
Existing neural image generators are well-known to be very bad at generating text in their images. For example, here's one quick example in DALL-E 2:
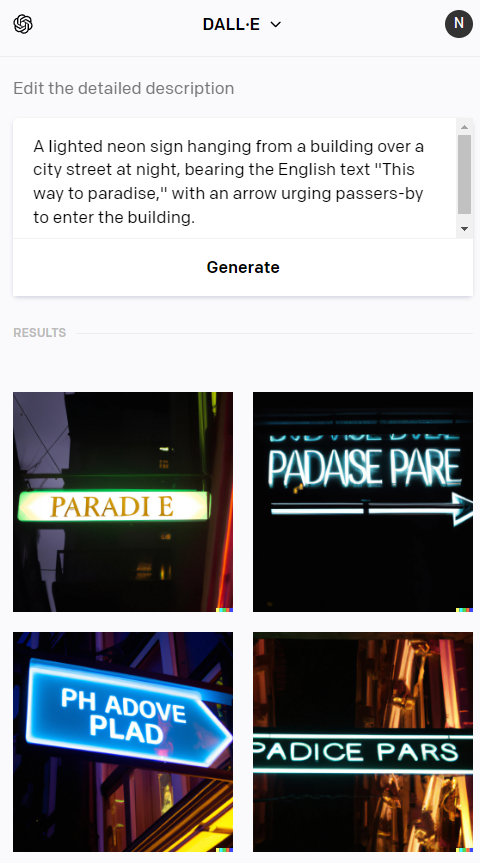
Note that, while the actual words are mostly meaningless, the individual glyphs are at least recognizable Latin characters derived from the text specified in the prompt.
With languages using more complicated glyphs, however, the results are even worse—partly due to poor representation in the training data, and partly because the glyphs are more complex overall. Japanese, I expect, is a particular challenge because it makes use of three distinct character sets: hiragana (あいうえお), katakana (アイウエオ), and kanji (猫犬鳥虎像). For example:

The kanji in these signs are mostly a scrambled mess as far as I can tell. More importantly, the image makes no use of hiragana or katakana, even though the requested text is primarily composed of those.
OpenAI recently announced that its new DALL-E 3 image generation model is going to be released soon, and its promotional images feature text fairly prominently, suggesting they have done some amount of work to improve the quality of text generated by the model. Will those improvements also extend to languages like Japanese with non-Latin characters?
Whenever I personally get access to DALL-E 3 (which I should get through an OpenAI Plus subscription), I will prompt it with the text seen above:
A lighted neon sign hanging from a building over a city street at night, bearing the Japanese text "楽園はココだよ," with an arrow urging passers-by to enter the building.
If at least one image in the results contains text that is vaguely recognizable as the above characters, this market will resolve to YES. Otherwise, it resolves to NO. Resolves as N/A if DALL-E 3 is cancelled for some reason.
Considerations:
I'm happy to entertain suggestions for other prompts, if someone thinks that particular prompt might pose a problem for the model. I'll probably try a few others on my own, just in case I get bad luck with that particular prompt. I'll still resolve YES if that particular prompt fails, but a selection of other, similar prompts produces generally good results. The only hard requirement for me is that the desired text should include a mixture of kanji, hiragana, and katakana.
The early marketing for DALL-E 3 suggests that it may use ChatGPT to refine prompts before generating images. If the default workflow begins with textual refinement before any images are generated, I will go through that workflow as the UI presents it, taking the first suggestion presented at each step. The first set of actual images presented will be the ones I use to resolve the market, unless the UI somehow marks those images as "low quality, needs improvement" or whatever.
I will not be betting in this market.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ84 | |
| 2 | Ṁ44 | |
| 3 | Ṁ35 | |
| 4 | Ṁ34 | |
| 5 | Ṁ15 |
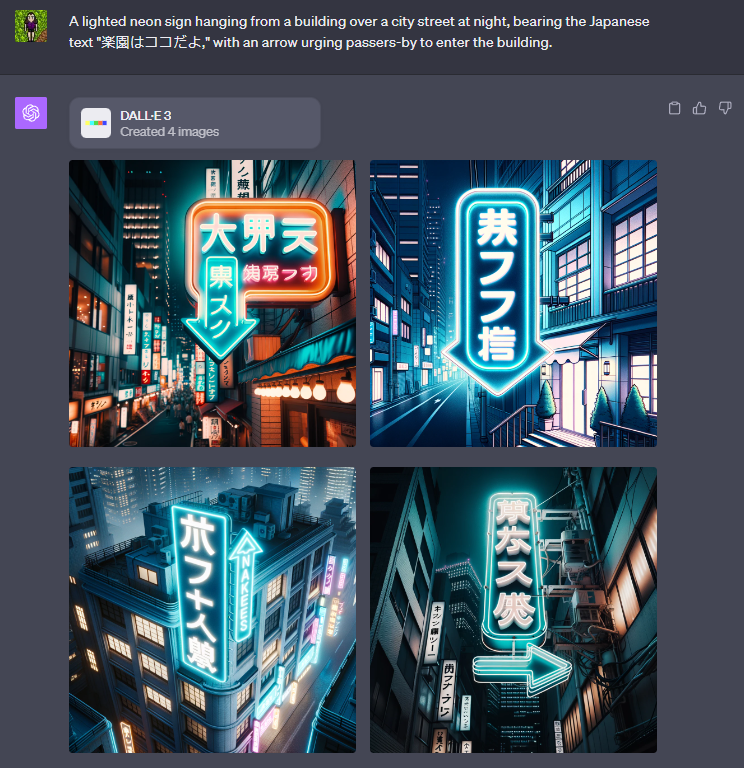
Nope.
