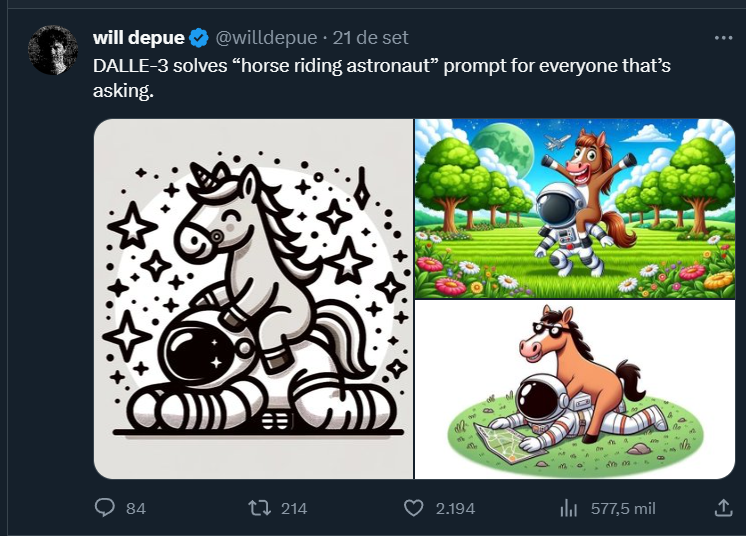
Gary Marcus made a post discussing the Imagen and DALLE-2 model's inability to fully grasp language, particularly around relational undestanding of objects in a prompt: https://garymarcus.substack.com/p/horse-rides-astronaut
OpenAI just released DALLE-3, https://openai.com/dall-e-3, which they claim "represents a leap forward in our ability to generate images that exactly adhere to the text you provide".
Once publicly available, I will run this prompt from DeWeese lab that is discussed heavily in the post:
A red conical block on top of a grey cubic block on top of a blue cylindrical block, with a green cubic block nearby
I will produce 10 images. If 5 or more of the images match the prompt exactly, following the color, shape, and positions specified in the prompt, this market resolves YES. Otherwise, it resolves NO.
I will not bet in this market in case there is ambiguity on some of the images.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ289 | |
| 2 | Ṁ270 | |
| 3 | Ṁ179 | |
| 4 | Ṁ139 | |
| 5 | Ṁ116 |
I got access to DALLE-3 this morning. Here is the test: https://docs.google.com/presentation/d/19rYsDHrg0VdUF2MRMA6hcH07MjfYJLA-Hg_ZPSheB5U/edit#slide=id.g28b799c96e2_0_60

0 out of the first 10 images I generated succeeded in matching the prompt.
@DanMan314 If I understand your screenshots correctly, it looks like you gave ChatGPT the prompt, which presumably gave a different prompt to DALL-E 3, which wouldn't match the wording of the resolution criteria (and, in general, often gives very different results).
EDIT: this was the wrong prompt, whoops!
I drew 7/16 in this comment section: https://manifold.markets/market/will-dalle-3-correctly-respond-to-p-b71709792502
So, if we model it as a bernoulli process, the probability that 5 or more out of 10 are correct is
46%

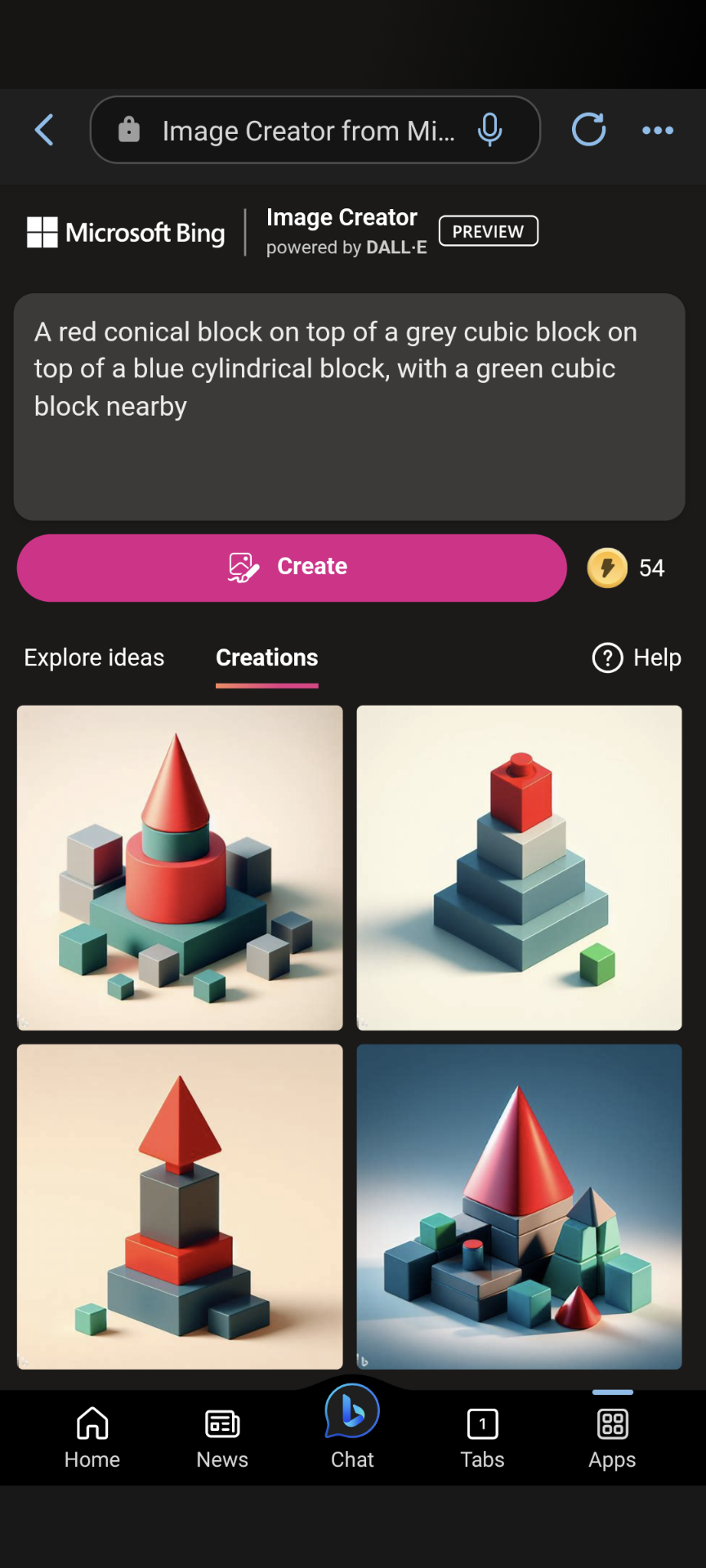
@chrisjbillington not convinced it's DALL-E 3. GPT-4 prompts might be boosting image coherence, but I think Bing Image Generator is still DALL-E 2.
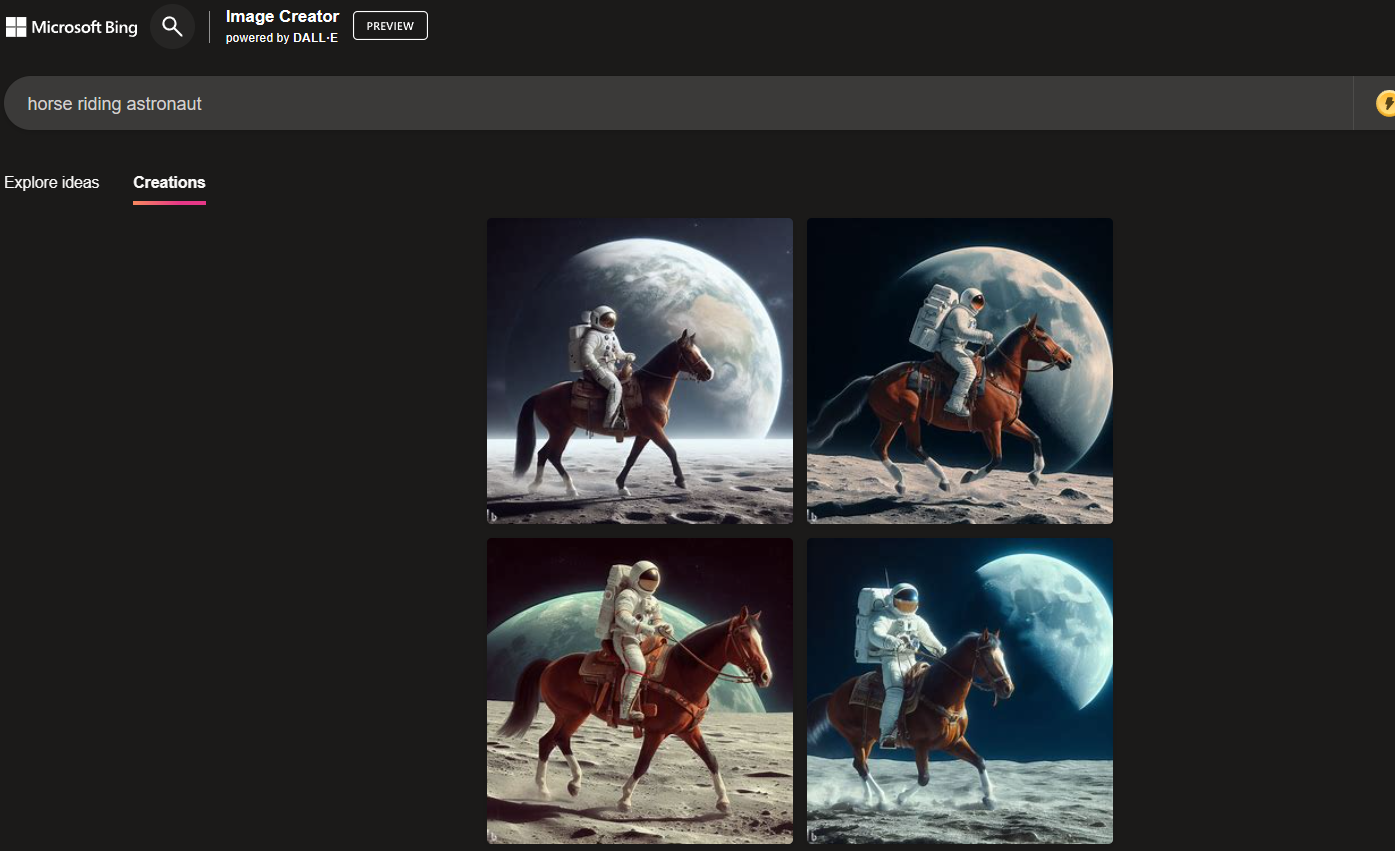
@RaulCavalcante If I understand it correctly, these are probably not the first images you'd get with this prompt, but rather a result of you and gpt4 modifying the prompt to get it right after it failed the first time.
@RaulCavalcante it absolutely is DALL-E 3. There's official information:
https://x.com/MParakhin/status/1707857086615548018?s=20
(Mikhail is the head of Bing Search and Bing Chat at Microsoft)
And it's just much better now at generating anything.
@chrisjbillington I've been playing with bing recently and can confirm it is sub-imagen or whatever the thing the Google was doing, wrt. proper relationships instead of dropping all the keywords on a canvas.