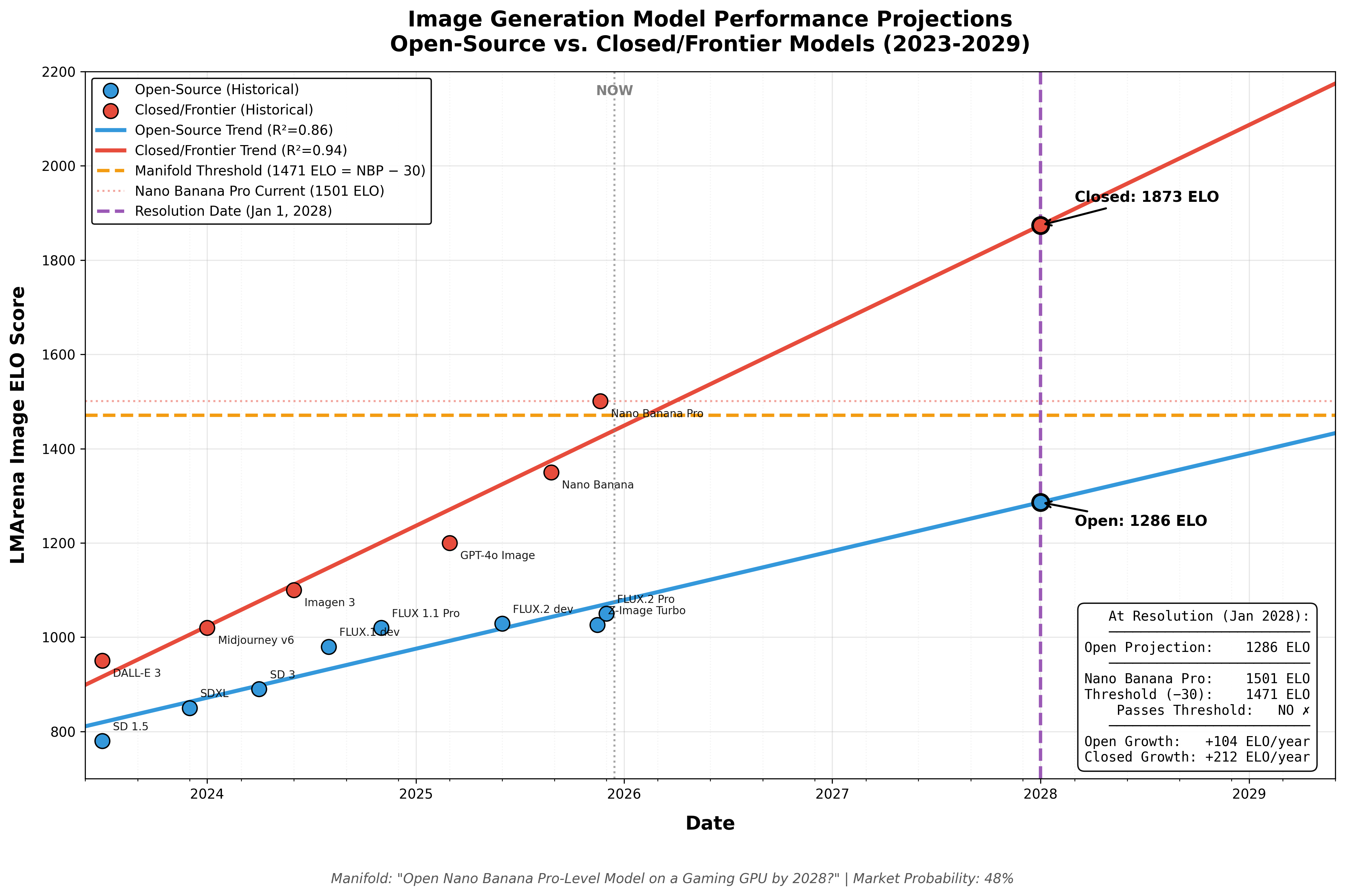
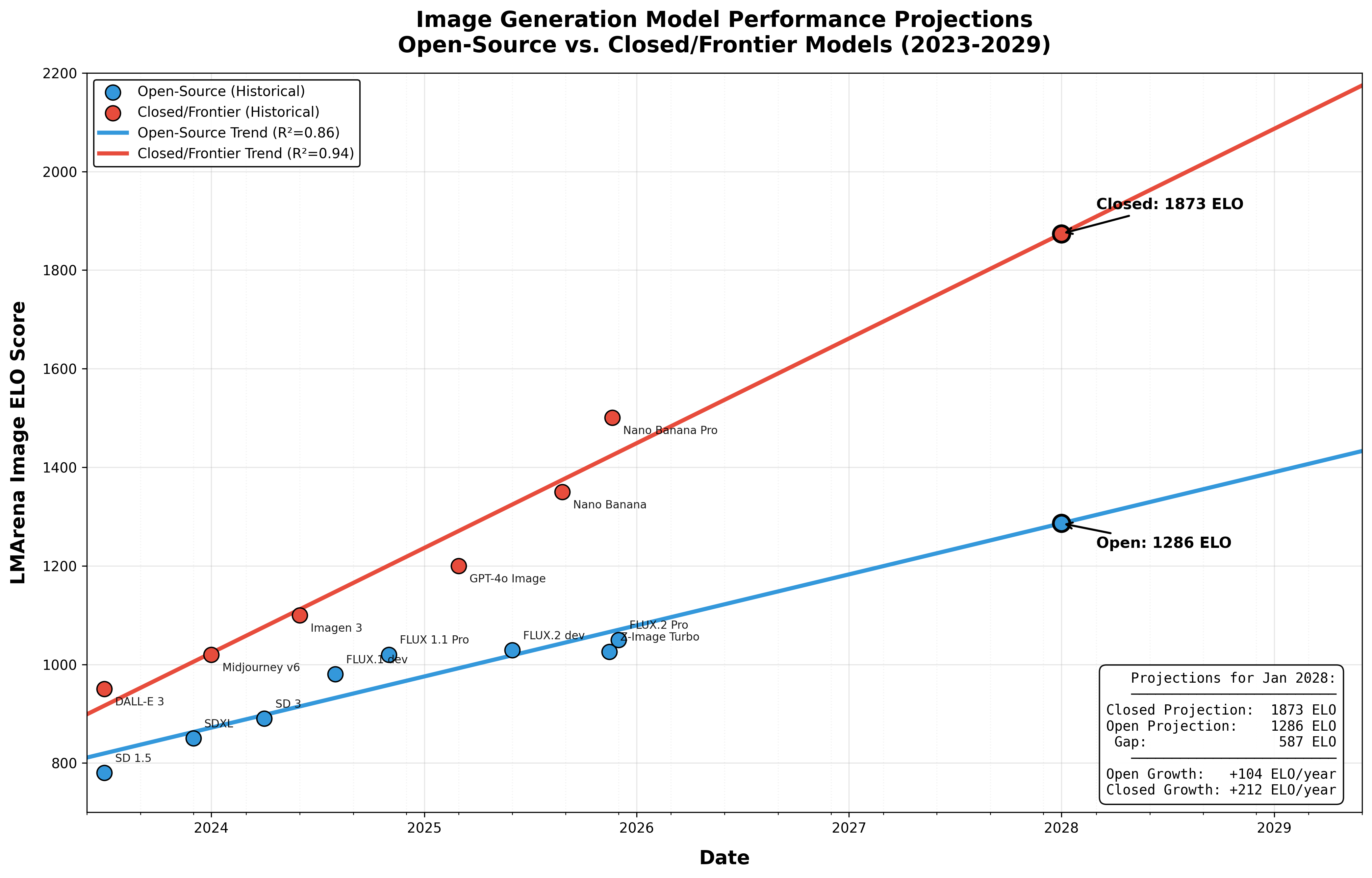
Resolves as YES if there is strong evidence that, before January 1st 2028, at least one publicly released open‑weights model that can run on a single consumer GPU has capabilities comparable to Google’s Nano Banana Pro (Gemini 3 Pro Image), in the sense that it meets all of the base conditions and at least 3 of the 5 capability criteria below (with at least one of criteria D or E satisfied). Otherwise this market resolves NO.
Base conditions (all must be true for the candidate model)
For this market, a candidate model is any concrete model (including its required VAE / text encoder / diffusion backbone / LoRAs) that satisfies all of:
Open weights
The full weights needed for inference are publicly downloadable (behind at most a simple login and click‑through license), without per‑applicant approval or NDAs.
The license explicitly allows local inference by individuals for at least research or personal use. (Commercial use is allowed but not required.)
Consumer‑GPU runnable
There is a public, reproducible demonstration (e.g., GitHub repo, blog post, or well‑documented forum write‑up) of the model running entirely locally (no remote API calls) on:
