϵ is a Gaussian random variable which explicitly defines xt, and αˉt is a noise parameter βt up to time t.
So what they did is reversed the above Noising Process, q(xt−1∣xt), using a neural network, pθ(xt−1∣xt), setting the goal of learning the paremeters θ of the neural network so that it can accurately reverse the noising process. So as a result, Point-E was able to generate images which are very detailed like the following:

Contrast this to Shap-E, which implicitly maps an input pair with :
FΘ : (x,d) ↦ (c,σ)
The given equation, Neural Radiance Field (NeRF), defines a function FΘ that maps an input pair (x,d) to an output pair (c,σ).
x is a 3D spatial coordinate. This could represent a point in a 3D scene or a 3D model.
d is a 3D viewing direction. This could represent the direction from which x is being viewed, such as the direction from a camera to x.
c is an RGB color. This is the color that the function computes for the point x when viewed from the direction d.
σ is a non-negative density value. This could represent the density of a volume at the point x, which could affect how light interacts with the point and thus influence the computed color.
The function FΘ takes a spatial coordinate and a viewing direction as input and computes a color and a density as output. The exact way in which it computes the color and density would be determined by the parameters Θ. So with that mathematical background understood, Shap-E was trained in two stages:
An encoder was trained to map a bunch of 3D assets into the parameters of this above implicit function (as well as another one which I won't go into here) which takes viewing direction as input and color and density as output.
A Conditional Diffusion Model was trained on the outputs of the encoder. A Conditional Diffusion Model is like a Guassian Diffusion Model used in PointE above, but conditioned on text-based descriptions of the original training images.
Coherency was evidently given priority over diversity of samples.
Shap-E was able to generate images which were, "pleasing" and did not skip out on parts of the model as opposed to Point-E, like the following:

I was able to render an image of a dog with a HuggingFace demo:
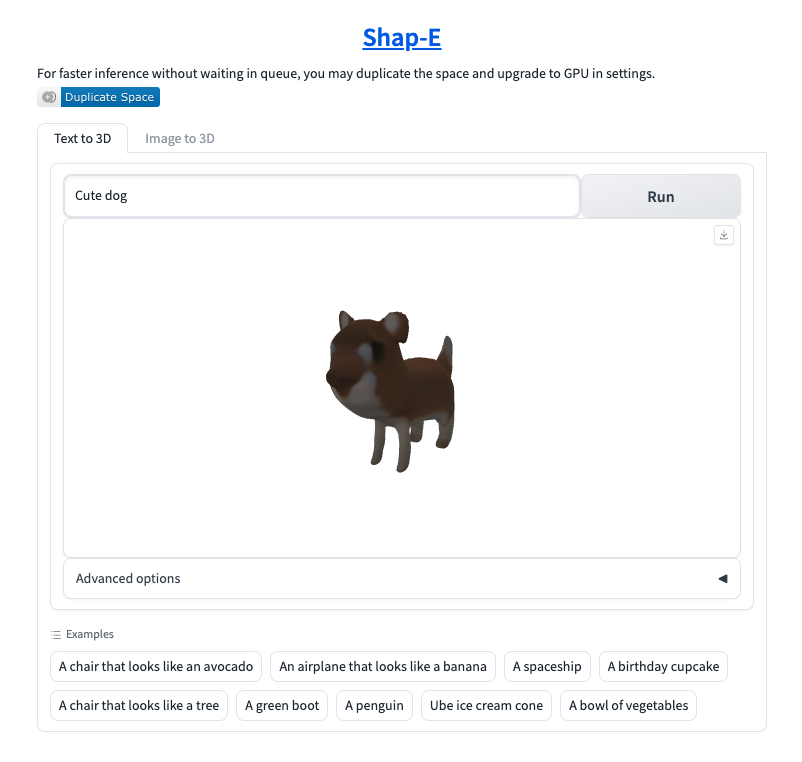
and I was able to successfully convert this into a GLTF file:

