
Will loss curves on Pythia models of different sizes trained on the same data in the same order be similar?
13
Ṁ1kṀ802Apr 29
77%
chance
1H
6H
1D
1W
1M
ALL
Someone in the EleutherAI discord is reporting that finetuning Pythia models of different sizes on the same data in the same order is giving spookily similar loss curves, just vertically shifted.
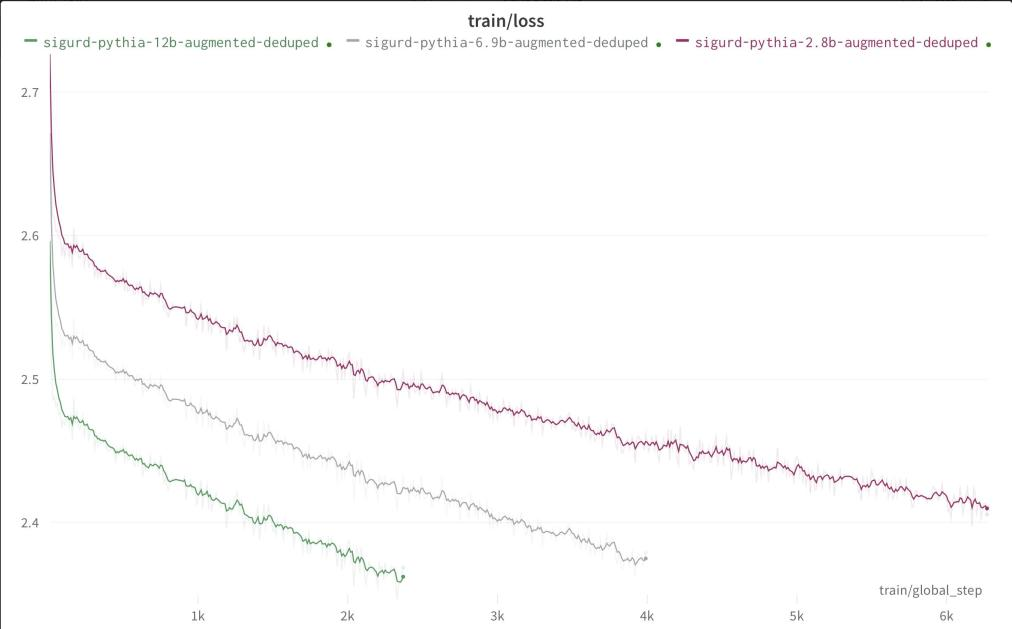
Will training Pythia models from scratch in the same way produce similar behaviour?
Resolves N/A if it turns out the original result was just a bug or something like that.
This question is managed and resolved by Manifold.
Market context
Get  1,000 to start trading!
1,000 to start trading!
1,000Sort by:
Some evidence https://arxiv.org/abs/2305.18411
Won't bet in case it's less obious but for the record mi prediction is like 30%.
Have a vague model about how the behaviour happens because the finetuning is affecting the models in the same way but not something else that lowers the loss significantly.
But I'm very confused and don't really get wtf is happening here tbh.