Let's see if Manifold users can accurately predict how AI models should be trained to save electricity.
I have been writing a 55M parameter stock and cryptocurrency trading model. A test model with only 4M parameters was trained and is already useful in trading. Now, I bought more graphics cards to make use of all the data I have.
The large model is to be trained on 120 million sequences of bars of OHLCV data (about 5TB), with an additional sixth feature ("imputed"), which is 1 if a bar is missing from the data or is an outlier; 0 otherwise.
The number of bars in each sequence is greater than 1000, and the candle time is five minutes or greater. The output is the predicted price several bars in the future. Standard techniques like scaling and Dropout are used. I won't reveal what is at the beginning of the model. Here is the middle and end:
Secret layers at the beginning of the model
Several LSTM layers
The proposed code (or not):
x = LayerNormalization()(x) x = Attention()([x, x]) x = LayerNormalization()(x)One more LSTM layer
Multiple Dense layers
I will train each model for one epoch - about 144 hours total - on three 4090 graphics cards. One run will include the model without the code in black, and the second will include it.
If the model with this code has a lower Huber loss function than the model without it, this market will resolve to YES. If an error occurs during training that cannot be resolved without significantly changing the model architecture, or if training is unable to be completed due to a physical problem like a card failure, the market will resolve to N/A. Otherwise, it will resolve to NO.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ76 | |
| 2 | Ṁ66 | |
| 3 | Ṁ28 | |
| 4 | Ṁ25 | |
| 5 | Ṁ23 |
RESOLUTION: The val_loss for the non-Attention model was 0.0099, while the val_loss for the Attention model was 0.113. The non-Attention model is shown here, and the Attention model is shown in a comment below.

You can see that the loss in the Attention model was 0.0038 and the loss in the non-Attention model was 0.0040.
Therefore, the addition of the Attention layer caused the model to overfit by more than 14%, and as a result, the resolution is NO. Even though I have absolutely no idea why it happened, I'm pleased by this result, as it means that I can omit Attention layers from my future models and get better results with faster training.
@SteveSokolowski I didn't bet on this because I'm not confident you used the attention layer correctly, hence my questions.
def create_lstm_model(input_shape: Tuple[int, int]) -> Model:
#tf.config.optimizer.set_jit(True)
"""
Create an enhanced LSTM model for time-series prediction.
Parameters:
- input_shape (Tuple[int, int]): The shape of the input data (number of timesteps, number of features).
Returns:
- Model: The compiled Keras model.
"""
# Lecun_normal may work better as activation function, even with leakyrelu
leaky_relu_alpha: float = 0.01
l2_lambda_conv: Optional[float] = 0.001 * MODEL_SIZE_FACTOR # Increased due to more data
l2_lambda_dense: Optional[float] = 0.002 * MODEL_SIZE_FACTOR # Increased as suggested
l2_lambda_lstm: Optional[float] = 0.00001 * MODEL_SIZE_FACTOR
activation: str = 'leakyrelu'
# Input layer
inputs = Input(shape=input_shape)
# Convolutional Layers with Pooling
x = conv_block_with_skips(inputs, filters=math.floor(256 * MODEL_SIZE_FACTOR), alpha=leaky_relu_alpha, l2_lambda=l2_lambda_conv, activation=activation, skip=True, dropout_amount=0.3 * math.sqrt(MODEL_SIZE_FACTOR))
x = conv_block_with_skips(x, filters=math.floor(512 * MODEL_SIZE_FACTOR), alpha=leaky_relu_alpha, l2_lambda=l2_lambda_conv, activation=activation, skip=False, dropout_amount=0.3 * math.sqrt(MODEL_SIZE_FACTOR)) # This skip was added and may have caused overfitting. It could also be the data or adaptive dropout.
