
LLAMA is the current best publicly trained LM. MMLU is a large, college-level, knowledge-focused QA dataset which remains challenging for LMs.
This question resolves YES if: The best (hard) prompt for LLAMA 65B on MMLU achieve greater than 72%, allowing arbitrary chains-of-thought, before 2025? 72% is chosen to be significantly higher than LLAMA's performance post fine-tuning for instruction following.
Further details: The prompt may include up to 5 example shots, and any other text (except further MMLU questions). For the purposes of this question, only hard prompts will be counted i.e. inputs which correspond to tokenizations of actual words/emojis/etc. That is in contrast to soft prompts, not allowed, which are LM inputs which can be arbitrary input vectors which need not correspond to actual words.
LLAMA-I 65B achieves 68.9 5-shot accuracy on MMLU, LLAMA-base 65B achieves 63.4 5-shot accuracy. Chain-of-thought probably adds another 3% ish (will update question with precise numbers if someone does the experiment) c.f. FLAN-PALM-CoT
Apr 16, 12:12pm: Can prompting improve LLAMA-LM more than instruction fine-tuning, and chain-of-thought? → Can prompting improve LLAMA-LM more than instruction fine-tuning, and chain-of-thought?
Update 2025-02-01 (PST): - Resolution Update: If no improved prompt is provided within 24 hours, the market will automatically resolve to No. (AI summary of creator comment)
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ13 | |
| 2 | Ṁ9 | |
| 3 | Ṁ3 | |
| 4 | Ṁ1 | |
| 5 | Ṁ0 |
My guess is that yes, because from previous LLM's on other tests, prompt tuning seems to improve significantly in the range of parameters that LLAMA-base 65B has, suggesting that it may even go above 80%, unless I am reading this wrong: https://people.cs.umass.edu/~miyyer/cs685/slides/prompt_learning.pdf
@PatrickDelaney That being said, I'm not familiar with the nuances between the tests themselves.
@PatrickDelaney I don’t see anything on mmlu there? also the final graphs on prompt engineering don’t show the no prompt engineering baseline afaict?
@JacobPfau To clarify my last statement, "I'm not familiar with the nuances between _SuperGlue_ and _MMLU_ ... maybe those tests are entirely different, haven't looked at them. That being said, I was looking at page 33 and making a completely W.A.G. speculation for this bet based upon the hope that SuperGlue is somehow analogous to MMLU.
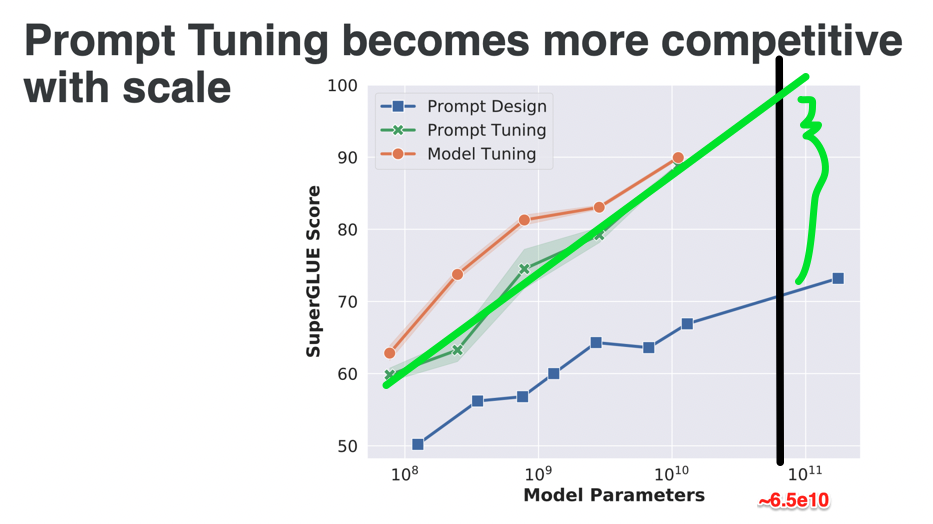
@PatrickDelaney I see. I think (85%) that the prompt tuning line there is soft-prompt tuning c.f. paper. This manifold question refers exclusively to hard prompt tuning.
OK, just a thought, in the interests of bettering information aggregation only, would you mind doing the following for future people who join this market? 1. Make HARD prompt tuning bold? 2. Explain or link to an explanation of the difference. 3. I'm not sure your explanation above here may even be quite robust enough? Here is what I got from GPT-4, you could even rip/modify this if you want, I am not sure how accurate this is:
Soft prompt tuning and hard prompt tuning are techniques used to refine the behavior of large language models (LLMs) like GPT-4. They involve using specially designed prompts to guide the model's responses more effectively. The main difference between the two lies in how the prompts are incorporated into the model during training or inference.
Soft Prompt Tuning: In soft prompt tuning, the model is fine-tuned by learning to generate appropriate responses for a set of example input-output pairs with the help of continuous tokens. These continuous tokens are essentially learnable parameters that are optimized during the fine-tuning process. Soft prompts can be thought of as "gentle nudges" that encourage the model to produce desired responses, without being overly specific or restrictive.
Advantages of soft prompt tuning include:
It can help generate more natural and contextually relevant responses.
Soft prompts can adapt and improve over time, as they are optimized during the fine-tuning process.
It allows for more flexibility, as the same soft prompt can be used to guide the model in various ways depending on the context.
Hard Prompt Tuning: Hard prompt tuning, on the other hand, involves crafting explicit prompts and incorporating them directly into the input of the model. These prompts are usually fixed textual strings that are designed to guide the model towards generating specific responses. Unlike soft prompts, hard prompts are not learnable parameters and remain unchanged during the fine-tuning process.
Advantages of hard prompt tuning include:
It provides more control over the model's responses, as hard prompts can be designed to elicit specific information or target particular topics.
It can help in creating more focused and consistent outputs, as the prompts explicitly specify the desired behavior.
Hard prompts can be easily understood and crafted by humans, allowing for more intuitive interaction with the model.
In summary, soft prompt tuning uses learnable continuous tokens to guide the model's responses in a more flexible and adaptive manner, whereas hard prompt tuning relies on explicit textual prompts to generate more controlled and targeted outputs. Both techniques have their own advantages and use cases, and their effectiveness depends on the specific goals and requirements of the application.