
NOTE, YE 2023 signifies, "Before the end of the year 2023" which means, evidence must be posted in the comments with a timestamp prior to the end of 2023 CST.
Prompt with current result below:
Create a house in OpenScad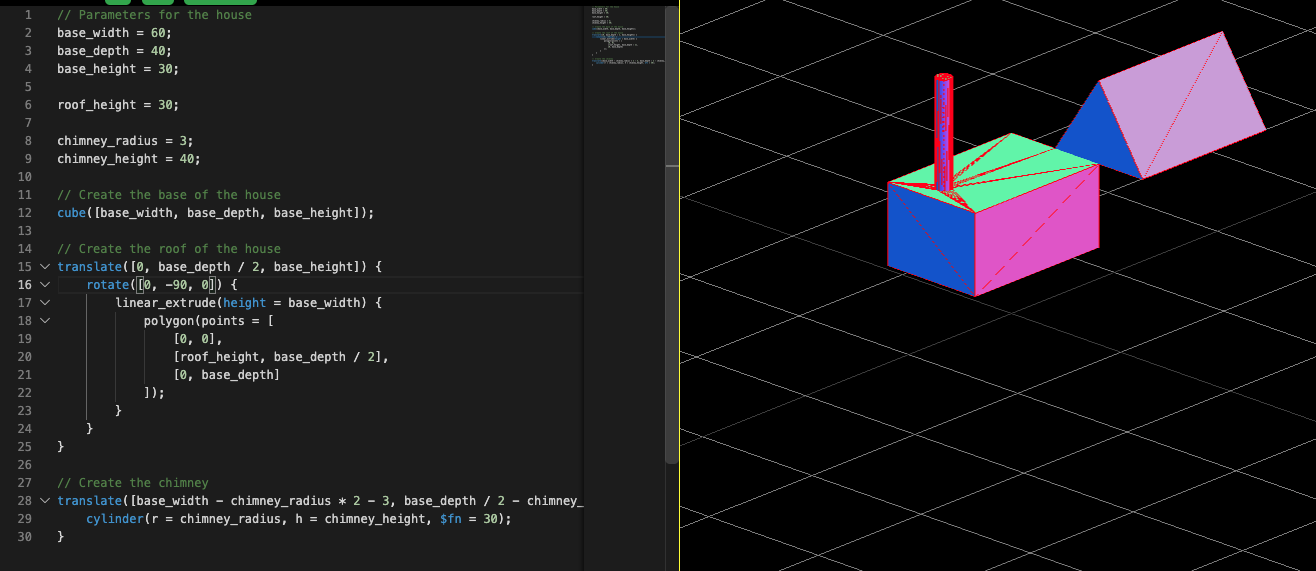
If the roof can be properly connected to the house upon a one-shot prompt, this resolves as YES, otherwise NO.
Other, "Breaking LLM's Markets"
20230912 - changed title for clarity.
20230912 - One shot is defined as meaning instructions cannot be embedded within a single chat. In other words, the example given above is a one shot prompt, whereas a multishot prompt could be entered into the prompt in one go, but have a multi-shot prompting strategy embedded within it, asking the LLM to go step by step, listing out every single step necessary to build a house. No, this needs to be something like, "build a house in OpenSCAD," or, "be super simple and build a house with OpenSCAD"... it generally needs to just have one step involved in the prompt.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ666 | |
| 2 | Ṁ203 | |
| 3 | Ṁ39 | |
| 4 | Ṁ28 | |
| 5 | Ṁ27 |
People are also trading
I was convinced by this argument: https://manifold.markets/PatrickDelaney/will-chatgpt-utilizing-the-gpt4-mod#XfhIzxNwwdkU0P1t69QU ... did some testing myself, it seems to work.

Hello,
I saw that you updated the market description with your own definition of what a one-shot and multi-shot prompt should be. Have you had the chance to read my responses about the usage of these terms? If so, why didn't you find them convincing enough to update your definition?
Let's assume, for the sake of a fun exercise, that, for you, this market was not about finding any one-shot or even zero-shot prompt, but that we should take your own definition as a given. So, the prompt should not only contain no examples of the task but also no mention of "(Let's) think/go step by step" nor explicit steps to follow. In short, only a single, preferably short, action/step to perform should appear in the prompt.