# LSTM layers
x = lstm_block(x, units=math.floor(512 * MODEL_SIZE_FACTOR), return_sequences=True, alpha=leaky_relu_alpha, l2_lambda=l2_lambda_lstm, bidirectional=True, activation=activation)
# LSTM layer with residual connections
x_shortcut = x
x = lstm_block(x, units=math.floor(512 * MODEL_SIZE_FACTOR), return_sequences=True, alpha=leaky_relu_alpha, l2_lambda=l2_lambda_lstm, bidirectional=True, activation=activation)
x = Add()([x, x_shortcut])
x = LayerNormalization()(x)
x = Attention()([x, x])
x = LayerNormalization()(x)
# LSTM layer after attention
x = lstm_block(x, units=math.floor(512 * MODEL_SIZE_FACTOR), return_sequences=False, alpha=leaky_relu_alpha, l2_lambda=l2_lambda_lstm, bidirectional=False, activation=activation)
x = dropout_block(x, 0.3 * math.sqrt(MODEL_SIZE_FACTOR), activation)
# Fully connected layers (Dense)
x = dense_block(x, units=math.floor(512 * MODEL_SIZE_FACTOR), dropout_amount=0.25 * math.sqrt(MODEL_SIZE_FACTOR), alpha=leaky_relu_alpha, l2_lambda=l2_lambda_dense, activation=activation)
x = dense_block(x, units=math.floor(384 * MODEL_SIZE_FACTOR), dropout_amount=0.2 * math.sqrt(MODEL_SIZE_FACTOR), alpha=leaky_relu_alpha, l2_lambda=l2_lambda_dense, activation=activation)
x = dense_block(x, units=math.floor(256 * MODEL_SIZE_FACTOR), dropout_amount=0.15 * math.sqrt(MODEL_SIZE_FACTOR), alpha=leaky_relu_alpha, l2_lambda=l2_lambda_dense, activation=activation)
# Output layer
out_close = Dense(1, name='out_close')(x)
# Create and compile the model
model: Model = Model(inputs=inputs, outputs=out_close)
# Then use it in your model
model.compile(
optimizer=Adam(learning_rate=0.0003 / MODEL_SIZE_FACTOR),
loss='huber',
metrics=['mae', 'mse',
MeanAbsolutePercentageError(name='mape'),
BiasMetric()]
)
return model@SteveSokolowski At a glance, that's not causal attention, and doesn't use any positional encoding. Both of those factors may matter for a small time series model. I also don't see residual connections. Also looks like the Keras Attention layer doesn't do QKV or output projection for you. For a better model of adding attention to an LSTM, consider referencing the SHA-RNN paper, which is one of the best performing LSTM architectures at next token prediction.
@aegis I will have to discuss with my partners whether they would agree to that or not. I'll get back to you in 12 hours.
@aegis I will create a new market and discuss this model and others there. As you can see with the resolution, I don't plan to continue with this model. Keep an eye out for my markets and the next one will be whether I can improve upon the original architecture, which I'll include, in a different way.
The training of the Attention version of the model has completed. The results were a val_loss of 0.0113.
Most surprising was that the loss significantly differs from the val_loss in this architecture. However, the val_loss did not differ by this much in the small version of the model. The small version had the exact same number of layers and layer types, but multiplied the size of each layer by 0.25.
I'll leave it to bettors to evaluate whether the increased size of the model resulted in such a poor val_loss, or whether the Attention layer did, and I'll begin training the other version now.

Here's some data for people to use in their bets. I started training the attention version first. As you can see, it's about half finished.
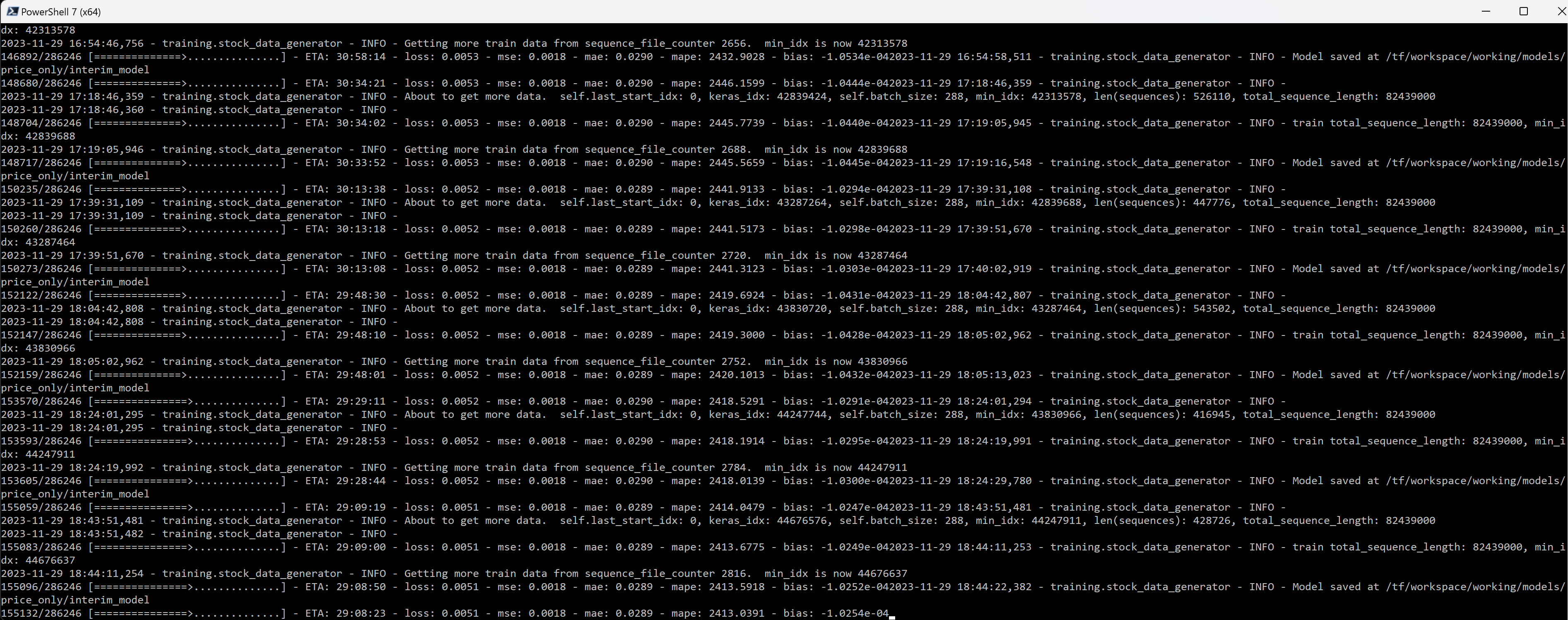
The way to make money trading with the model is to buy stocks when they are predicted to be multiple times the mae above the current price.
The mape is not reliable; because the scaling is between 0 and 1, an actual value of 0.000001 that is predicted as 0.001 would cause mape to be far off even though the error isn't significant.
It will be interesting to see if this progress so far changes anyone's mind.
@NoaNabeshima Residuals are important! Also I have it cached that layernorm on the residual stream is bad.
@NoaNabeshima This is interesting. Everywhere I've seen, it suggests that normalization should be done both before and after the Attention layers.
GPT-4, when shown the layers before and after, also suggests two LayerNormalization()s. Why would that be?
This model doesn't use skip connections often, because the layers have different sizes, and I don't own enough graphics cards to increase the layers to be the same size so I can use them.
@SteveSokolowski Where have you seen layernorm before and after attention? (curious, and also trying to get more context). I haven't seen that before. You can use a skip connection on the attention layer at least.
@SteveSokolowski I'm also surprised that you can't make the layers the same size with 4090s. Are you using really large batches?
@NoaNabeshima It's the amount of data that's the problem. I have so much data that the model needs to be big enough to fit it all, but not so big that the GPUs can't compute it. In fact, that might be why I never get past two epochs, because there's so much data it doesn't help to put the same data through again.
So the layers increase in size as the network gets deeper, because I found that the size of the last LSTM layer was most important and I need to sacrifice somewhere.
The batch_size is 1280 for the small model and 284 for the large model that's training now.
@SteveSokolowski How does the model dimension increase in the model? What is your.. I think it's called something like FLOPS utilization?
I think people switched to transformers over LSTMs partially because they trained more efficiently (because operations are parallelizable as compared to LSTM's sequential operations per sequence index). I'd guess you'd train faster with a stack of attention layers and mlps.
I think you can do a residual stream with increasing size just by using slicing to add the smaller input tensor to a slice of the output tensor, as long as the sequence dimension stays the same length. I've never personally tested this but I think it would help with high prob.
@NoaNabeshima I never even considered getting rid of the LSTM layers completely.
I tried MultiHeadAttention layers, but they cause the model to diverge after just a few minutes of training, so I went back to the proposed code for the large training run.
Are you suggesting to just get rid of every LSTM layer and then use alternating self-Attention and Dense layers? And then, I guess I would also get rid of the Dense layers at the end, too.
@NoaNabeshima Yeah! You could leave dense in if desired I'm imagining. Sorry for unsolicited advice, you have a lot more context than me.
Everywhere I've seen, it suggests that normalization should be done both before and after the Attention layers.
I think you want to do normalization when reading from or writing to the residual stream, because usually you have residual stream -> attention -> MLP -> residual stream
@firstuserhere related: https://arxiv.org/pdf/2002.04745.pdf
This is probably part of why I have it cached that layernorm on residual stream is bad. GPT2 and Llama-2 use prenorm instead of postnorm.
https://github.com/openai/gpt-2/blob/a74da5d99abaaba920de8131d64da2862a8f213b/src/model.py#L123
@firstuserhere I think you don't need normalization writing to res stream.
also
res stream -> attn -> res stream -> mlp -> res stream
is normal instead I think