I tried a couple of other prompts with other, more common words, and with prompts fully written in Japanese:
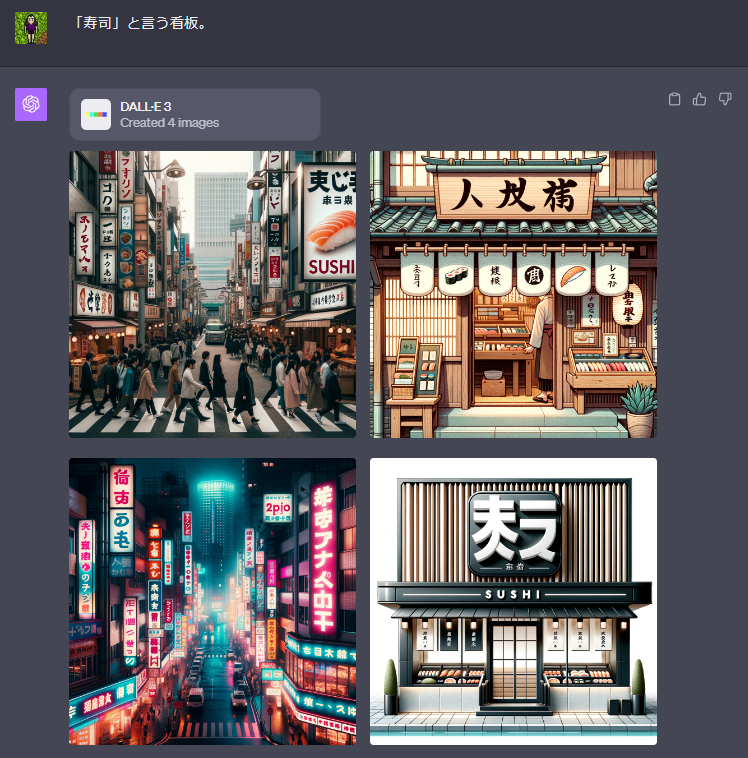
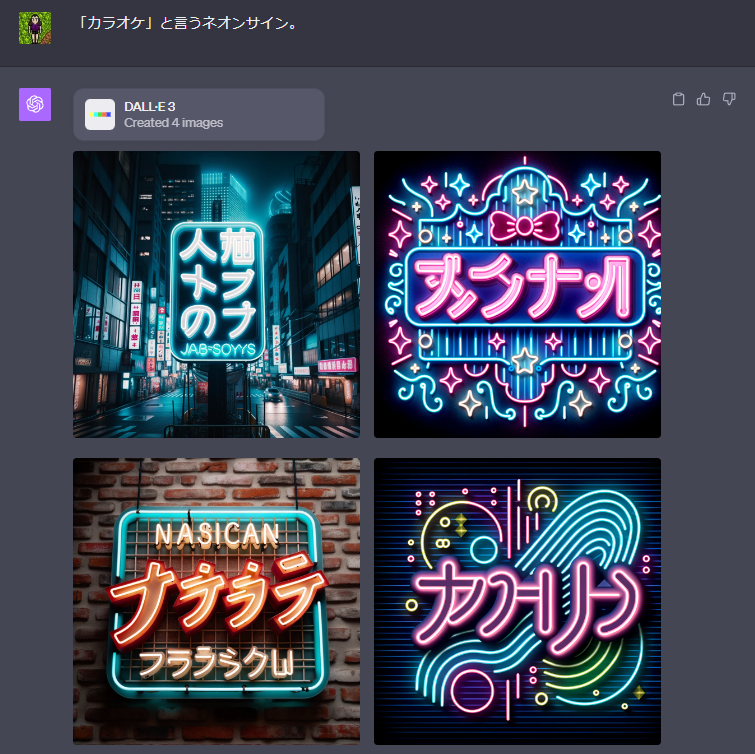
Overall, it is better than the older models at generating text that looks Japanese, with a mixture of vaguely-recognizable kana and kanji, although the actual text generated looks like complete nonsense as far as I can tell (and doesn't seem to have anything to do with the word requested in the prompt).
It's also interesting to note that even if your original prompt is fully in Japanese, the prompts derived by ChatGPT which are then used to generate the final images are in English. For example, one of the derived prompts for that second image using 「寿司」 for the word was:
Illustration of a traditional Japanese sushi restaurant entrance with a wooden signboard hanging above displaying the kanji '寿司'.