I first tried "Plan a house model in OpenScad". This worked perfectly 5 times in a row (I evaluated the output according to the proposed success criteria, i.e. a properly connected roof) using the code interpreter mode (I just happened to be on the code interpreter by mistake):
https://chat.openai.com/share/aafd61c6-de76-45e0-b22d-bb3ac7f9f88a -> SUCCESS
https://chat.openai.com/share/984e1597-3a8d-4eb8-860a-db16af6c119e -> SUCCESS
https://chat.openai.com/share/ae72442f-d411-4e9f-8d61-88cb4119d69b -> SUCCESS
https://chat.openai.com/share/0624f978-736f-4bb5-9c29-977b9112f23e -> SUCCESS
https://chat.openai.com/share/6ad24d89-bec8-4768-a36c-50ccff0b0024 -> SUCCESS
With the same prompt, when switching to the default GPT-4 mode, while, technically, it still worked, the success rate was lower:
https://chat.openai.com/share/855735be-af2b-4e75-a55d-d267e9d9e083 -> SUCCESS
https://chat.openai.com/share/018d9b27-e8b5-4906-9094-da4416edfe82 -> FAIL
https://chat.openai.com/share/3e067ea0-2e32-4527-a353-2a651022377b -> SUCCESS
https://chat.openai.com/share/fd0979c8-4179-4e6f-bb9f-539b67b2c218 -> FAIL
https://chat.openai.com/share/dbe14ed6-323b-4707-ba32-7d8a54112e4b -> FAIL
I've noticed that, compared to GPT-4 with code interpreter, the default GPT-4 mode tends to be "lazier" in order to keep answers brief. So, I tried variations of the prompt "Plan a simple house model in OpenScad, do NOT try to be concise in your answer". The addition is clearly not a new task, but a description of the desired writing style, similar to "be super simple" in your example. This worked considerably better.
https://chat.openai.com/share/53f931f4-c6e4-4ffa-a9a7-2833a8b5375e -> SUCCESS
https://chat.openai.com/share/e69f1753-5b10-4948-b4b0-4872c9a1c096 -> SUCCESS
https://chat.openai.com/share/20ae87e8-00ae-4ea3-8679-28fc55ef3865 -> SUCCESS
https://chat.openai.com/share/0380830f-8445-4b1e-8413-c3222c0ee92d -> FAIL? (The roof is connected, but its shape is wrong)
https://chat.openai.com/share/bc318901-f06d-490c-aeee-ec103fd0a49a -> SUCCESS
https://chat.openai.com/share/52811b2a-1e1e-46c2-82a4-c0d14897854e -> SUCCESS
I also tried with the word "draw" instead of "plan" in case that wouldn't fit a criterion for some reason. Here are my tests on the default GPT-4 using the prompt "Draw a very simple house model in OpenScad, do NOT try to be concise in your answer":
https://chat.openai.com/share/37dfc254-d46f-4c88-8e67-6cda5acb809f -> SUCCESS
https://chat.openai.com/share/06583500-06a3-4a1f-b64c-fc9433e3be98 -> SUCCESS
https://chat.openai.com/share/37437739-85ea-4033-b17d-245b75ee6b5c -> SUCCESS
https://chat.openai.com/share/0b89190a-0e2c-4ed5-a55f-e907afaf10cc -> FAIL? (The roof is connected, but it's a cube roof)
https://chat.openai.com/share/73c2918a-854b-4776-8f49-e9c3731876c0 -> SUCCESS
In summary, I think that the linked examples, e.g., the prompts "Plan a house model in OpenScad" for GPT-4 with code interpreter or "Plan a very simple house model in OpenScad, do NOT try to be concise in your answer" for the default GPT-4 fit your interpretation of the word "one-shot" and can make GPT-4 produce coherent house models. Yes, ChatGPT is stochastic, and the true success rate will probably never be 100%, but I think that anyone in good faith should be able to get GPT-4 to draw a house in OpenScad using these prompts.

@JamesGrugett I'm happy to keep it as is, I just would like, "some kind," of embed to key people off into other types of similar markets. I am not sure that a fully embedded description really gets people to click on those other markets as much as the title. Thanks.
Just throwing out there - the title (and also description, though less so) of this market makes me think that this is about the capabilities of ChatGPT changing in response to a fixed prompt. Rather than what this market seems to be in the comments, which is a prompt engineering exercise. I think the title would be better as "Will a prompt be found..." rather than "Will ChatGPT...".
@Weepinbell Would you be open to, "Will a one-shot prompt be found within ChatGPT Utilizing the GPT-4 Model Be Able To Properly Render a House By End of 2023?" .. I can try to more clearly define one-shot in the description as well.