either a single consumer‑class GPU with ≤24 GB VRAM (e.g., NVIDIA GeForce RTX 4080/4090/50‑series, AMD RX 7900/8900, or similar),
or a consumer Apple device with an M‑series chip and ≤64 GB unified memory.
Quantization (e.g., 4‑bit/8‑bit) is allowed. Very slow inference is acceptable as long as it’s practically usable (e.g., single images or edits complete in well under a few minutes, not days).
Full image pipeline
The model supports both text‑to‑image generation and image editing (e.g., in‑painting / out‑painting / local edits) in a single, locally runnable pipeline. Using separate but jointly released components (e.g., one checkpoint for generation, one for editing) is fine as long as all weights are open and runnable on the same consumer‑hardware class.
Nano Banana Pro reference
Comparisons in the criteria below treat Google’s “Gemini 3 Pro Image / Nano Banana Pro” (or obvious leaderboard aliases such as
gemini-3-pro-image-preview (nano-banana-pro)) as the reference closed model.
If no model fulfills all base conditions by the close date, the market resolves NO regardless of benchmark scores.
Capability criteria – “3 of the following 5 must be true”
A candidate model that passes the base conditions contributes towards a YES resolution if at least 3 of the 5 criteria below are satisfied, and at least one of D or E is among the satisfied criteria.
For all arena‑style criteria, it is enough that the condition holds at any time before January 1st 2028 (e.g., on any snapshot of the leaderboard).
A. LMArena Text‑to‑Image parity
On LMArena’s Text‑to‑Image Arena (or a direct successor clearly billed as the same crowd‑voting leaderboard for text‑to‑image models):
At some point before the deadline, the candidate model and Nano Banana Pro (or alias) both appear with scores on the same leaderboard; and
The candidate’s Arena score is no more than 30 Elo lower than Nano Banana Pro’s score or the candidate outranks Nano Banana Pro on that leaderboard.
If LMArena still operates a Text‑to‑Image Arena but Nano Banana Pro has been fully removed and no archived score can be reasonably recovered, this criterion is considered not satisfied for all models (it does not automatically count as passed).
B. LMArena Image Edit parity
On LMArena’s Image Edit Arena (or direct successor that compares models on image editing / in‑place generation):
At some point before the deadline, the candidate and Nano Banana Pro both appear; and
The candidate’s Arena score is no more than 30 Elo lower than Nano Banana Pro’s score or the candidate outranks Nano Banana Pro.
Same fallback rule as A if Nano Banana Pro’s scores completely disappear with no reasonably accessible archive.
C. Independent Image Arena parity (Artificial Analysis)
On Artificial Analysis’ Image Arena (or a direct successor clearly described as a crowdsourced text‑to‑image model ranking with Elo‑style scores):
This criterion is satisfied if either:
C1 (direct comparison): Nano Banana Pro or Gemini 3 Pro Image is listed, and the candidate’s Image‑Arena Elo is no more than 30 points lower than that Nano‑Banana/ Gemini‑Image entry, or the candidate outranks it;
or
C2 (SOTA open‑weights performance): Nano Banana Pro / Gemini 3 Pro Image is not listed, but at some point before the deadline the candidate model is:
within the top 3 models overall on the Image Arena quality leaderboard, and
the highest‑ranked open‑weights model on that leaderboard at that time.
If Artificial Analysis retires the Image Arena completely and no clear successor exists, this criterion is treated as not satisfied (it cannot be used towards the “3 of 5”).
D. General multimodal / language strength (arena‑style)
This criterion captures the idea that the text / reasoning backbone behind the open model is roughly in the same tier as Gemini 3 Pro on broad chat / coding / multimodal text tasks.
Let “paired backbone” mean either:
the LLM that is officially released as the text backbone of the candidate image model (e.g., “this model is built on Open‑Weights‑LLM‑X”), or
a widely recommended combination (e.g., “use LLM Y + this image model for multimodal chat”) where both components are open weights.
Criterion D is satisfied if, on any one of LMArena’s Text, Vision, or WebDev leaderboards (or direct successors):
The paired backbone model appears on the leaderboard alongside Gemini 3 Pro (or an obvious alias); and
The paired backbone’s Arena score is no more than 30 Elo lower than Gemini 3 Pro’s score or it outranks Gemini 3 Pro on that leaderboard.
If Gemini 3 Pro is never listed on any of these arenas, or all relevant entries are removed with no reasonable archival record, this criterion is treated as not satisfied.
E. Multimodal understanding / agent performance (static benchmarks)
This criterion ensures the open model is competitive on image‑understanding or multimodal agent benchmarks, not just judged by pretty pictures.
It is satisfied if there exists at least one peer‑reviewed or widely‑used benchmark of the following type, where both Nano Banana Pro / Gemini 3 Pro Image (or their official multimodal agent built on the same stack) and the candidate model (or an agent built entirely from open components, including the candidate image model) are evaluated under comparable settings:
A multimodal understanding benchmark such as MMBench, MMMU, MMMU‑Pro, or a clearly analogous successor that uses images + text and reports an aggregate accuracy or score; or
A multimodal agent benchmark such as VisualWebArena, Windows Agent Arena, WebArena‑style browser benchmarks with a clearly labeled multimodal variant, or a clearly analogous successor that reports task success rates.
The benchmark must provide a single main score per model (e.g., overall accuracy, normalized score, or success rate). Criterion E is satisfied if the open model’s score is at least 95% of the score achieved by Nano Banana Pro / Gemini 3 Pro Image (or their official agent) on the same benchmark and evaluation protocol (e.g., same split, same metric), or exceeds that score.
If no such benchmark ever publishes both a Nano‑Banana‑Pro/Gemini‑Image result and an open‑model result built around the candidate before the deadline, criterion E cannot be satisfied.
What counts as “strong evidence”?
For this market:
“Strong evidence” means clear, public records from benchmark leaderboards, peer‑reviewed papers, official benchmark sites, or widely mirrored archives (e.g., static snapshots, conference artifacts, or well‑documented reproductions).
Vendor marketing claims alone are not enough; there must be numbers or rankings that can be independently checked.
If there is reasonable dispute over whether a borderline case meets a criterion, the intended resolution is whichever side is best supported by the preponderance of public benchmark data, not by private tests.
If at least one open‑weights model meets all base conditions and at least 3 of A–E (with at least one of D or E among them) before January 1st 2028, the market resolves YES. If not, it resolves NO.
 1,000
1,000