So here's the tricky part. While this does seem to be an interesting approach, the value of Dall-E and other generative AI seems to be in part the capability to create, "whatever," but you don't seem to be able to do that with Shap-E, it creates all sorts of mistakes, e.g.:.
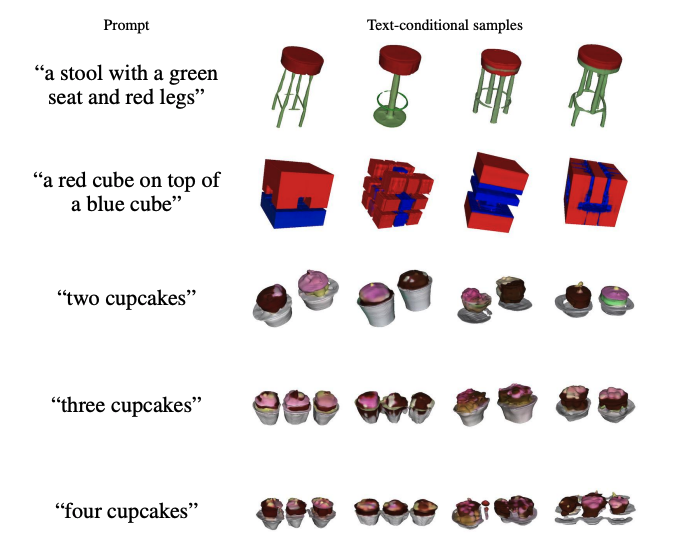
The resulting samples also seem to look rough or lack fine details.
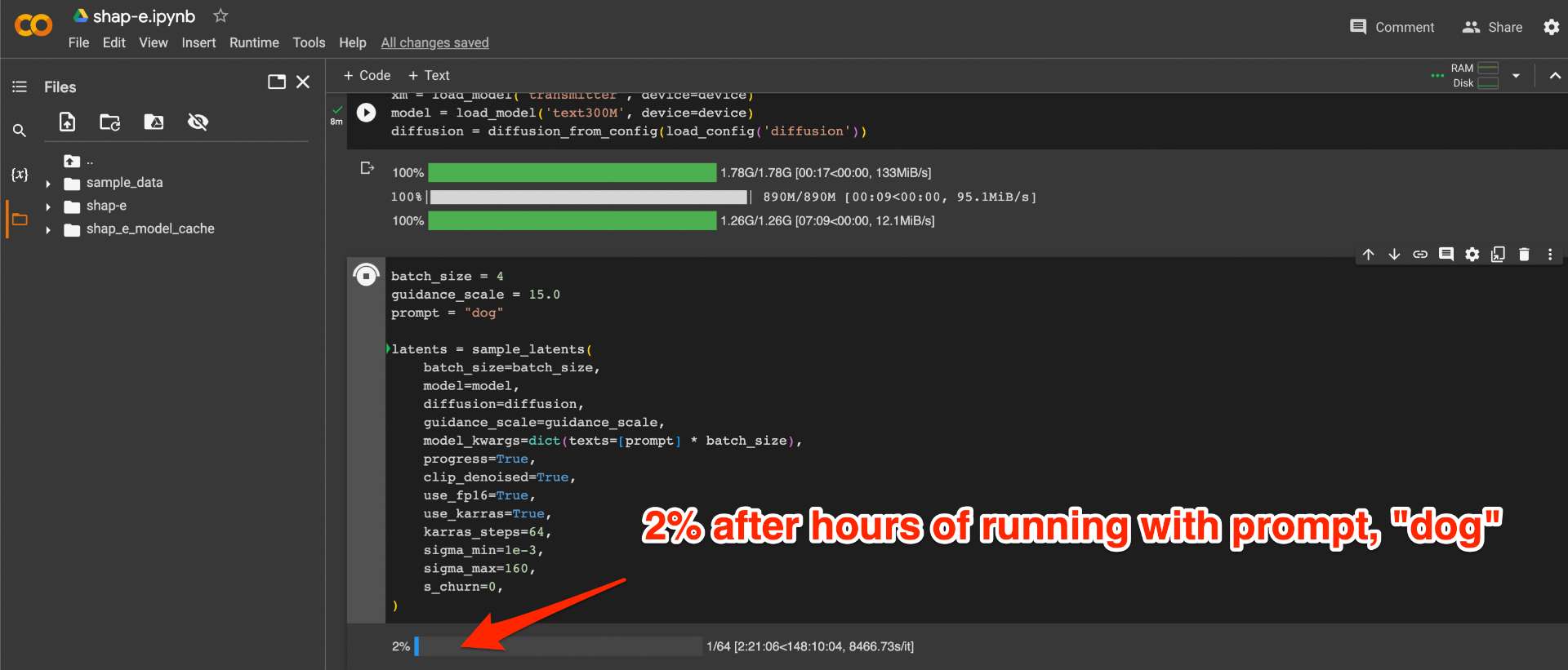
Further, this is not covered in the paper, but the architecture seems to be super resource heavy as far as I can tell, I tried to run it in a Colab notebook and it took forever, so this might not be, "cheap."
MARKET RESOLUTION
We will use the resolution criteria outlined in the above sourced Dall-e for video market ending at the end of May 2023 as a precedent.
Note - this resolved NO.
Here was the reasoning given:

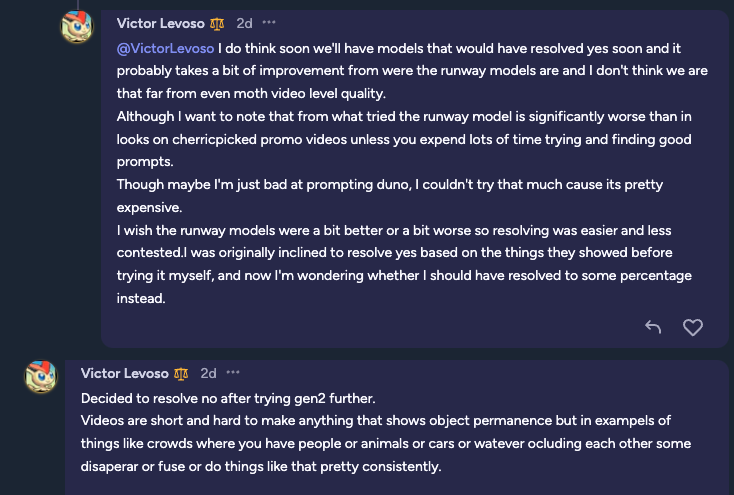
So extrapolating that out and rather than saying, "object permanance," we might say, "object congruence." E.g. if models of a wide variety of non-cherry picked random topics have significant parts cut-off or surfaces that are not congruent, this would resolve as NO.
We can't use cherrypicked promo images.
If a sufficient quantity of generated models is poor, this will resolve as NO. We won't do a 50% resolution, unless it's clearly and unequivocably 80% of models being generated congruently.
Random sampling of objects to be generated must be sufficiently large.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ164 | |
| 2 | Ṁ152 | |
| 3 | Ṁ88 | |
| 4 | Ṁ87 | |
| 5 | Ṁ67 |
People are also trading
@PatrickDelaney Have you already looked at the big commercial models? (e.g. https://3d.csm.ai/ and https://hyperhuman.deemos.com/rodin)
@PatrickDelaney given the lack of new comments, perhaps you could resolve this now—so people can have their locked-up mana.
I have gotten some questions regarding whether demos will count for the purposes of resolving this market. I created this market a long time ago and so I can only go back and look at what I wrote then.
It looks like for this market I had actually ran the code, which is true, I recall doing, in Google Colab. I would say that at a minimum, someone in this market or related, a third party, has to be able to run this code. We're not going to rely on just research groups and corporate or academic groups publishing things claiming that, "they did it!" This is far too open to bullshit.
We need someone, ideally myself or someone on this market, who is able to run the stated code.
One question came up regarding whether, "images of this quality, assuming they are not cherry picked promo images," would be good enough?
https://github.com/Alpha-VLLM/Lumina-T2X?tab=readme-ov-file#text-to-3d-generation
I would say that, yes, presuming they are not cherry-picked, we could call them good enough to resolve as YES or at least above 50%. That being said, we likely need to go back and see what range Dall-E was able to give in terms of total potential things it could output, and compare to whatever is reasonable for a 3D version. For example, in the 3d generator in the source description, there was a pretty narrow range of things that you could generate based upon the training data. So does this really constitute, "a 3D version of Dall-E?" Difficult to defend that statement, because Dall-E was able to generate a huge number of different types of images, though I'm not sure what that number was.
Related market that resolves on Monday: https://manifold.markets/SarM/will-openai-announce-a-textto3d-mod
Another text-to-3d generator, this time from NVIDIA: https://research.nvidia.com/labs/toronto-ai/LATTE3D/
Only demos, there's no code available or an ability to generate your own models.
@IvanKb7b4 @PatrickDelaney Did we already get a resolution on MVDream?
https://research.nvidia.com/labs/toronto-ai/LATTE3D/images/paper_screenshots/df_quant.png
https://github.com/bytedance/MVDream
The models are pretty high quality, it's just obnoxiously slow for the best quality.
@LoganZoellner thank you for the link! Apparently, the 3d version of MVDream is https://github.com/bytedance/MVDream-threestudio and it requires an A100 GPU to run. I will try using vast.ai to test it. Will report back.
@IvanKb7b4 I was able to run their code to generate a model with their example query "an astronaut riding a horse". The 2D images from different angles of the generated model looked okay, but the exported .obj model is very bad (a screenshot from a 3d viewer is attached).
It's possible that the issue is their implementation of marching cubes or whatever they use to convert NeRF into 3d models, but the current state of things: it's a crappy text prompt -> 3d model generator.
But I have to admit that their rendered images look good. So, I am split about whether this is enough or not enough to resolve the market.
Thanks again for posting links to the generators - it's very interesting to follow.

@IvanKb7b4 Presumably there's some knob you can turn that increases the resolution of the mesh at the cost of dramatically more inference time.
I've gotten good results using dreamcraft3d (also in 3d studio) in the past but it basically had to run overnight on my computer.
@LoganZoellner it's possible but their docs don't give a hint about these knobs. I only had a very limited time to evaluate.
Your results in dreamcraft3d indeed look better, but it's still clear it's a model from a generator, not from an artist, given the obvious artifacts, especially around the face.
Hate to keep posting the same question, but I have genuinely no insight into how the author intends to resolve this market.
Does this count as non-crappy?
https://github.com/Alpha-VLLM/Lumina-T2X

@LoganZoellner Thank you for posting links to relevant works. This is helpful (I mean it).
I've taken a look and it appears that Lumina-T2X only released their text-to-image model, see the lumina_t2i directory in the sources. The text-to-3d is nowhere to be found, they just claim to have it.
With no ability to test their text-to-3d, either local or via a web UI, we can only rely on their promo images, and the description of the market says: "We can't use cherrypicked promo images".
@LoganZoellner this would be a question to the market creator, @PatrickDelaney.
Personally, I stopped trusting any demos a long time ago. If I can't run something, it does not exist to me.
Again asking, does this count as non-crappy? https://nju-3dv.github.io/projects/STAG4D/

How high is the bar here?
@LoganZoellner thank you for the link to the paper.
It's unclear to me how much of the examples are cherry-picked and most importantly, which of the examples are 3d extensions of existing 2d images, which could be out of scope for this bet. It will become easier to judge when they either release the code (promised) or provide a service that can generate 3d objects from a prompt.
That said, results give enough hope that this bet could be resolved positively, so I sold my "NO" shares. :)
@IvanKb7b4 So, the code is released ([1]) and from what I can see, it is not really generating much. As an input, it already takes multi-view videos and then uses gaussian splatting to train 4D model to render more views at different angles and times.
This is not a prompt -> 3D model at all.
Examples of inputs can be found in their dataset ([2]).
There's a new development, Lightplane: https://lightplane.github.io/
To me, the results still look crappy, but I would like to leave the link, so that others can decide for themselves.

Does DreamGaussian count as non-crappy?
https://dreamgaussian.github.io/
How high exactly is the bar here?
I will not bet in this market. This is not an attempt to sway the market either way, this is simply some independent research I am doing as the market creator to try to figure out how things have changed since this market was created.
I wrote up this article, which is essentially an echo of my research above.
Someone pointed out to me a startup that exists which appears to be creating, "better" 3D objects but of limited scope.
Read into that what you will, I have no idea how this will resolve yet.
https://patdel.substack.com/i/122494972/bonus-material-not-included-on-linkedin-newsletter