Here is what I found when attempting this exercise today. Please correct my rendering if any of these were wrong. I did not use Chain of Thought, COT but rather directly what I had written in the resolution criteria in the description.
With Code Interpreter
Result rendered in OpenScad, pentagonal roof interestingly, but roof still not centered:
module house() {
difference() {
cube([20, 20, 15]); // main building
translate([5,5,-1]) cube([10,10,17]); // door
translate([2,2,10]) cube([3,3,3]); // window left
translate([15,2,10]) cube([3,3,3]); // window right
}
roof();
}
module roof() {
translate([-1,-1,15])
scale([22,22,10])
rotate([0,0,45])
cylinder(r1 = 0.7, r2 = 0, h = 1);
}
house();
Default GPT4
Conical roof, not centered, not even at level of roof.
module house() {
// Main body of the house
cube([10, 10, 15]);
// Roof of the house
translate([0, 0, 15])
rotate([0, 180, 0])
scale([1, 1, 0.6])
cylinder(r1=0, r2=10, h=15);
}
house();
GPT 3.5
// House dimensions
house_width = 30;
house_depth = 40;
house_height = 20;
roof_height = 10;
// Create base of the house
module house_base() {
difference() {
cube([house_width, house_depth, house_height]);
translate([5, 5, 0]) cube([house_width - 10, house_depth - 10, house_height]);
}
}
// Create roof of the house
module house_roof() {
translate([0, 0, house_height]) {
difference() {
cube([house_width + 10, house_depth + 10, roof_height]);
translate([-5, -5, 0]) cube([house_width + 20, house_depth + 20, roof_height]);
}
}
}
// Combine base and roof to create the house
module house() {
union() {
house_base();
house_roof();
}
}
// Render the house
house();No roof. It evidently appeared to create a roof but the union function didn't make it appear.

@PatrickDelaney Using:
I would like you to follow these steps. Do not worry about the conciseness of your response, please write everything out in detail.
1. Imagine how you could represent a minimalistic house with a roof and a chimney using only simple 3d shapes
2. Imagine how you could create this model in OpenScad. Plan out the necessary shapes and transformations in detail.
3. Implement your design in OpenScad, write the full code
4. Explain your implementation (the shapes you created, the transformations you applied) focus on finding any potential mistakes or oversights. Be as critical as possible, but only make changes if you really spot mistakes. The house has to be a very simple but fully accurate model.
5. Reimplement a corrected version of your design in OpenScad, write the full codeGPT 3.5 Output:
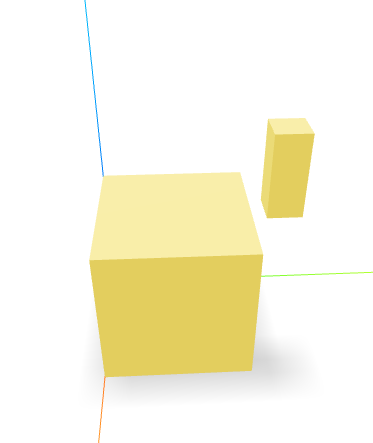
GPT 4 Default Output:
Intermediate Step:

Final Step:
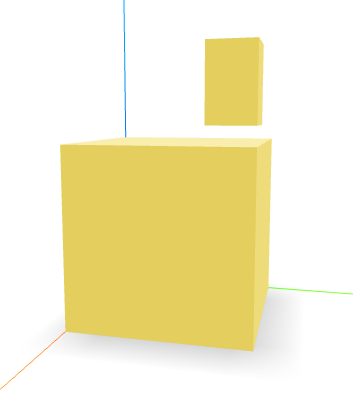
GPT 4 With Code Interpreter Output

@PatrickDelaney I don't think the chimney is required. The only thing I'm not clear on is whether a Zero Shot question which includes a Chain of Thought classifies as a Zero Shot question...?
A few examples in the prompt = few-shot
No examples in the prompt = zero-shot
That's also how the terms are used in papers about CoT prompting.
@JonasVollmer I would say no based upon my past read of papers referring to the definition of few-shot vs zero-shot. If you have any clear evidence contridicting this definition, please link.
@PatrickDelaney I'm still not sure why the example below by @3721126 doesn't fit the criteria. Surely this resolves yes?
@Tomoffer Thanks for your question. So basically a "Zero Shot" or "One Shot" question in the context of an LLM means, you ask it a simple, one-off question like, "model a house," and it gives a result without mistakes. This is different than, "hey let's do this step by step, 1. build a box 2. build a triangle 3. build a larger box, etc." That would be called, "multi-shot." So even though technically the user above put the query in as one block of text, it was still multi-shot, because each, "step" represents a shot. Prompts that involve, "hey let's do this step by step," are still considered multi-shot, from the best of what I can find out right now. Again, I'm open to hearing arguments on this if I am wrong. I am basing this off of my memory of various papers I have read over time. This is open to being disproven if there is a consensus of high-level experts who have a more precise, better definition.

The definition of zero-shot or few-shot does not change when talking about CoT prompts: it is only about whether examples of the task being performed are included in the prompt, even if the task itself is more complex.
I would say that the modern usage of these terms has really been cemented with the GPT-3 introduction paper (Brown, Tom B., et al. Language Models Are Few-Shot Learners. arXiv, 22 July 2020. arXiv.org, https://doi.org/10.48550/arXiv.2005.14165.), before that, the term zero-shot was sometimes used in an even less restrictive way (equivalent to the modern few-shot). Here's the footnote on page 4 of the paper:
"In the context of language models this has sometimes been called “zero-shot transfer”, but this term is potentially ambiguous: the method is “zero-shot” in the sense that no gradient updates are performed, but it often involves providing inference-time demonstrations to the model, so is not truly learning from zero examples. To avoid this confusion, we use the term “meta-learning” to capture the inner-loop / outer-loop structure of the general method, and the term “in context-learning” to refer to the inner loop of meta-learning. We further specialize the description to “zero shot”, “one-shot”, or “few-shot” depending on how many demonstrations are provided at inference time. These terms are intended to remain agnostic on the question of whether the model learns new tasks from scratch at inference time or simply recognizes patterns seen during training – this is an important issue which we discuss later in the paper, but “meta-learning” is intended to encompass both possibilities, and simply describes the inner-outer loop structure."
Also from the paper:
"(a) “few-shot learning”, or in-context learning where we allow as many demonstrations as will fit into the model’s context window (typically 10 to 100), (b) “one-shot learning”, where we allow only one demonstration, and (c) “zero-shot” learning, where no demonstrations are allowed and only an instruction in natural language is given to the model."
This is the usage of these terms I have seen in any other paper since. My prompt was nothing more than zero-shot on a more detailed task that borrowed some ideas from CoT. On the other hand, a few-shot CoT prompt would look more like this:
"Draw a tree in OpenSCAD, think step-by-step:
Hand crafted example that leads to a tree being draw in OpenSCAD
Draw a car in OpenSCAD, think step-by-step:
Hand crafted example that leads to a car being draw in OpenSCAD
Draw a dog in OpenSCAD, think step-by-step:
Hand crafted example that leads to a dog being draw in OpenSCAD
Draw a house in OpenSCAD, think step-by-step:"
(With or without the "think step-by-step" in the instructions, only the demonstrations/examples in the prompt make a difference.)
Instructing the model to perform a more intricate task like CoT or giving additional instructions does not mean that it suddenly becomes a few-shot prompt. You can, for further confirmation, refer to the seminal paper on CoT prompting (Wei, Jason, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv, 10 Jan. 2023. arXiv.org, https://doi.org/10.48550/arXiv.2201.11903.), that focuses mostly on few-shot prompting, and compare it to the "Let's think step-by-step" paper (Kojima, Takeshi, et al. Large Language Models Are Zero-Shot Reasoners. arXiv, 29 Jan. 2023. arXiv.org, https://doi.org/10.48550/arXiv.2205.11916.) that showcases zero-shot CoT. For that second paper, you can just take a look at the abstract to get a sense of how the terms are employed in this context. Figure 1 from the paper is also quite clear:

To go even further, one can note that this exact same definition of zero-shot and few-shot remains consistent across papers utilizing much more advanced multistep techniques such as self-critique (Saunders, William, et al. Self-Critiquing Models for Assisting Human Evaluators. arXiv, 13 June 2022. arXiv.org, https://doi.org/10.48550/arXiv.2206.05802.) or Tree of Thoughts (Yao, Shunyu, et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv, 17 May 2023. arXiv.org, https://doi.org/10.48550/arXiv.2305.10601.). These are just some examples, as this is just how these terms are being used in an overwhelming share of the current discourse in the field, to the extent that no recent counterexamples come to mind here. It's even arguable that model-generated examples/synthetic data formatted in the style of a few-shot prompt would still be described as a zero-shot approach.
To get unnecessarily tongue-in-cheek, I could even point out that the description mentions a "one-shot prompt". Therefore, showcasing that GPT-4 can draw a house after being shown in great detail how to draw an object with a roof that isn't a house (for inspiration: https://chat.openai.com/share/631118b5-c0ae-4add-8b21-ec15b197efe5) would technically fit the bill. However, I assumed that this wasn't what you had in mind.
I think this should be resolved to yes:
https://chat.openai.com/share/976a04ec-538b-4506-939e-2b97e2f617bf
The self-critique steps weren't even necessary here, but might improve robustness.
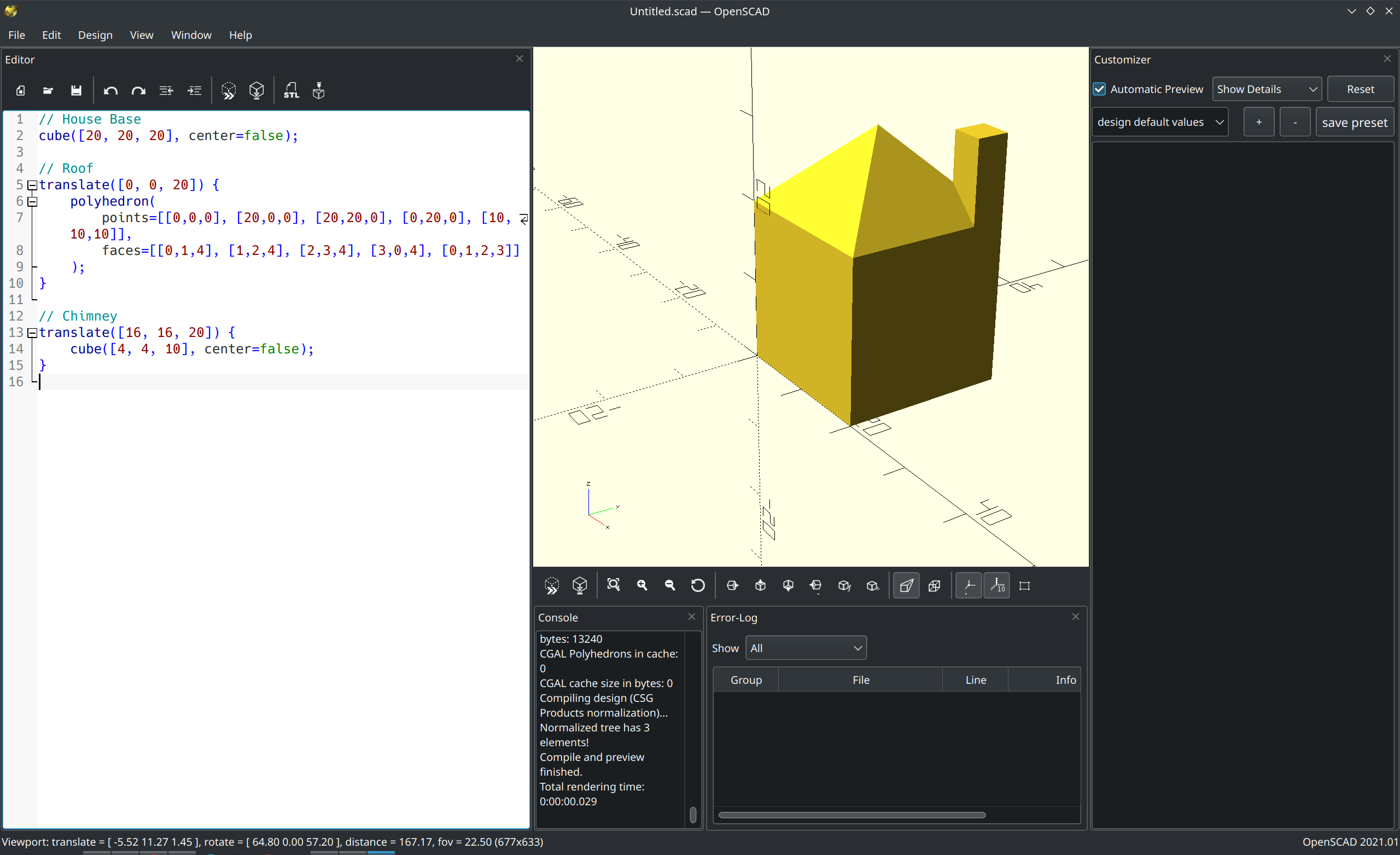
Well it seems to be able to get more difficult things to work: